
Enhanced Parallel Sine Cosine Algorithm for Constrained and Unconstrained Optimization

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
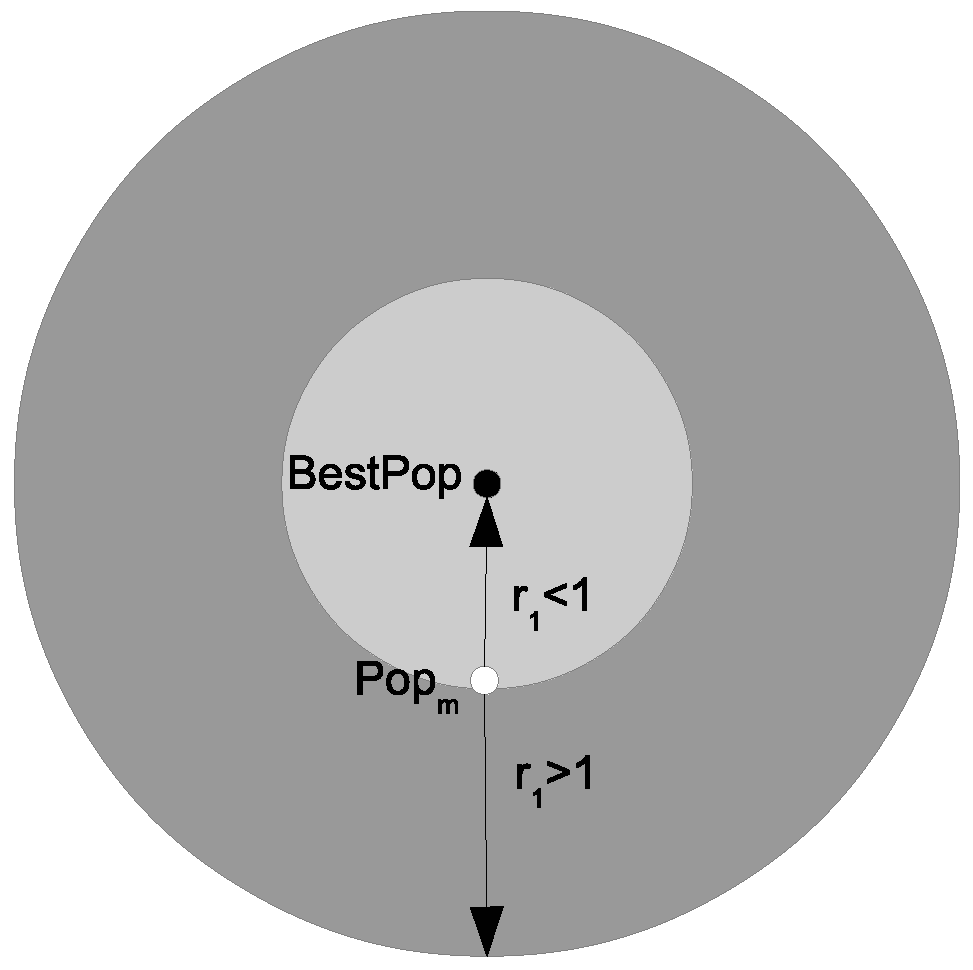
- A new optimization algorithm is proposed, dubbed the Enhanced Sine Cosine Algorithm (ESCA), which improves the SCA algorithm and offers better performance than a set of state-of-the-art algorithms. The outstanding optimization performance of the ESCA algorithm is based on the embedding of a best-guided approach along with the local search capability already existing in the SCA algorithm, leading to a decrease in the diversification behavior at the end of the iterations.
- To improve the computational performance of the proposed algorithm, synchronous and asynchronous parallel algorithms have been designed based on parallelization, initially at an outer, i.e., at a coarse-grained level. Since this level of parallelization is related to subpopulations, the number of subpopulations cannot increase indefinitely. These synchronous and asynchronous one-level parallel ESCA algorithms decrease the computing time by 87.4% and 90.8%, respectively, using 12 processing cores.
- To improve parallel scalability without harming the optimization performance and increasing the number of processes, two-level parallel algorithms have been designed. The parallel strategy includes two levels, namely the outer level and the internal level. The outer level corresponds to coarse-grained parallelization, while the internal level corresponds to fine-grained parallelization. Accordingly, the parallel scalability of the proposed algorithms is extremely improved. The experimental results show significant reductions in the computing time of 91.4%, 93.1%, and 94.5% with 16, 20, and 24 processes mapped on 12 physical cores. These time reductions correspond to speed-ups of , , and with 16, 20, and 24 processes correctly mapped on 12 physical cores, i.e., using hyperthreading.
2. Related Work
2.1. Sine Cosine Algorithm
| Algorithm 1 The SCA optimization algorithm. |
|
2.2. SCA-Based Proposals
3. Proposed Work
3.1. Enhanced Sine Cosine Algorithm
| Algorithm 2 Enhanced SCA (ESCA) optimization algorithm |
|
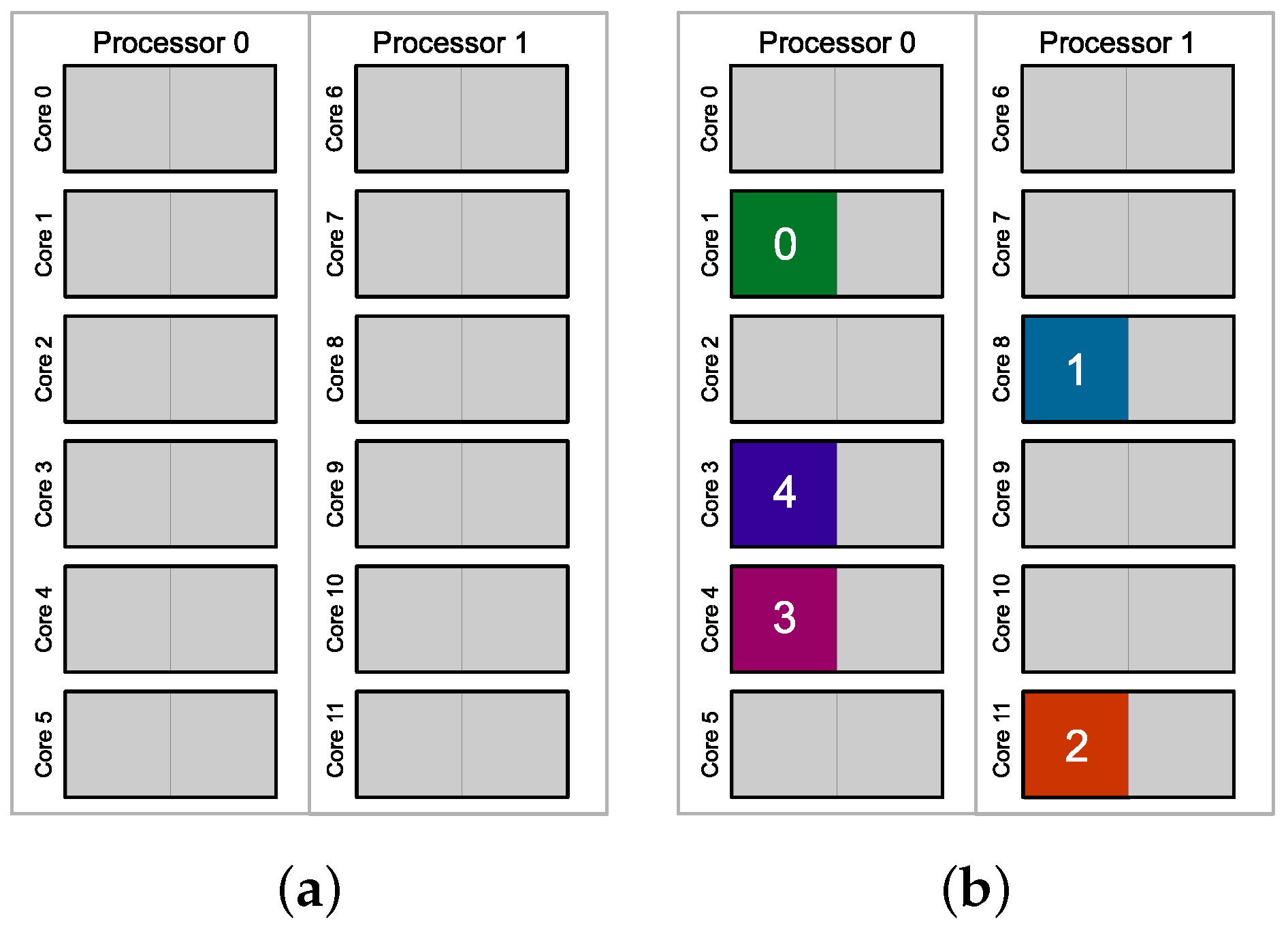
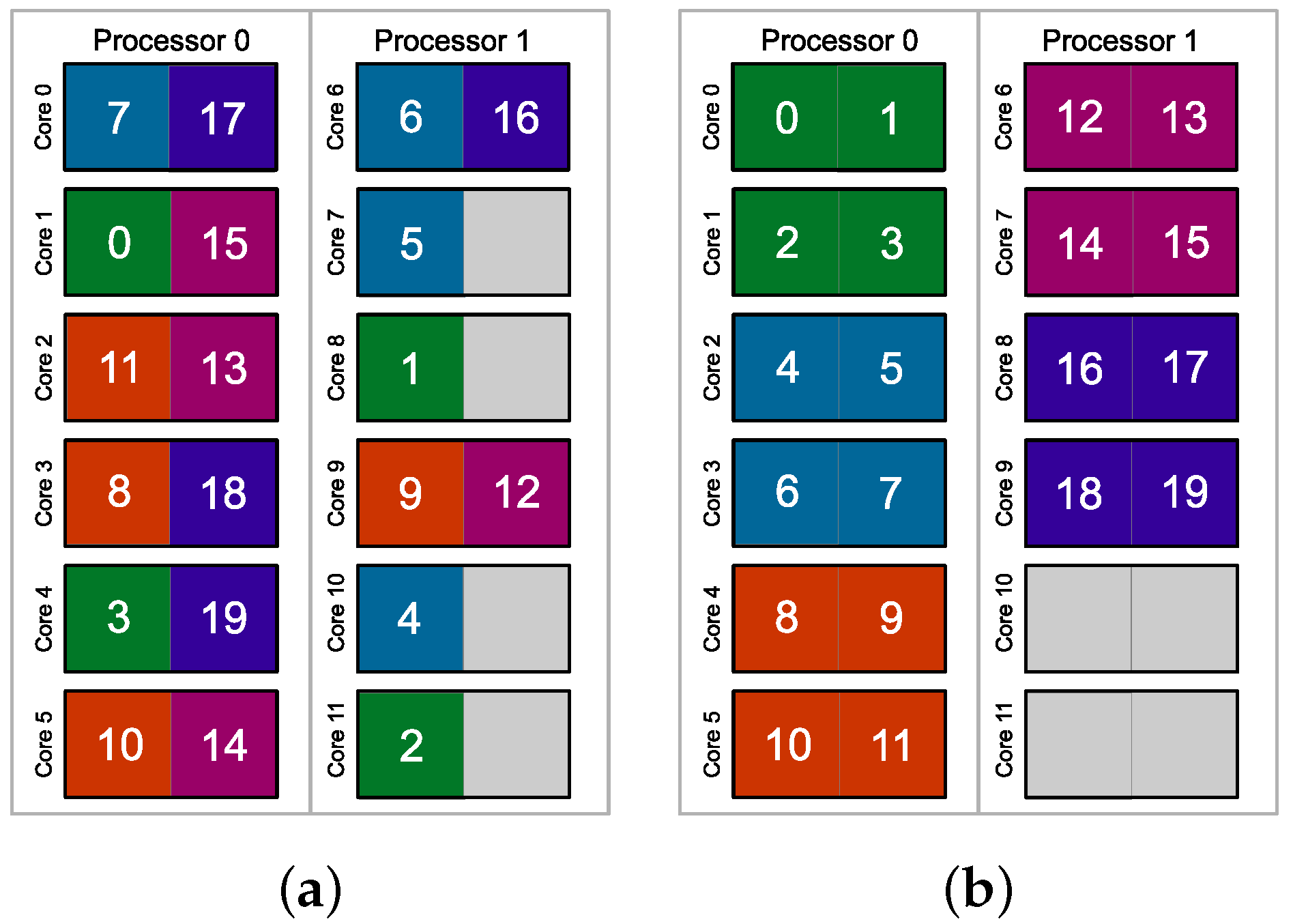
3.2. Proposed Parallel Algorithms
| Algorithm 3 Multi-population sizes computing |
|
| Algorithm 4 Asynchronous parallel algorithm. |
|
| Algorithm 5 Parallel algorithm with data sharing. |
|
| Algorithm 6 Two-level parallel algorithm. |
|
4. Benchmark Test
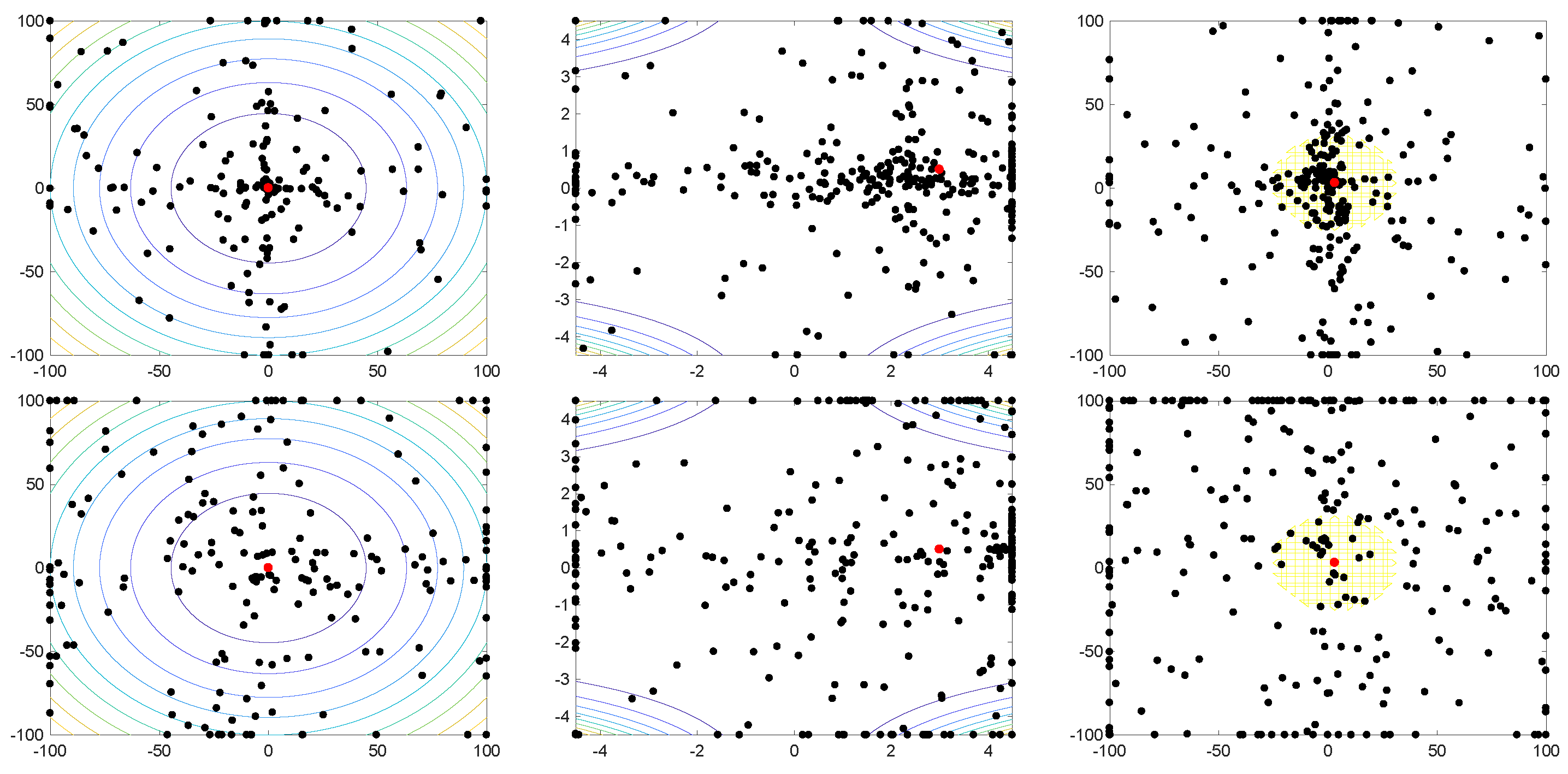
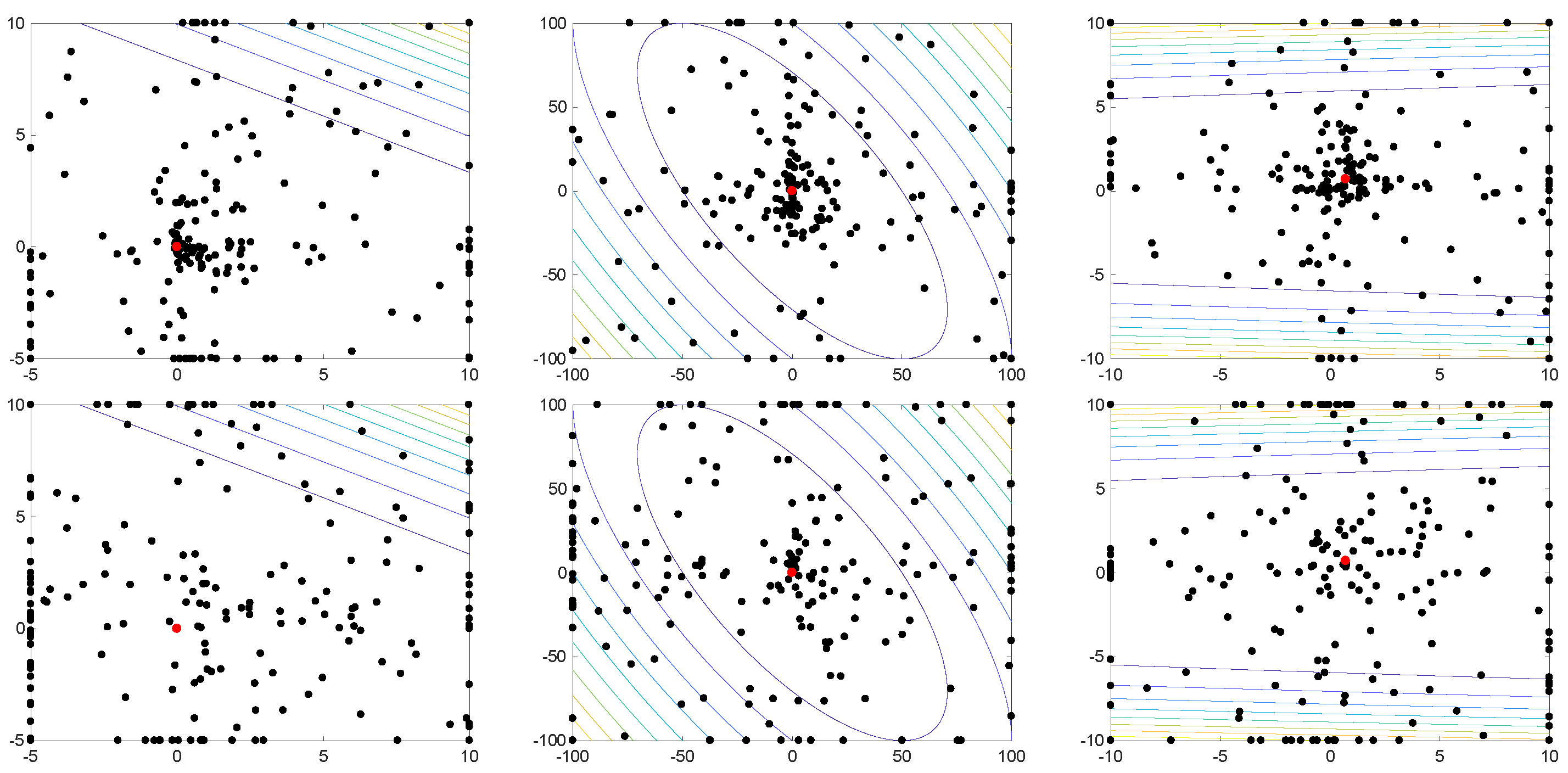
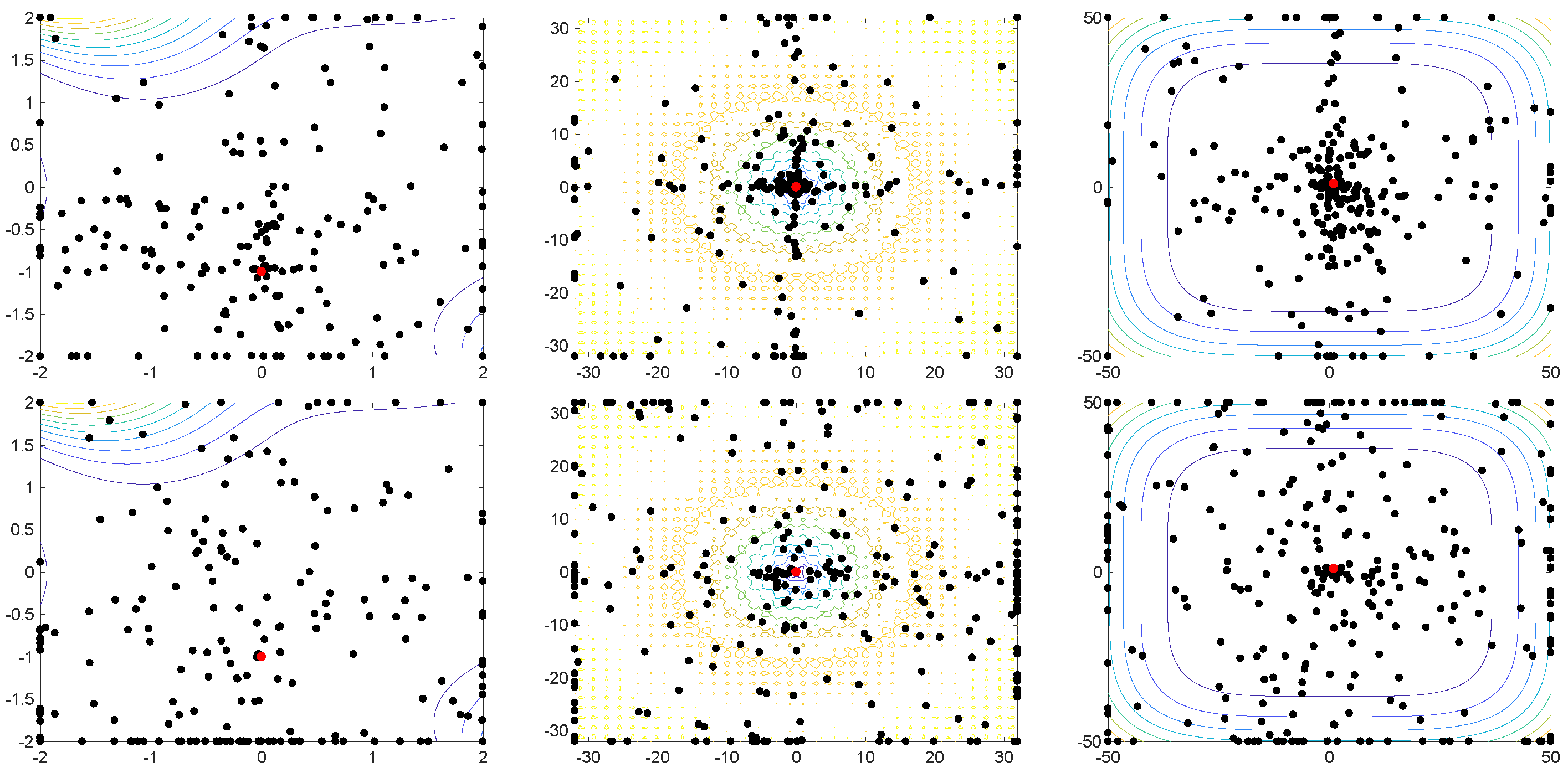
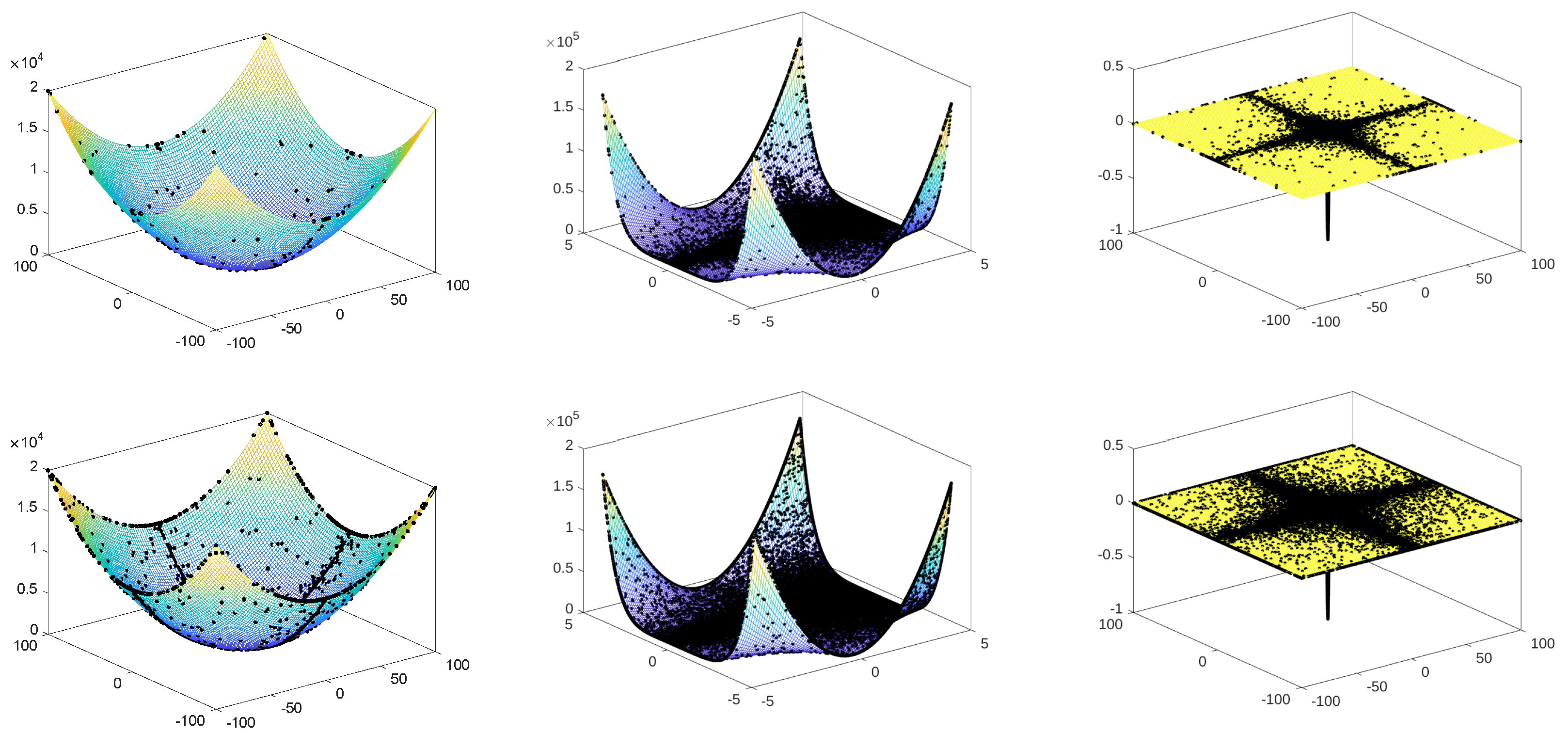
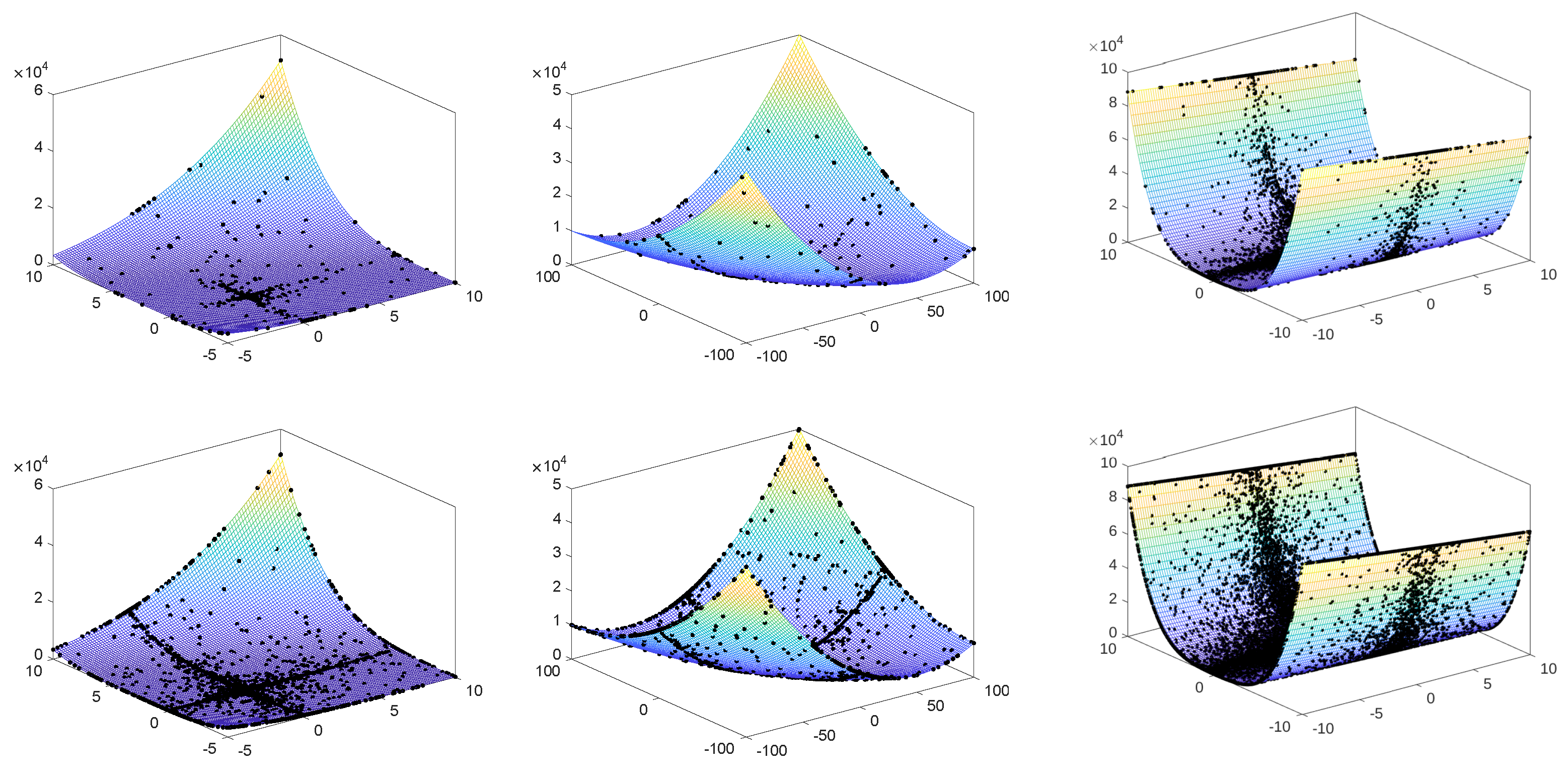
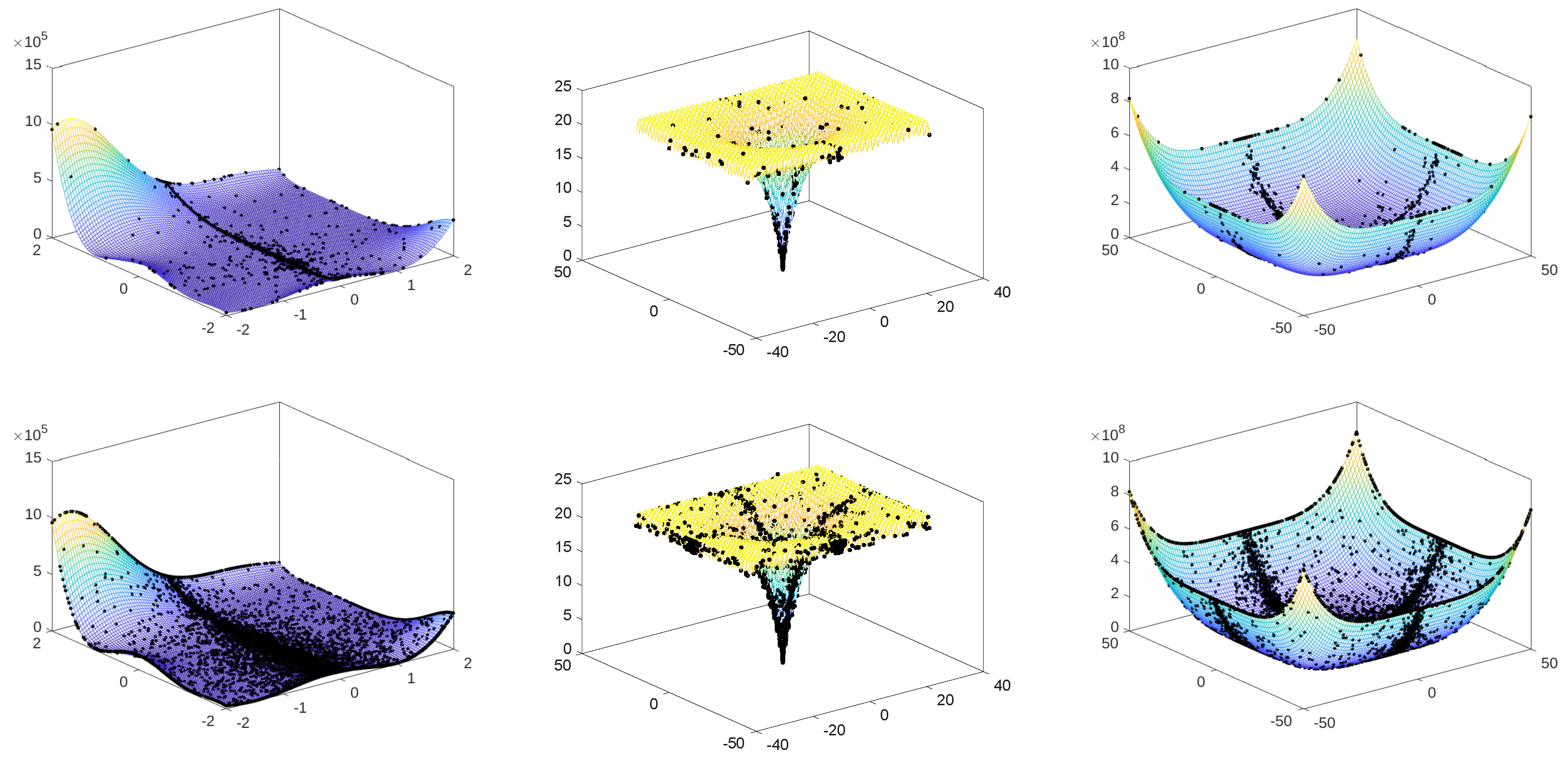
4.1. Benchmark Functions
4.2. Engineering Optimization Problems
4.2.1. Pressure Vessel Design Problem
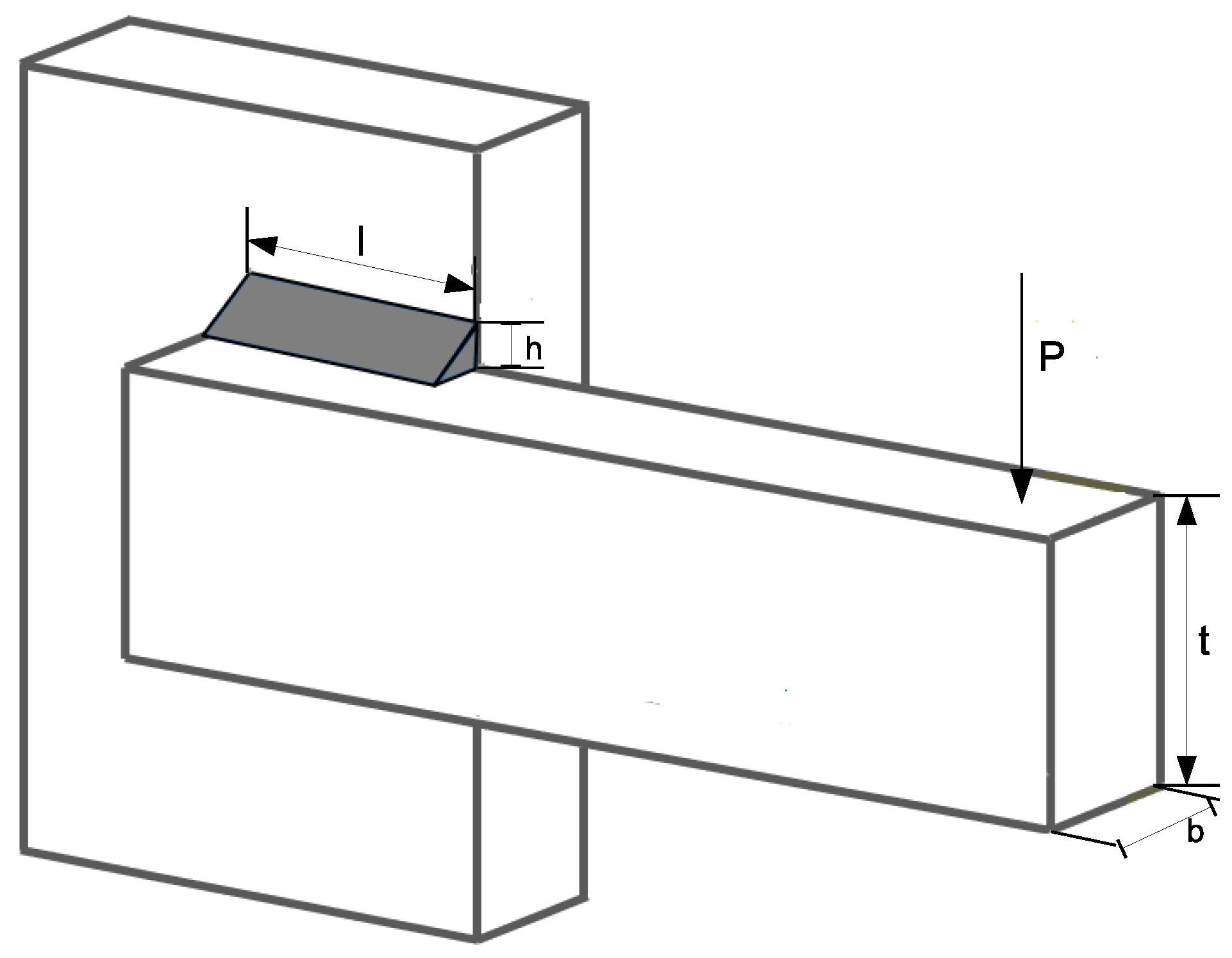
4.2.2. Welded Beam Design Problem
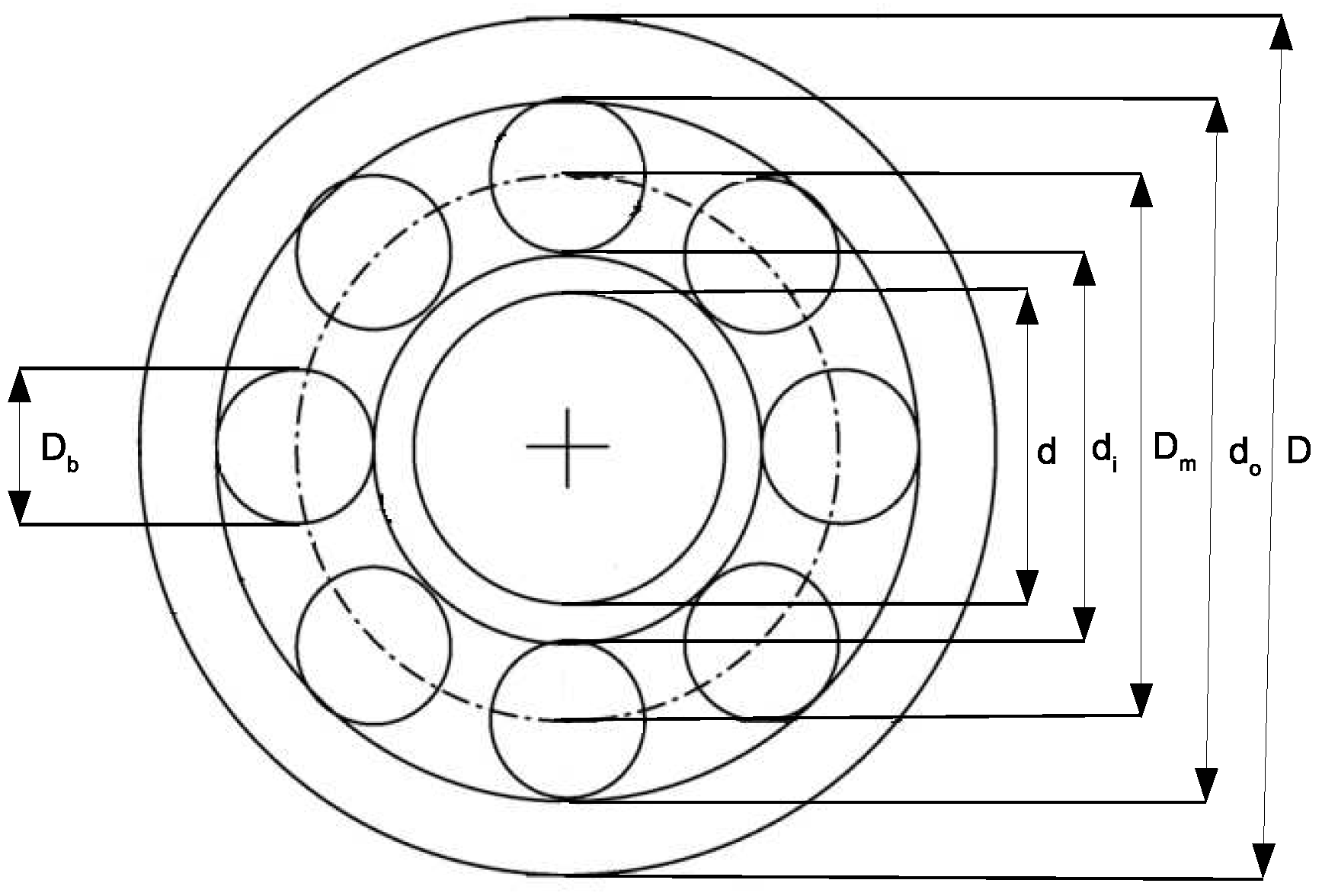
4.2.3. Rolling Element Bearing Design Problem
5. Numerical Experiments
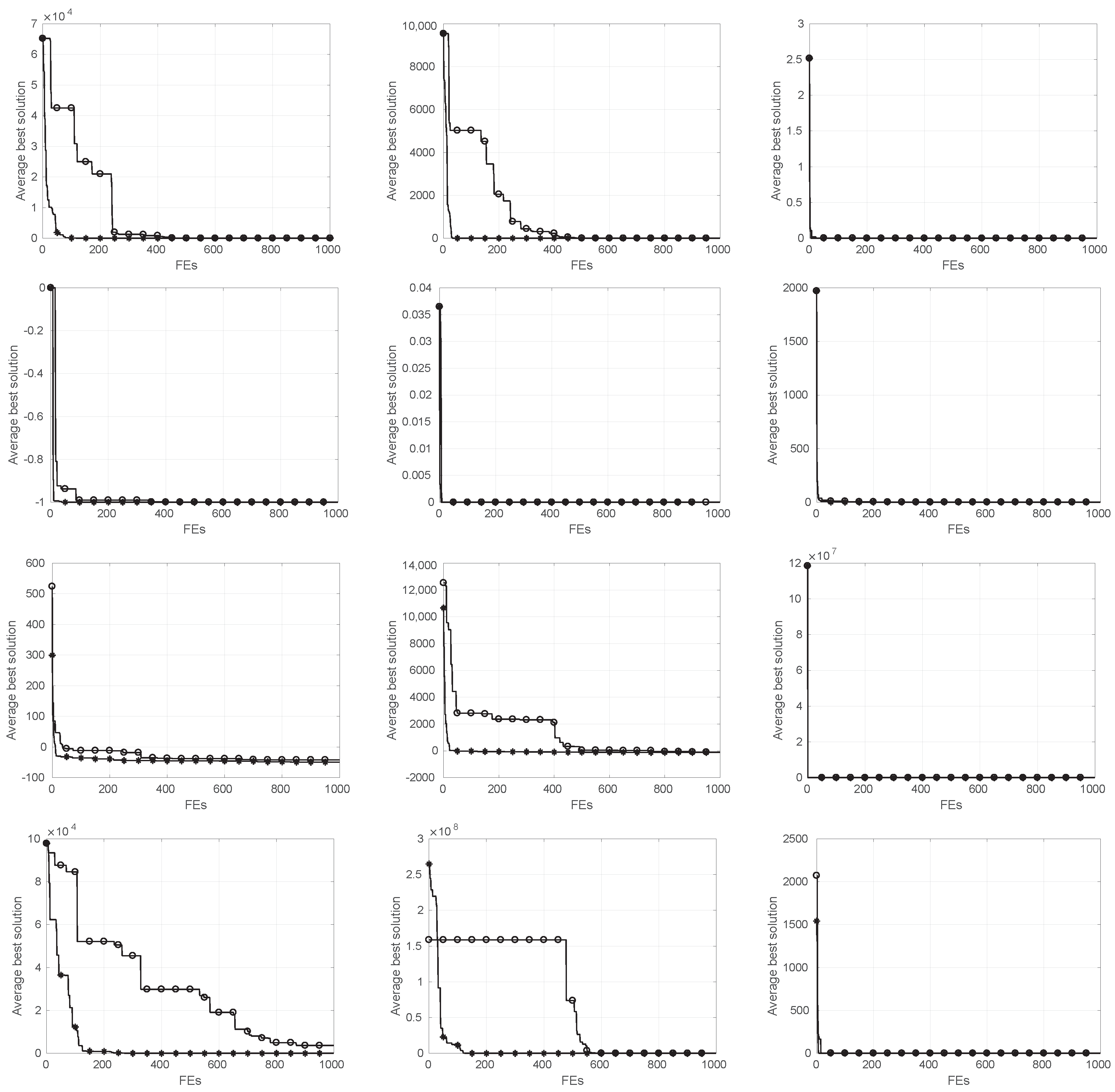
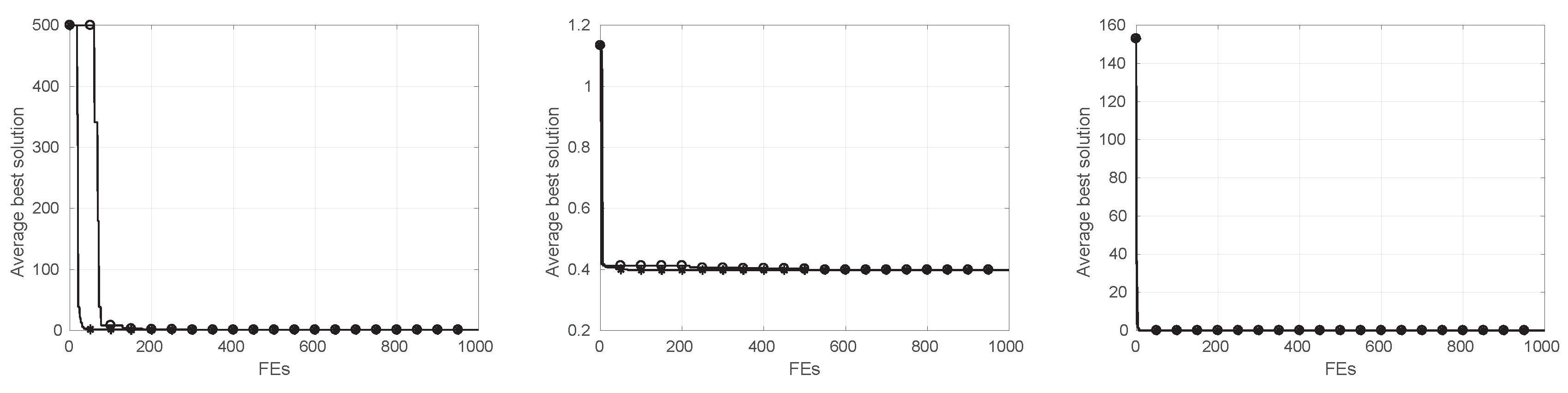
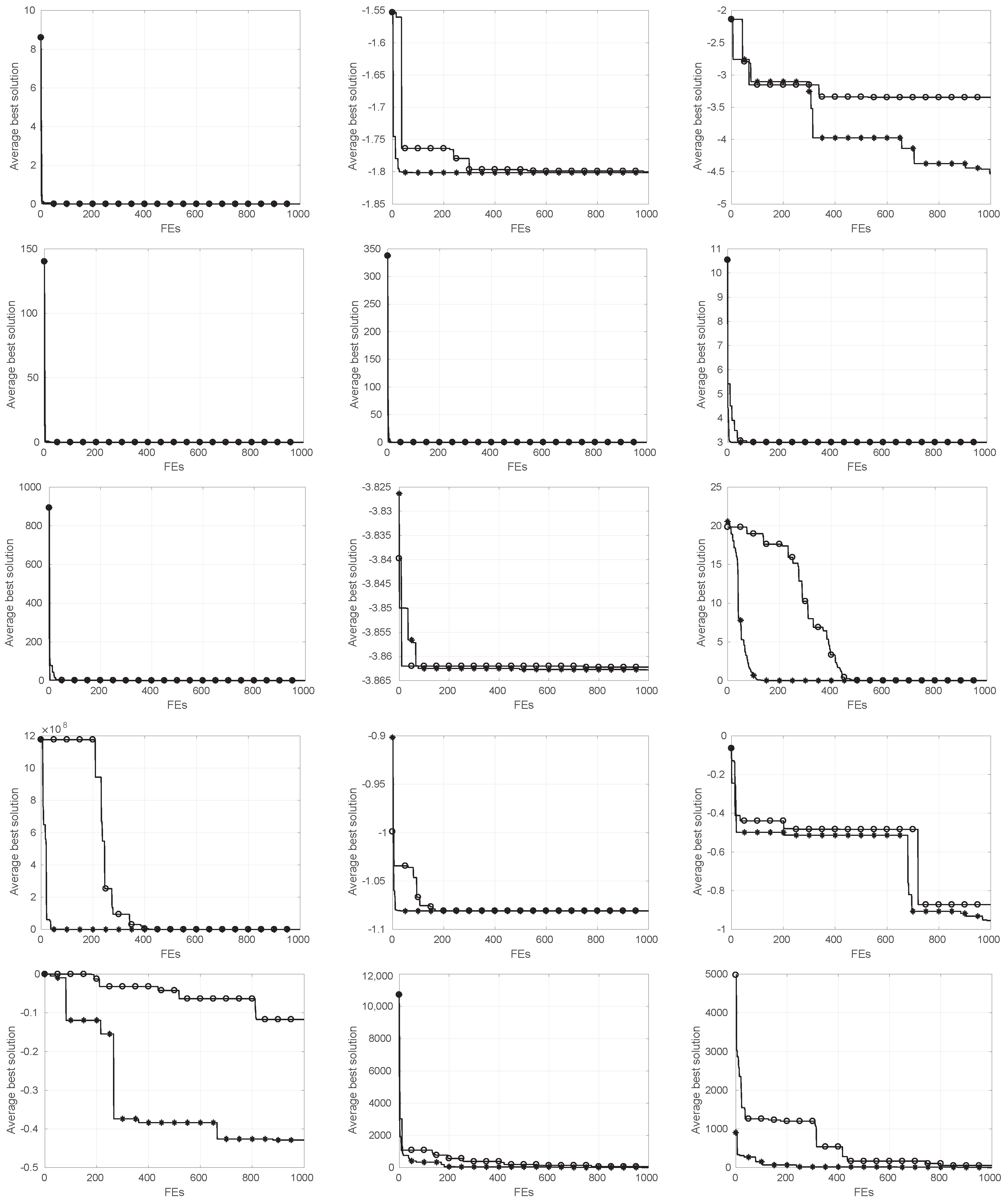
5.1. Comparative Analysis ESCA vs. SCA
5.2. Further Comparison with Numerous State-of-the-Art Algorithms
5.2.1. Benchmarking of the Comparison Algorithms
5.2.2. Optimization Outcomes for Classical Engineering Problems
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dorigo, M.; Di Caro, G. The Ant Colony Optimization Meta-heuristic. In New Ideas in Optimization; McGraw-Hill Ltd.: Maidenhead, UK, 1999; pp. 11–32. [Google Scholar]
- Schwefel, H.P. Evolutionsstrategie Und Numerische Optimierung. Ph.D. Thesis, Department of Process Engineering, Technical University of Berlin, Berlin, Germany, 1975. [Google Scholar]
- Bäck, T.; Rudolph, G.; Schwefel, H.P. Evolutionary Programming and Evolution Strategies: Similarities and Differences. In Proceedings of the Second Annual Conference on Evolutionary Programming, La Jolla, CA, USA, 25–26 February 1993; pp. 11–22. [Google Scholar]
- Koza, J.R. Genetic Programming: A Paradigm for Genetically Breeding Populations of Computer Programs to Solve Problems; Technical Report; Stanford University: Stanford, CA, USA, 1990. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the Performance of Artificial Bee Colony (ABC) Algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Ingber, L. Simulated annealing: Practice versus theory. Math. Comput. Model. 1993, 18, 29–57. [Google Scholar] [CrossRef] [Green Version]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Price, K.V. An Introduction to Differential Evolution. In New Ideas in Optimization; McGraw-Hill Ltd.: Maidenhead, UK, 1999; pp. 79–108. [Google Scholar]
- Storn, R. On the usage of differential evolution for function optimization. In Proceedings of the North American Fuzzy Information Processing, Berkeley, CA, USA, 19–22 June 1996; pp. 519–523. [Google Scholar]
- Pant, M.; Zaheer, H.; Garcia-Hernandez, L.; Abraham, A. Differential evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 2020, 90, 103479. [Google Scholar]
- Farmer, J.D.; Packard, N.H.; Perelson, A.S. The Immune System, Adaptation, and Machine Learning. Phys. D 1986, 2, 187–204. [Google Scholar] [CrossRef]
- Kim, J.H. Harmony Search Algorithm: A Unique Music-inspired Algorithm. Procedia Eng. 2016, 154, 1401–1405. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Kumar-Majhi, S. An Efficient Feed Foreword Network Model with Sine Cosine Algorithm for Breast Cancer Classification. Int. J. Syst. Dyn. Appl. (IJSDA) 2018, 7, 202397. [Google Scholar] [CrossRef] [Green Version]
- Rajesh, K.; Dash, S. Load frequency control of autonomous power system using adaptive fuzzy based PID controller optimized on improved sine cosine algorithm. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2361–2373. [Google Scholar] [CrossRef]
- Khezri, R.; Oshnoei, A.; Tarafdar Hagh, M.; Muyeen, S. Coordination of Heat Pumps, Electric Vehicles and AGC for Efficient LFC in a Smart Hybrid Power System via SCA-Based Optimized FOPID Controllers. Energies 2018, 11, 420. [Google Scholar] [CrossRef] [Green Version]
- Ramanaiah, M.L.; Reddy, M.D. Sine cosine algorithm for loss reduction in distribution system with unified power quality conditioner. i-Manag. J. Power Syst. Eng. 2017, 5, 10. [Google Scholar]
- Dhundhara, S.; Verma, Y.P. Capacitive energy storage with optimized controller for frequency regulation in realistic multisource deregulated power system. Energy 2018, 147, 1108–1128. [Google Scholar] [CrossRef]
- Singh, V.P. Sine cosine algorithm based reduction of higher order continuous systems. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 649–653. [Google Scholar] [CrossRef]
- Das, S.; Bhattacharya, A.; Chakraborty, A.K. Solution of short-term hydrothermal scheduling using sine cosine algorithm. Soft Comput. 2018, 22, 6409–6427. [Google Scholar] [CrossRef]
- Kumar, V.; Kumar, D. Handbook of Research on Machine Learning Innovations and Trends; IGI Global: Hershey, PA, USA, 2017; pp. 715–726. [Google Scholar] [CrossRef] [Green Version]
- Yıldız, B.S.; Yıldız, A.R. Comparison of grey wolf, whale, water cycle, ant lion and sine-cosine algorithms for the optimization of a vehicle engine connecting rod. Mater. Test. 2018, 60, 311–315. [Google Scholar] [CrossRef]
- Elfattah, M.A.; Abuelenin, S.; Hassanien, A.E.; Pan, J.S. Handwritten Arabic Manuscript Image Binarization Using Sine Cosine Optimization Algorithm. In Proceedings of the International Conference on Genetic and Evolutionary Computing, Fuzhou, Fujian, China, 7–9 November 2016; Volume 536, pp. 273–280. [Google Scholar]
- Mirjalili, S.M.; Mirjalili, S.Z.; Saremi, S.; Mirjalili, S. Studies in Computational Intelligence; Springer: Berlin, Germany, 2020; Volume 811, pp. 201–217. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abd Elaziz, M.; Al-Qaness, M.A.A.; Khalil, H.A.; Kim, S. Improved Artificial Bee Colony Using Sine-Cosine Algorithm for Multi-Level Thresholding Image Segmentation. IEEE Access 2020, 8, 26304–26315. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K.; Mirjalili, S.; Kim, J.H. A modified sine cosine algorithm with novel transition parameter and mutation operator for global optimization. Expert Syst. Appl. 2020, 154, 113395. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. A novel hybrid sine cosine algorithm for global optimization and its application to train multilayer perceptrons. Appl. Intell. 2020, 50, 993–1026. [Google Scholar] [CrossRef]
- Rizk-Allah, R.M. An improved sine–cosine algorithm based on orthogonal parallel information for global optimization. Soft Comput. 2019, 23, 7135–7161. [Google Scholar] [CrossRef]
- Belazzoug, M.; Touahria, M.; Nouioua, F.; Brahimi, M. An improved sine cosine algorithm to select features for text categorization. J. King Saud-Univ.-Comput. Inf. Sci. 2020, 32, 454–464. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. Improved sine cosine algorithm with crossover scheme for global optimization. Knowl.-Based Syst. 2019, 165, 374–406. [Google Scholar] [CrossRef]
- Qu, C.; Zeng, Z.; Dai, J.; Yi, Z.; He, W. A modified sine-cosine algorithm based on neighborhood search and greedy levy mutation. Comput. Intell. Neurosci. 2018, 2018, 4231647. [Google Scholar] [CrossRef] [PubMed]
- Rosli, S.J.; Rahim, H.A.; Abdul Rani, K.N.; Ngadiran, R.; Ahmad, R.B.; Yahaya, N.Z.; Abdulmalek, M.; Jusoh, M.; Yasin, M.N.M.; Sabapathy, T.; et al. A Hybrid Modified Method of the Sine Cosine Algorithm Using Latin Hypercube Sampling with the Cuckoo Search Algorithm for Optimization Problems. Electronics 2020, 9, 1786. [Google Scholar] [CrossRef]
- Abd Elaziz, M.; Oliva, D.; Xiong, S. An improved opposition-based sine cosine algorithm for global optimization. Expert Syst. Appl. 2017, 90, 484–500. [Google Scholar] [CrossRef]
- Sindhu, R.; Ngadiran, R.; Yacob, Y.M.; Zahri, N.A.H.; Hariharan, M. Sine–cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Comput. Appl. 2017, 28, 2947–2958. [Google Scholar] [CrossRef]
- Long, W.; Wu, T.; Liang, X.; Xu, S. Solving high-dimensional global optimization problems using an improved sine cosine algorithm. Expert Syst. Appl. 2019, 123, 108–126. [Google Scholar] [CrossRef]
- Issa, M.; Hassanien, A.E.; Oliva, D.; Helmi, A.; Ziedan, I.; Alzohairy, A. ASCA-PSO: Adaptive sine cosine optimization algorithm integrated with particle swarm for pairwise local sequence alignment. Expert Syst. Appl. 2018, 99, 56–70. [Google Scholar] [CrossRef]
- Chegini, S.N.; Bagheri, A.; Najafi, F. PSOSCALF: A new hybrid PSO based on Sine Cosine Algorithm and Levy flight for solving optimization problems. Appl. Soft Comput. 2018, 73, 697–726. [Google Scholar] [CrossRef]
- Nenavath, H.; Jatoth, R.K.; Das, S. A synergy of the sine-cosine algorithm and particle swarm optimizer for improved global optimization and object tracking. Swarm Evol. Comput. 2018, 43, 1–30. [Google Scholar] [CrossRef]
- Singh, N.; Singh, S. A novel hybrid GWO-SCA approach for optimization problems. Eng. Sci. Technol. Int. J. 2017, 20, 1586–1601. [Google Scholar] [CrossRef]
- Nenavath, H.; Jatoth, R.K. Hybridizing sine cosine algorithm with differential evolution for global optimization and object tracking. Appl. Soft Comput. 2018, 62, 1019–1043. [Google Scholar] [CrossRef]
- Migallón, H.; Jimeno-Morenilla, A.; Sánchez-Romero, J.L.; Rico, H.; Rao, R.V. Multipopulation-based multi-level parallel enhanced Jaya algorithms. J. Supercomput. 2019, 75, 1697–1716. [Google Scholar] [CrossRef] [Green Version]
- García-Monzó, A.; Migallón, H.; Jimeno-Morenilla, A.; Sánchez-Romero, J.L.; Rico, H.; Rao, R.V. Efficient Subpopulation Based Parallel TLBO Optimization Algorithms. Electronics 2018, 8, 19. [Google Scholar] [CrossRef] [Green Version]
- Free Software Foundation, Inc. GCC, the GNU Compiler Collection. Available online: https://www.gnu.org/software/gcc/index.html (accessed on 15 October 2021).
- OpenMP Architecture Review Board. OpenMP Application Program Interface, Version 3.1. 2011. Available online: http://www.openmp.org (accessed on 15 October 2021).
- Dimakopoulos, V.V.; Hadjidoukas, P.E.; Philos, G.C. A Microbenchmark Study of OpenMP Overheads under Nested Parallelism. In OpenMP in a New Era of Parallelism; Eigenmann, R., de Supinski, B.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–12. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Hodges, J.; Lehmann, E.L. Rank methods for combination of independent experiments in analysis of variance. In Selected Works of EL Lehmann; Springer: Berlin/Heidelberg, Germany, 2012; pp. 403–418. [Google Scholar]
- Quade, D. On analysis of variance for the k-sample problem. Ann. Math. Stat. 1966, 37, 1747–1758. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]
- Chen, H.; Wang, M.; Zhao, X. A multi-strategy enhanced sine cosine algorithm for global optimization and constrained practical engineering problems. Appl. Math. Comput. 2020, 369, 124872. [Google Scholar] [CrossRef]
- Mahdavi, M.; Fesanghary, M.; Damangir, E. An improved harmony search algorithm for solving optimization problems. Appl. Math. Comput. 2007, 188, 1567–1579. [Google Scholar] [CrossRef]
- Rashedi, E.; Nezamabadi-pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- He, Q.; Wang, L. An effective co-evolutionary particle swarm optimization for constrained engineering design problems. Eng. Appl. Artif. Intell. 2007, 20, 89–99. [Google Scholar] [CrossRef]
- Coello, C.A.C. Theoretical and numerical constraint-handling techniques used with evolutionary algorithms: A survey of the state of the art. Comput. Methods Appl. Mech. Eng. 2002, 191, 1245–1287. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Montes, E.M. Constraint-handling in genetic algorithms through the use of dominance-based tournament selection. Adv. Eng. Inform. 2002, 16, 193–203. [Google Scholar] [CrossRef]
- Deb, K. GeneAS: A robust optimal design technique for mechanical component design. In Evolutionary Algorithms in Engineering Applications; Springer: Berlin/Heidelberg, Germany, 1997; pp. 497–514. [Google Scholar]
- Mezura-Montes, E.; Coello, C.A.C. An empirical study about the usefulness of evolution strategies to solve constrained optimization problems. Int. J. Gen. Syst. 2008, 37, 443–473. [Google Scholar] [CrossRef]
- Kaveh, A.; Talatahari, S. An improved ant colony optimization for constrained engineering design problems. Eng. Comput. 2010, 27, 155–182. [Google Scholar] [CrossRef]
- Kaveh, A.; Khayatazad, M. A new meta-heuristic method: Ray Optimization. Comput. Struct. 2012, 112–113, 283–294. [Google Scholar] [CrossRef]
- Rajeswara Rao, B.; Tiwari, R. Optimum design of rolling element bearings using genetic algorithms. Mech. Mach. Theory 2007, 42, 233–250. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.; Vakharia, D. Teaching-learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Sadollah, A.; Bahreininejad, A.; Eskandar, H.; Hamdi, M. Mine blast algorithm: A new population based algorithm for solving constrained engineering optimization problems. Appl. Soft Comput. 2013, 13, 2592–2612. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, L.; Zhang, Z. Supply-Demand-Based Optimization: A Novel Economics-Inspired Algorithm for Global Optimization. IEEE Access 2019, 7, 73182–73206. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id. | Name | Dim. (V) | Domain (Min, Max) |
|---|---|---|---|
| Sphere | 30 | ||
| SumSquares | 30 | ||
| Beale | 2 | ||
| Easom | 2 | ||
| Matyas | 2 | ||
| Colville | 4 | ||
| Trid 6 | 6 | ||
| Trid 10 | 10 | ||
| Zakharov | 10 | ||
| Schwefel_1.2 | 30 | ||
| Rosenbrock | 30 | ||
| Dixon-Price | 5 | ||
| Foxholes | 2 | ||
| Branin | 2 | ||
| Bohachevsky_1 | 2 | ||
| Booth | 2 | ||
| Michalewicz_2 | 2 | ||
| Michalewicz_5 | 5 | ||
| Bohachevsky_2 | 2 | ||
| Bohachevsky_3 | 2 | ||
| GoldStein-Price | 2 | ||
| Perm | 4 | ||
| Hartman_3 | 3 | ||
| Ackley | 30 | ||
| Penalized_2 | 30 | ||
| Langermann_2 | 2 | ||
| Langermann_5 | 5 | ||
| Langermann_10 | 10 | ||
| Fletcher-Powell_5 | 5 | ||
| Fletcher-Powell_10 | 10 |
| Id. | Function |
|---|---|
| Population Size | ||||||
|---|---|---|---|---|---|---|
| 60 | 120 | 240 | ||||
| SCA | ESCA | SCA | ESCA | SCA | ESCA | |
| 349.3 | 308.8 | 683.5 | 711.5 | 1432.5 | 1325.7 | |
| 388.5 | 312.9 | 739.0 | 668.4 | 1474.9 | 1405.0 | |
| 25.2 | 23.4 | 50.4 | 46.8 | 100.6 | 93.6 | |
| 27.8 | 26.4 | 55.6 | 52.8 | 111.2 | 105.6 | |
| 33.9 | 31.4 | 68.8 | 70.2 | 131.7 | 138.5 | |
| 31.3 | 28.6 | 62.4 | 57.1 | 124.7 | 114.1 | |
| 48.6 | 44.1 | 96.9 | 87.9 | 193.7 | 179.3 | |
| 80.5 | 69.8 | 160.0 | 140.8 | 321.4 | 279.2 | |
| 144.7 | 132.7 | 280.6 | 268.0 | 558.3 | 530.3 | |
| 374.5 | 413.7 | 773.6 | 815.8 | 1562.5 | 1657.5 | |
| 223.1 | 208.3 | 442.6 | 416.4 | 884.5 | 833.1 | |
| 38.4 | 36.4 | 77.9 | 72.5 | 154.9 | 145.5 | |
| 461.7 | 466.7 | 923.8 | 933.9 | 1845.8 | 1867.0 | |
| 19.7 | 18.9 | 39.5 | 37.8 | 79.1 | 75.6 | |
| 17.8 | 17.1 | 33.9 | 33.9 | 70.7 | 68.0 | |
| 15.5 | 14.6 | 31.2 | 29.1 | 62.0 | 58.1 | |
| 72.3 | 55.6 | 144.7 | 111.0 | 291.4 | 221.9 | |
| 174.7 | 125.1 | 309.0 | 280.3 | 620.4 | 493.1 | |
| 18.7 | 16.5 | 36.1 | 32.2 | 72.2 | 70.2 | |
| 17.6 | 16.8 | 35.2 | 31.2 | 69.9 | 59.7 | |
| 16.3 | 15.3 | 32.6 | 30.6 | 65.1 | 61.0 | |
| 105.5 | 101.8 | 212.0 | 205.5 | 419.7 | 409.7 | |
| 36.3 | 36.5 | 72.0 | 73.2 | 146.1 | 146.3 | |
| 125.6 | 123.2 | 251.6 | 246.3 | 501.5 | 493.8 | |
| 406.4 | 321.7 | 812.3 | 674.4 | 1707.8 | 1321.8 | |
| 56.4 | 57.1 | 113.3 | 113.5 | 225.6 | 227.2 | |
| 82.0 | 82.0 | 164.3 | 164.1 | 331.8 | 328.8 | |
| 130.6 | 118.5 | 262.2 | 236.1 | 523.4 | 473.2 | |
| 174.0 | 168.7 | 346.9 | 339.4 | 700.0 | 675.1 | |
| 583.4 | 568.9 | 1165.5 | 1134.6 | 2334.1 | 2290.9 | |
| Population Size | ||||||
|---|---|---|---|---|---|---|
| 240 | 120 | 60 | ||||
| SCA | ESCA | SCA | ESCA | SCA | ESCA | |
| 3,639,144 | 75,384 | 1,842,864 | 48,504 | 971,802 | 28,074 | |
| 3,596,880 | 73,464 | 1,808,004 | 43,500 | 988,380 | 24,888 | |
| 24,000 | 2136 | 24,888 | 3072 | 13,878 | 2082 | |
| 306,912 | 4152 | 218,220 | 3432 | 239,166 | 2088 | |
| 1584 | 840 | 756 | 564 | 540 | 312 | |
| – | 9,627,227 | – | 4,450,577 | – | 2,654,280 | |
| * | 3888 | 960 | 5724 | 612 | 3222 | 354 |
| * | 5,031,792 | 317,376 | 2,684,760 | 190,053 | 1,565,184 | 196,337 |
| 1,528,656 | 16,848 | 848,544 | 9708 | 490,854 | 6420 | |
| 5,048,616 | 739,296 | 2,623,800 | 462,456 | 1,400,712 | 311,640 | |
| * | 3,677,160 | 78,720 | 1,906,380 | 45,828 | – | 32,424 |
| – | 6,186,240 | – | 4,982,240 | – | 2,624,640 | |
| 571,008 | 14,088 | 547,320 | 6288 | 236,148 | 36,126 | |
| 70,392 | 1920 | 118,296 | 2256 | 52,782 | 1998 | |
| 5928 | 2352 | 2964 | 1380 | 2262 | 762 | |
| 187,560 | 3120 | 236,952 | 2508 | 131,712 | 2400 | |
| 401,688 | 3888 | 419,220 | 1812 | 236,400 | 2910 | |
| * | 480 | 480 | 240 | 240 | 120 | 120 |
| 6120 | 2448 | 3624 | 1392 | 1896 | 882 | |
| 5160 | 2112 | 4560 | 1296 | 2340 | 834 | |
| 26,856 | 2040 | 28,596 | 1080 | 15,924 | 912 | |
| – | 3,966,264 | – | 3,528,912 | – | 1,907,900 | |
| 7920 | 57,090 | 3,739,200 | 81,345 | 123,720 | 27,760 | |
| 2,290,464 | 30,408 | 1,207,956 | 17,940 | 668,790 | 8304 | |
| * | 3,591,960 | 46,032 | 1,952,616 | 33,756 | 951,708 | 17,022 |
| 20,400 | 9672 | 21,744 | 4848 | 10,193 | 2208 | |
| – | 6,840,528 | – | 5,366,040 | – | 2,930,112 | |
| 480 | 480 | 252 | 252 | 120 | 120 | |
| * | 1,127,832 | 24,168 | 1,148,604 | 27,672 | 840,288 | 26,940 |
| * | – | 9,787,467 | – | 5,338,960 | – | 2,939,910 |
| Population Size | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 240 | 120 | 60 | |||||||
| 2 | 6 | 12 | 2 | 6 | 12 | 2 | 6 | 12 | |
| 2.0 | 5.7 | 10.4 | 2.0 | 5.7 | 11.4 | 1.8 | 5.0 | 9.7 | |
| 2.0 | 5.8 | 10.9 | 1.8 | 5.5 | 10.5 | 2.0 | 4.9 | 9.3 | |
| 1.9 | 4.9 | 6.9 | 1.9 | 4.6 | 4.5 | 1.9 | 3.7 | 2.5 | |
| 2.0 | 5.5 | 10.9 | 1.9 | 5.5 | 10.3 | 1.6 | 5.3 | 3.8 | |
| 1.9 | 5.0 | 9.0 | 1.8 | 4.9 | 7.4 | 1.6 | 4.2 | 3.7 | |
| 2.0 | 5.5 | 10.9 | 1.9 | 5.4 | 10.4 | 1.9 | 5.4 | 3.6 | |
| 1.3 | 3.3 | 4.5 | 1.9 | 4.7 | 5.1 | 1.9 | 4.1 | 3.4 | |
| 2.0 | 5.4 | 9.9 | 2.0 | 5.3 | 9.0 | 1.9 | 5.1 | 6.8 | |
| 1.9 | 5.2 | 10.2 | 1.8 | 5.3 | 10.1 | 1.9 | 5.1 | 9.2 | |
| 2.0 | 5.5 | 11.0 | 1.9 | 5.4 | 10.6 | 2.0 | 5.5 | 10.4 | |
| 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 10.9 | 2.0 | 5.5 | 10.9 | |
| 2.0 | 5.3 | 9.1 | 1.9 | 5.1 | 7.2 | 1.9 | 4.6 | 4.0 | |
| 2.0 | 5.5 | 11.1 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 10.8 | |
| 2.0 | 5.5 | 10.7 | 2.0 | 5.4 | 8.8 | 1.9 | 5.2 | 2.4 | |
| 1.9 | 5.4 | 10.2 | 2.0 | 5.7 | 6.3 | 2.0 | 5.2 | 2.2 | |
| 1.9 | 5.5 | 10.4 | 1.9 | 5.3 | 5.2 | 1.9 | 5.1 | 1.8 | |
| 2.0 | 5.4 | 9.5 | 2.0 | 5.2 | 8.2 | 1.9 | 4.8 | 5.8 | |
| 1.9 | 5.4 | 9.3 | 1.9 | 6.0 | 8.7 | 1.7 | 4.8 | 6.0 | |
| 2.0 | 5.1 | 7.1 | 1.7 | 4.3 | 3.8 | 1.5 | 3.7 | 1.9 | |
| 1.7 | 4.8 | 6.4 | 1.8 | 4.5 | 3.8 | 1.6 | 4.1 | 1.9 | |
| 1.9 | 5.1 | 6.4 | 1.9 | 4.6 | 3.5 | 1.9 | 3.6 | 1.7 | |
| 1.9 | 5.2 | 10.2 | 1.9 | 5.3 | 9.9 | 1.9 | 5.1 | 8.8 | |
| 2.0 | 5.5 | 10.6 | 2.0 | 5.4 | 10.2 | 1.9 | 5.4 | 8.9 | |
| 2.0 | 5.5 | 10.4 | 1.9 | 5.4 | 9.6 | 2.0 | 5.2 | 8.5 | |
| 2.0 | 5.6 | 10.4 | 2.0 | 5.5 | 10.0 | 2.0 | 5.2 | 9.1 | |
| 2.0 | 5.2 | 8.4 | 1.9 | 5.0 | 7.2 | 1.9 | 4.8 | 5.6 | |
| 2.0 | 5.4 | 9.8 | 2.0 | 5.1 | 8.7 | 2.0 | 5.0 | 6.9 | |
| 2.0 | 5.5 | 10.9 | 1.9 | 5.5 | 10.9 | 1.9 | 5.4 | 10.8 | |
| 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 10.6 | 2.0 | 5.4 | 10.4 | |
| 2.0 | 5.6 | 11.1 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 10.9 | |
| Population Size | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 240 | 120 | 60 | |||||||
| 2 | 6 | 12 | 2 | 6 | 12 | 2 | 6 | 12 | |
| 2.0 | 5.7 | 11.6 | 2.0 | 5.8 | 11.6 | 1.9 | 5.7 | 11.2 | |
| 1.9 | 5.5 | 11.4 | 1.9 | 5.6 | 11.2 | 1.9 | 5.2 | 10.5 | |
| 1.9 | 5.5 | 11.0 | 1.9 | 5.5 | 11.0 | 1.9 | 5.5 | 8.2 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.1 | 1.8 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.1 | 2.0 | 5.5 | 11.0 | |
| 1.3 | 3.6 | 7.3 | 2.0 | 5.5 | 11.0 | 1.9 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.1 | 2.0 | 5.5 | 11.1 | |
| 1.9 | 5.6 | 11.1 | 2.1 | 5.3 | 10.6 | 1.9 | 5.2 | 10.7 | |
| 1.9 | 5.4 | 10.9 | 2.0 | 5.6 | 11.1 | 2.0 | 5.5 | 10.9 | |
| 1.9 | 5.5 | 10.9 | 2.0 | 5.5 | 11.1 | 1.9 | 5.5 | 11.1 | |
| 1.9 | 5.5 | 10.7 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 10.9 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 11.1 | |
| 1.9 | 5.5 | 10.9 | 2.0 | 5.5 | 11.0 | 1.9 | 5.5 | 10.9 | |
| 1.9 | 5.4 | 10.9 | 1.8 | 5.2 | 10.3 | 1.8 | 5.4 | 10.9 | |
| 1.9 | 5.5 | 11.0 | 1.9 | 5.5 | 10.9 | 1.9 | 5.5 | 10.8 | |
| 1.9 | 5.5 | 11.1 | 2.0 | 5.5 | 10.7 | 2.0 | 5.5 | 10.9 | |
| 1.9 | 5.6 | 11.3 | 2.0 | 5.6 | 11.1 | 2.0 | 5.6 | 11.3 | |
| 1.8 | 5.1 | 9.9 | 1.9 | 5.4 | 10.5 | 1.9 | 5.0 | 9.9 | |
| 1.9 | 5.3 | 10.4 | 2.0 | 5.5 | 11.0 | 1.9 | 5.5 | 10.9 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 10.2 | 1.9 | 5.5 | 10.9 | |
| 1.9 | 5.2 | 10.4 | 1.9 | 5.2 | 10.5 | 1.9 | 5.3 | 10.3 | |
| 1.9 | 5.4 | 10.7 | 2.0 | 5.5 | 10.9 | 2.0 | 5.5 | 10.8 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.6 | 11.2 | 2.0 | 5.5 | 11.0 | |
| 1.9 | 5.4 | 10.9 | 2.0 | 5.5 | 11.1 | 1.9 | 5.6 | 11.0 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | 1.9 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 10.9 | 2.0 | 5.4 | 11.0 | 2.0 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.1 | 1.9 | 5.6 | 11.1 | |
| 1.9 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | 2.0 | 5.5 | 11.0 | |
| 1.9 | 5.5 | 10.9 | 2.0 | 5.6 | 11.0 | 2.0 | 5.6 | 11.1 | |
| 16 Processes | 20 Processes | ||||||
|---|---|---|---|---|---|---|---|
| 8;2 | 4;4 | 2;8 | 10;2 | 5;4 | 4;5 | 2;10 | |
| 12.5 | 12.5 | 12.1 | 15.9 | 15.0 | 15.2 | 15.2 | |
| 12.5 | 12.1 | 11.6 | 14.4 | 14.8 | 15.0 | 14.7 | |
| 11.9 | 11.8 | 11.8 | 14.7 | 14.7 | 14.7 | 14.7 | |
| 10.1 | 10.0 | 9.7 | 12.7 | 12.4 | 12.3 | 11.7 | |
| 12.2 | 12.1 | 12.2 | 15.3 | 15.2 | 15.1 | 15.1 | |
| 24 Processes | ||||
|---|---|---|---|---|
| 12;2 | 6;4 | 4;6 | 2;12 | |
| 19.0 | 18.3 | 18.7 | 17.4 | |
| 18.0 | 17.4 | 16.9 | 18.0 | |
| 17.6 | 17.6 | 17.4 | 17.4 | |
| 18.2 | 18.0 | 18.1 | 17.8 | |
| 1 | 2 | 6 | 12 | |
|---|---|---|---|---|
| 75,384 | 80,657 | 83,776 | 76,385 | |
| 73,464 | 70,135 | 73,034 | 60,717 | |
| 2136 | 2120 | 2128 | 2200 | |
| 4152 | 4889 | 4005 | 3507 | |
| 840 | 842 | 687 | 312 | |
| 9,627,227 | 9,966,401 | 9,430,103 | 9,876,351 | |
| * | 960 | 762 | 722 | 583 |
| * | 317,376 | 374,307 | 255,284 | 324,357 |
| 16,848 | 16,516 | 17,853 | 17,829 | |
| 739,296 | 854,471 | 780,928 | 743,569 | |
| * | 78,720 | 65,643 | 75,129 | 76,902 |
| 6,186,240 | 7,359,497 | 8,535,793 | 5,457,901 | |
| 14,088 | 9603 | 7294 | 11,392 | |
| 1920 | 2042 | 3831 | 2259 | |
| 2352 | 2144 | 2453 | 1722 | |
| 3120 | 3342 | 3328 | 4471 | |
| 3888 | 3517 | 3275 | 2470 | |
| * | 480 | 456 | 453 | 373 |
| 2448 | 2259 | 2192 | 1990 | |
| 2112 | 2262 | 2031 | 1892 | |
| 2040 | 1732 | 1601 | 974 | |
| 3,966,264 | 3,298,233 | 5,086,208 | 7,588,192 | |
| 57,090 | 3134 | 4069 | 3396 | |
| 30,408 | 28,982 | 30,281 | 30,248 | |
| * | 46,032 | 56,975 | 35,157 | 41,468 |
| 9672 | 15,605 | 13,573 | 10,713 | |
| 6,840,528 | 10,618,500 | 3,333,940 | 8,731,516 | |
| 480 | 440 | 462 | 164 | |
| * | 24,168 | 30,604 | 25,408 | 26,676 |
| * | 9,787,467 | 8,810,661 | 8,232,263 | 10,546,564 |
| 1 | 2 | 6 | 12 | |
|---|---|---|---|---|
| 28,074 | 32,624 | 28,419 | 28,128 | |
| 24,888 | 24,323 | 25,030 | 22,209 | |
| 2082 | 2361 | 1867 | 1670 | |
| 2088 | 2319 | 1762 | 2220 | |
| 312 | 314 | 250 | 173 | |
| 2,654,280 | 1,896,252 | 2,914,210 | 1,951,487 | |
| * | 354 | 325 | 430 | 262 |
| * | 196,337 | 279,480 | 347,191 | 238,579 |
| 6420 | 7143 | 6844 | 7113 | |
| 311,640 | 262,261 | 308,376 | 310,209 | |
| * | 32,424 | 28,081 | 28,738 | 32,903 |
| 2,624,640 | 2,353,703 | 2,680,174 | 2,202,838 | |
| 36,126 | 18,554 | 6345 | 34,818 | |
| 1998 | 1944 | 1917 | 2689 | |
| 762 | 820 | 753 | 520 | |
| 2400 | 2503 | 3393 | 2781 | |
| 2910 | 1271 | 2745 | 2865 | |
| * | 120 | 114 | 105 | 63 |
| 882 | 762 | 879 | 604 | |
| 834 | 807 | 812 | 629 | |
| 912 | 691 | 743 | 543 | |
| 1,907,900 | 1,110,490 | 1,874,520 | 2,209,849 | |
| 27,760 | 3956 | 2633 | 3782 | |
| 8304 | 9840 | 10,120 | 9041 | |
| * | 17,022 | 21,353 | 28,550 | 17,609 |
| 2208 | 2626 | 9685 | 1920 | |
| 2,930,112 | 2,842,249 | 2,925,193 | 2,806,709 | |
| 120 | 113 | 113 | 37 | |
| * | 26,940 | 12,415 | 17,103 | 17,228 |
| * | 2,939,910 | 2,650,149 | 2,863,317 | 2,815,149 |
| 1 | 2 | 6 | 12 | |
|---|---|---|---|---|
| 80,136 | 83,277 | 90,626 | 84,218 | |
| 73,824 | 72,792 | 73,927 | 74,209 | |
| 2568 | 2578 | 2989 | 3313 | |
| 3264 | 5795 | 5436 | 5963 | |
| 816 | 633 | 750 | 410 | |
| 8,974,650 | 10,097,595 | 10,025,662 | 11,314,284 | |
| * | 1032 | 759 | 897 | 481 |
| * | 253,920 | 34,7465 | 61,2221 | 86,7391 |
| 17,184 | 16,644 | 23,193 | 25,164 | |
| 71,4336 | 85,8736 | 1,078,127 | 1,252,559 | |
| * | 64,656 | 77,582 | 88,175 | 10,3109 |
| 8,937,680 | 7,699,045 | 10,565,357 | 11,289,390 | |
| 46,872 | 10,347 | 17,452 | 20,750 | |
| 1992 | 3554 | 4702 | 5277 | |
| 2256 | 2277 | 2656 | 1922 | |
| 4896 | 4869 | 6881 | 6861 | |
| 3264 | 3640 | 4408 | 5952 | |
| * | 480 | 411 | 413 | 306 |
| 2256 | 2204 | 2452 | 2353 | |
| 2304 | 2441 | 2661 | 1826 | |
| 1896 | 1590 | 2347 | 2041 | |
| 4,256,610 | 7,094,932 | 7,742,422 | 6,726,769 | |
| 10,1640 | 49,884 | 14,750 | 30,406 | |
| 31,152 | 32,214 | 32,039 | 33,949 | |
| * | 37,752 | 47,883 | 46,427 | 41,350 |
| 8592 | 3266 | 2386 | 3399 | |
| 8,689,680 | 9,215,379 | 10,203,567 | 10,787,817 | |
| 528 | 456 | 444 | 199 | |
| * | 21,624 | 29,572 | 58,600 | 46,029 |
| * | 10,729,470 | 10,103,632 | 10,519,594 | 9,802,382 |
| 1 | 2 | 6 | 12 | |
|---|---|---|---|---|
| 28,308 | 25,754 | 37,605 | 33,407 | |
| 24,684 | 25,346 | 26,985 | 26,891 | |
| 1644 | 1163 | 1876 | 3188 | |
| 2778 | 2239 | 4294 | 4816 | |
| 378 | 307 | 228 | 308 | |
| 2,742,830 | 2,918,138 | 2,936,681 | ||
| * | 402 | 415 | 376 | 156 |
| * | 216,387 | 314,711 | 495,643 | 602,778 |
| 6822 | 6827 | 9873 | 11,370 | |
| 314,562 | 316,765 | 415,446 | 413,730 | |
| * | 28,338 | 26,143 | 29,280 | 35,931 |
| 2,444,835 | 2,056,447 | 2,802,878 | 2,993,886 | |
| 52,848 | 35,565 | 30,404 | 63,877 | |
| 1680 | 2625 | 7972 | 5786 | |
| 732 | 926 | 851 | 583 | |
| 2736 | 6429 | 4814 | 8359 | |
| 2790 | 3023 | 5588 | 9495 | |
| * | 120 | 101 | 105 | 46 |
| 630 | 846 | 877 | 563 | |
| 792 | 736 | 878 | 732 | |
| 858 | 914 | 930 | 1437 | |
| 1,089,000 | 1,850,238 | 2,757,559 | ||
| 1980 | 11,291 | 20,030 | 21,210 | |
| 8940 | 9557 | 8676 | 11,540 | |
| * | 17,652 | 21,631 | 17,447 | 17,945 |
| 3342 | 1151 | 2377 | 3869 | |
| 2,918,580 | 2,865,679 | 2,970,869 | 2,779,579 | |
| 120 | 116 | 105 | 30 | |
| * | 23,586 | 22,921 | 42,961 | 59,068 |
| * | 2,782,130 | 2,885,935 | 2,631,535 | 2,801,275 |
| Thread Id. | |||||||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| Subpopulation Sizes | # FEs | ||||||
| 40 | 40 | 40 | 40 | 40 | 40 | 10,025,662 | |
| 80 | 60 | 40 | 30 | 20 | 10 | 8,365,248 | |
| 40 | 40 | 40 | 40 | 40 | 40 | 7,742,422 | |
| 80 | 60 | 40 | 30 | 20 | 10 | 6,341,866 | |
| 40 | 40 | 40 | 40 | 40 | 40 | 10,203,567 | |
| 80 | 60 | 40 | 30 | 20 | 10 | 9,941,450 | |
| Population Size | |||
|---|---|---|---|
| 60 | 120 | 240 | |
| Pressure Vessel Problem | |||
| ESCA-10000 | 6060.2070 | 6060.7420 | 6059.9340 |
| SCA-10000 | 6079.0610 | 6091.4340 | 6068.5540 |
| ESCA-20000 | 6060.0950 | 6059.8290 | 6059.8000 |
| SCA-20000 | 6065.7460 | 6066.9530 | 6069.2260 |
| Welded beam problem | |||
| ESCA-10000 | 1.728844 | 1.726625 | 1.726300 |
| SCA-10000 | 1.748143 | 1.749394 | 1.747236 |
| ESCA-20000 | 1.726585 | 1.726704 | 1.725514 |
| SCA-20000 | 1.751480 | 1.747207 | 1.738482 |
| Rolling element bearing problem | |||
| ESCA-10000 | 81,706.17 | 81,798.38 | 81,832.05 |
| SCA-10000 | 80,673.58 | 81,333.65 | 80,318.50 |
| ESCA-20000 | 81,803.87 | 81,774.60 | 81,836.77 |
| SCA-20000 | 80,224.49 | 80,335.60 | 81,086.44 |
| Population Size | ||||||
|---|---|---|---|---|---|---|
| 60 | 120 | 240 | ||||
| SCA | ESCA | SCA | ESCA | SCA | ESCA | |
| 2.757179 × | 0.000000 | 1.712496 × | 0.000000 | 4.457065 × | 0.000000 | |
| 8.616185 × | 0.000000 | 1.046044 × | 0.000000 | 1.112510 × | 0.000000 | |
| 6.811942 × | 5.491076 × | 4.783583 × | 3.114413 × | 1.401307 × | 7.104723 × | |
| −9.999516 × | −1.000000 | −9.999736 × | −1.000000 | −9.999892 × | −1.000000 | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| 9.900274 × | 8.185273 × | 9.765063 × | 2.929811 × | 6.404594 × | 2.334942 × | |
| −4.845251 × | −4.990339 × | −4.877389 × | −4.995156 × | −4.896195 × | −4.996917 × | |
| −1.262160 × | −1.539732 × | −1.339290 × | −1.787089 × | −1.501428 × | −1.862011 × | |
| 8.721680 × | 0.000000 | 3.156447 × | 0.000000 | 2.251127 × | 0.000000 | |
| 8.175285 × | 0.000000 | 1.361425 × | 0.000000 | 2.200964 × | 0.000000 | |
| 2.701419 × | 2.643757 × | 2.699064 × | 2.614943 × | 2.663097 × | 2.585579 × | |
| 3.584155 × | 5.114134 × | 3.100522 × | 4.890716 × | 2.815470 × | 4.889729 × | |
| 1.064141 | 1.196414 | 9.980039 × | 1.064141 | 9.980038 × | 9.980038 × | |
| 3.979373 × | 3.978874 × | 3.979186 × | 3.978874 × | 3.979079 × | 3.978874 × | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| 2.880073 × | 3.813791 × | 1.142770 × | 7.944414 × | 6.238591 × | 1.858303 × | |
| −1.774460 | −1.801303 | −1.801248 | −1.801303 | −1.801272 | −1.801303 | |
| −3.187932 | −3.700737 | −3.375650 | −4.044260 | −3.610325 | −4.071782 | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| 3.000000 | 3.000000 | 3.000000 | 3.000000 | 3.000000 | 3.000000 | |
| 3.214731 × | 6.673788 × | 1.718025 × | 3.599778 × | 1.316666 × | 2.510527 × | |
| −3.855633 | −3.858840 | −3.855658 | −3.859628 | −3.857749 | −3.860941 | |
| 4.588922 × | 3.996803 × | 4.233650 × | 3.878379 × | 4.115227 × | 3.996803 × | |
| 1.888945 | 1.585867 | 1.787761 | 1.515388 | 1.698389 | 1.389630 | |
| −1.069455 | −1.080938 | −1.080930 | −1.080938 | −1.080936 | −1.080938 | |
| −5.685987 × | −6.957021 × | −6.135416 × | −8.465688 × | −7.018316 × | −8.571367 × | |
| −3.945496 × | −1.893884 × | −8.203238 × | −2.315995 × | −1.025653 × | −2.631384 × | |
| 3.258800 × | 3.224237 | 1.912760 × | 1.364237 | 1.720010 × | 7.855821 × | |
| 3.745441 × | 2.581768 | 2.071528 × | 1.359673 | 1.765572 × | 9.444320 × | |
| Vessel | 6.213857 × | 6.097895 × | 6.176765 × | 6.067191 × | 6.150466 × | 6.062122 × |
| Beam | 1.792532 | 1.733833 | 1.783172 | 1.731625 | 1.770235 | 1.729274 |
| Bearing | 7.303758 × | 8.116530 × | 7.449770 × | 8.147987 × | 7.689757 × | 8.162418 × |
| Population Size | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 60 | 120 | 240 | |||||||
| Ranking | |||||||||
| Friedman | F. aligned | Quad | Friedman | F. aligned | Quad | Friedman | F. aligned | Quad | |
| ESCA | 1.1970 | 22.7121 | 1.1738 | 1.2273 | 23.3485 | 1.1934 | 1.2273 | 22.8333 | 1.1783 |
| SCA | 1.8030 | 44.2879 | 1.8262 | 1.7727 | 43.6515 | 1.8066 | 1.7727 | 44.1667 | 1.8217 |
| ESCA | GWO | HHO | WOA | |
|---|---|---|---|---|
| 14,502 | 6920 | 2635 | 7567 | |
| 12,399 | 6261 | 2024 | 5877 | |
| 1051 | 1461 | 535 | 829 | |
| 1582 | 6352 | 3020 | 2123 | |
| 282 | 400 | 307 | 346 | |
| 1,121,028 | 1,019,746 | 1,404,298 | 1,173,481 | |
| * | 307 | 281 | 214 | 268 |
| * | 17,545 | 3946 | 1329 | 1165 |
| 7543 | 3501 | 2219 | 149,835 | |
| 77,362 | 22,158 | 6625 | 1,058,019 | |
| * | 10,727 | 4732 | 1054 | 4077 |
| 853,399 | 1,088,983 | 11,311 | 7280 | |
| 204,227 | 563,262 | 46,084 | 22,772 | |
| 2043 | 7718 | 4079 | 2882 | |
| 856 | 1012 | 1286 | 1701 | |
| 1330 | 2758 | 5191 | 6688 | |
| 1142 | 28,240 | 3073 | 1279 | |
| 799,483 | 1,198,708 | 1,385,561 | 1,015,650 | |
| 880 | 1046 | 1227 | 3460 | |
| 866 | 1029 | 1606 | 8337 | |
| 1214 | 1961 | 1597 | 1634 | |
| 1,058,023 | 1,142,825 | 1,481,119 | 228 | |
| 1415 | 96,594 | 20,375 | 83,281 | |
| 15,322 | 8510 | 4928 | 11,575 | |
| * | 7537 | 2275 | 674 | 1708 |
| 10,031 | 11,503 | 421,650 | 321,426 | |
| 822,131 | 1,128,604 | 583,872 | 927,182 | |
| 962,612 | 968,637 | 1,171,682 | 942,952 | |
| * | 6955 | 11,138 | 131,846 | 33,285 |
| * | 7654 | 55,073 | 158,831 | 59,033 |
| ESCA | GWO | HHO | WOA | ||
|---|---|---|---|---|---|
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 3.262152 × | 5.547644 × | 0.000000 | 1.203238 × | |
| Avg. | 8.895248 × | 1.170037 × | 0.000000 | 6.586553 × | |
| Worst | 6.298503 × | 3.953307 × | 0.000000 | 1.233480 × | |
| SD | 1.412547 × | 9.315382 × | 0.000000 | 2.205548 × | |
| Best | −1.000000 | −1.000000 | −1.000000 | −1.000000 | |
| Avg. | −1.000000 | −1.000000 | −1.000000 | −1.000000 | |
| Worst | −1.000000 | −1.000000 | −1.000000 | −1.000000 | |
| SD | 6.943355 × | 4.337546 × | 8.599751 × | 9.634141 × | |
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 1.807347 × | 4.686073 × | 4.023087 × | 8.462644 × | |
| Avg. | 6.913877 × | 4.435400 × | 3.457026 × | 1.179321 × | |
| Worst | 2.241546 × | 1.330605 | 6.863861 × | 2.110537 × | |
| SD | 6.032768 × | 2.388509 × | 1.911670 × | 5.070219 × | |
| Best | −5.000000 × | −5.000000 × | −5.000000 × | −5.000000 × | |
| Avg. | −4.999999 × | −5.000000 × | −5.000000 × | −5.000000 × | |
| Worst | −4.999997 × | −5.000000 × | −5.000000 × | −5.000000 × | |
| SD | 7.486059 × | 9.662948 × | 5.492594 × | 2.403252 × | |
| Best | −2.099980 × | −2.100000 × | −2.100000 × | −2.100000 × | |
| Avg. | −2.099872 × | −2.063305 × | −2.100000 × | −2.100000 × | |
| Worst | −2.099745 × | −1.549028 × | −2.100000 × | −2.100000 × | |
| SD | 7.246266 × | 1.372988 × | 5.265073 × | 2.197536 × | |
| Best | 0.000000 | 0.000000 | 0.000000 | 5.909506 × | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 4.294324 × | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 6.977677 × | |
| SD | 0.000000 | 0.000000 | 0.000000 | 1.580556 × | |
| Best | 0.000000 | 2.470328 × | 0.000000 | 3.725891 × | |
| Avg. | 0.000000 | 7.905050 × | 0.000000 | 1.000874 × | |
| Worst | 0.000000 | 1.729230 × | 0.000000 | 2.032146 × | |
| SD | 0.000000 | 0.000000 | 0.000000 | 3.734209 × | |
| Best | 2.481895 × | 2.522460 × | 2.489752 × | 2.486321 × | |
| Avg. | 4.935104 × | 2.685818 × | 4.932600 × | 2.612374 × | |
| Worst | 1.003584 × | 2.889938 × | 1.002894 × | 9.002408 × | |
| SD | 4.931226 × | 7.683004 × | 4.928556 × | 3.000263 × | |
| Best | 1.019230 × | 4.395919 × | 4.827285 × | 6.442491 × | |
| Avg. | 3.333334 × | 4.000000 × | 2.551869 × | 3.430491 × | |
| Worst | 6.666667 × | 6.666667 × | 2.321049 × | 2.552220 × | |
| SD | 3.333332 × | 3.265986 × | 5.095444 × | 7.470906 × | |
| Best | 9.980038 × | 9.980038 × | 9.980038 × | 9.980038 × | |
| Avg. | 1.588057 | 1.923918 | 9.980038 × | 9.980038 × | |
| Worst | 1.076318 × | 2.982105 | 9.980038 × | 9.980038 × | |
| SD | 1.831761 | 9.898436 × | 4.309420 × | 6.214605 × | |
| Best | 3.978874 × | 3.978874 × | 3.978874 × | 3.978874 × | |
| Avg. | 3.978874 × | 3.978878 × | 3.978874 × | 3.978874 × | |
| Worst | 3.978874 × | 3.978987 × | 3.978874 × | 3.978874 × | |
| SD | 2.664066 × | 2.044411 × | 3.707297 × | 7.625589 × | |
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 7.032691 × | 4.176314 × | 1.053336 × | 1.518097 × | |
| Avg. | 8.501715 × | 2.991300 × | 9.229996 × | 1.061443 × | |
| Worst | 6.188203 × | 1.038909 × | 1.010500 × | 4.095840 × | |
| SD | 1.224357 × | 2.805821 × | 2.016184 × | 7.755945 × | |
| Best | −1.801303 | −1.801303 | −1.801303 | −1.801303 | |
| Avg. | −1.801303 | −1.801303 | −1.801303 | −1.801303 | |
| Worst | −1.801303 | −1.801303 | −1.801303 | −1.801303 | |
| SD | 3.984603 × | 3.073081 × | 1.314259 × | 1.115984 × | |
| Best | −4.687657 | −4.687658 | −4.687658 | −4.687658 | |
| Avg. | −4.687651 | −4.567539 | −4.599323 | −4.359473 | |
| Worst | −4.687640 | −3.749195 | −4.332021 | −3.573593 | |
| SD | 3.945663 × | 1.662246 × | 7.870435 × | 3.986633 × | |
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Best | 3.000000 | 3.000000 | 3.000000 | 3.000000 | |
| Avg. | 3.000000 | 3.000000 | 3.000000 | 3.000000 | |
| Worst | 3.000000 | 3.000000 | 3.000000 | 3.000000 | |
| SD | 3.827852 × | 5.764236 × | 1.924979 × | 9.407358 × | |
| Best | 2.100529 × | 6.233180 × | 2.762363 × | 2.471215 × | |
| Avg. | 1.123810 × | 1.300996 × | 6.401639 × | 6.126825 × | |
| Worst | 2.974472 × | 1.035930 | 3.782117 × | 3.768746 × | |
| SD | 1.050413 × | 3.277276 × | 9.226831 × | 7.362338 × | |
| Best | −3.862780 | −3.862780 | −3.862780 | −3.862780 | |
| Avg. | −3.862780 | −3.862255 | −3.862780 | −3.862254 | |
| Worst | −3.862780 | −3.854902 | −3.862780 | −3.854902 | |
| SD | 1.061189 × | 1.965115 × | 5.382464 × | 1.965074 × | |
| Best | 3.996803 × | 3.996803 × | 4.440892 × | 4.440892 × | |
| Avg. | 3.996803 × | 7.312669 × | 4.440892 × | 2.575717 × | |
| Worst | 3.996803 × | 7.549517 × | 4.440892 × | 7.549517 × | |
| SD | 0.000000 | 8.862025 × | 0.000000 | 1.967404 × | |
| Best | 1.099003 × | 4.167573 × | 2.110681 × | 1.097794 × | |
| Avg. | 9.811139 × | 9.347600 × | 4.397173 × | 3.273148 × | |
| Worst | 3.014981 × | 3.999622 × | 1.098999 × | 1.083257 × | |
| SD | 1.046370 × | 9.982078 × | 5.381619 × | 2.209943 × | |
| Best | −1.080938 | −1.080938 | −1.080938 | −1.080938 | |
| Avg. | −1.080938 | −1.080938 | −1.075192 | −1.075192 | |
| Worst | −1.080938 | −1.080938 | −1.056311 | −1.056311 | |
| SD | 1.216749 × | 4.717320 × | 1.041639 × | 1.041639 × | |
| Best | −9.649998 × | −9.649999 × | −9.649999 × | −9.649999 × | |
| Avg. | −9.426906 × | −9.350842 × | −9.355537 × | −7.696397 × | |
| Worst | −9.079998 × | −7.367849 × | −7.035660 × | −4.828707 × | |
| SD | 2.065763 × | 4.201816 × | 6.553091 × | 1.953920 × | |
| Best | −9.649623 × | −9.649673 × | −5.170000 × | −9.079987 × | |
| Avg. | −5.700238 × | −4.854299 × | −3.504035 × | −3.186518 × | |
| Worst | −5.317959 × | −5.317959 × | −5.317959 × | −2.813614 × | |
| SD | 2.867891 × | 2.743351 × | 1.736198 × | 2.090066 × | |
| Best | 2.498726 × | 1.093726 × | 9.178611 × | 4.883815 × | |
| Avg. | 5.554048 × | 1.419868 × | 2.459967 × | 1.769584 × | |
| Worst | 5.564318 × | 3.434501 | 3.684844 × | 3.925457 | |
| SD | 9.949693 × | 6.288349 × | 9.190723 × | 7.128277 × | |
| Best | 1.696582 × | 9.049588 × | 5.440372 × | 4.601300 × | |
| Avg. | 4.315053 × | 1.263696 × | 3.685149 × | 2.656585 × | |
| Worst | 2.657023 × | 3.684844 × | 3.684844 × | 7.966935 × | |
| SD | 5.023689 × | 6.609445 × | 1.105443 × | 1.430091 × |
| Ranking | |||
|---|---|---|---|
| Algorithm | Friedman | Friedman Aligned | Quade |
| ESCA | 2.1667 | 54.4667 | 2.2000 |
| GWO | 2.9000 | 65.8000 | 2.8387 |
| HHO | 2.3667 | 60.7667 | 2.5376 |
| WOA | 2.5667 | 60.9667 | 2.4237 |
| Ranking | |||
|---|---|---|---|
| Algorithm | Friedman | Friedman Aligned | Quade |
| ESCA | 2.2000 | 53.7000 | 2.0613 |
| GWO | 2.8333 | 66.2000 | 2.8828 |
| HHO | 2.2000 | 53.0000 | 2.2065 |
| WOA | 2.7667 | 69.1000 | 2.8495 |
| ESCA | GWO | HHO | WOA | |
|---|---|---|---|---|
| ESCA | 0 | 865.5 | 159.6 | 398.9 |
| GWO | −865.5 | 0 | −705.9 | −466.6 |
| HHO | −159.6 | 705.9 | 0 | 239.3 |
| WOA | −398.9 | 466.6 | −239.3 | 0 |
| ESCA | GWO | HHO | WOA | |
|---|---|---|---|---|
| ESCA | 0 | 8.290 × | 4.145 × | 4.145 × |
| GWO | −8.290 × | 0 | −4.145 × | −4.145 × |
| HHO | −4.145 × | 4.145 × | 0 | 0 |
| WOA | −4.145 × | 4.145 × | 0 | 0 |
| # N. var. | ESCA | GWO | HHO | WOA | ||
|---|---|---|---|---|---|---|
| 100 | Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 300 | Best | 0.000000 | 1.472678 × | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 1.195492 × | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 9.890031 × | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 500 | Best | 0.000000 | 6.492796 × | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 2.937464 × | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 5.611286 × | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 100 | Best | 0.000000 | 0.000000 | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 300 | Best | 0.000000 | 2.664037 × | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 1.078682 × | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 1.117063 × | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 500 | Best | 0.000000 | 4.427418 × | 0.000000 | 0.000000 | |
| Avg. | 0.000000 | 3.940111 × | 0.000000 | 0.000000 | ||
| Worst | 0.000000 | 2.032876 × | 0.000000 | 0.000000 | ||
| SD | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ||
| 100 | Best | 8.324341 × | 1.977371 × | 0.000000 | 2.360440 × | |
| Avg. | 7.974122 × | 5.051906 × | 0.000000 | 7.941213 × | ||
| Worst | 2.391764 × | 1.513262 × | 0.000000 | 3.263596 × | ||
| SD | 4.293318 × | 2.716247 × | 0.000000 | 7.423773 × | ||
| 300 | Best | 1.527654 × | 9.975385 × | 0.000000 | 5.113928 × | |
| Avg. | 1.566300 × | 4.698595 × | 0.000000 | 2.324814 × | ||
| Worst | 4.212831 × | 1.409572 × | 0.000000 | 3.178554 × | ||
| SD | 7.582484 × | 2.530258 × | 0.000000 | 5.939182 × | ||
| 500 | Best | 1.617417 × | 4.140184 × | 0.000000 | 8.236708 × | |
| Avg. | 2.137194 × | 1.223006 × | 0.000000 | 1.223004 × | ||
| Worst | 6.411583 × | 3.383713 × | 0.000000 | 1.470168 × | ||
| SD | 1.150914 × | 6.061667 × | 0.000000 | 1.446876 × | ||
| 100 | Best | 9.417182 × | 9.409247 × | 9.460401 × | 9.267136 × | |
| Avg. | 9.690864 × | 9.618143 × | 9.501840 × | 9.309575 × | ||
| Worst | 9.839476 × | 9.827330 × | 9.538590 × | 9.337289 × | ||
| SD | 1.214620 | 8.735442 × | 1.739057 × | 1.907979 × | ||
| 300 | Best | 2.958073 × | 2.957236 × | 2.951796 × | 5.714967 | |
| Avg. | 2.976425 × | 2.970865 × | 2.957244 × | 2.828332 × | ||
| Worst | 2.981833 × | 2.978485 × | 2.959295 × | 2.928548 × | ||
| SD | 6.213829 × | 7.024913 × | 1.326191 × | 5.145973 × | ||
| 500 | Best | 4.973285 × | 4.950355 × | 4.935614 × | 4.904825 × | |
| Avg. | 4.978877 × | 4.969489 × | 4.939061 × | 4.910578 × | ||
| Worst | 4.981244 × | 4.976162 × | 4.939489 × | 4.913822 × | ||
| SD | 2.206418 × | 6.608382 × | 9.846602 × | 2.614029 × | ||
| 100 | Best | 3.996803 × | 1.110223 × | 4.440892 × | 4.440892 × | |
| Avg. | 3.996803 × | 1.453652 × | 4.440892 × | 2.338870 × | ||
| Worst | 3.996803 × | 1.820766 × | 4.440892 × | 7.549517 × | ||
| SD | 0.000000 | 1.117208 × | 0.000000 | 1.995713 × | ||
| 300 | Best | 3.996803 × | 2.176037 × | 4.440892 × | 4.440892 × | |
| Avg. | 3.996803 × | 2.614205 × | 4.440892 × | 2.457294 × | ||
| Worst | 3.996803 × | 2.886580 × | 4.440892 × | 7.549517 × | ||
| SD | 0.000000 | 3.135436 × | 0.000000 | 2.186836 × | ||
| 500 | Best | 3.996803 × | 2.886580 × | 4.440892 × | 4.440892 × | |
| Avg. | 4.825769 × | 3.158955 × | 4.440892 × | 2.457294 × | ||
| Worst | 7.549517 × | 3.597123 × | 4.440892 × | 7.549517 × | ||
| SD | 1.502629 × | 1.985144 × | 0.000000 | 2.371435 × | ||
| 100 | Best | 4.955085 | 2.624674 | 4.766665 × | 3.631265 × | |
| Avg. | 6.169643 | 4.123167 | 4.122016 × | 1.910465 × | ||
| Worst | 7.315961 | 5.184571 | 2.124806 × | 1.105270 × | ||
| SD | 5.111456 × | 5.124575 × | 5.953081 × | 4.083615 × | ||
| 300 | Best | 2.643887 × | 2.282209 × | 2.212745 × | 3.726640 × | |
| Avg. | 2.697167 × | 2.376806 × | 8.795785 × | 8.291253 × | ||
| Worst | 2.757999 × | 2.474629 × | 1.782640 × | 2.452580 × | ||
| SD | 3.359007 × | 4.596044 × | 4.937780 × | 5.300295 × | ||
| 500 | Best | 4.658280 × | 4.243303 × | 8.669046 × | 2.174499 × | |
| Avg. | 4.724426 × | 4.391827 × | 2.089506 × | 3.314949 × | ||
| Worst | 4.807043 × | 4.471744 × | 2.799315 × | 5.016311 × | ||
| SD | 3.648753 × | 5.330605 × | 4.269011 × | 7.169631 × |
| Variables | |||||
|---|---|---|---|---|---|
| Algorithm | ds | dh | R | L | Function Cost |
| ESCA | 0.8125 | 0.4375 | 42.0983 | 176.6385 | 6059.7344 |
| SCA | 0.8125 | 0.4375 | 42.0799 | 177.0465 | 6066.1710 |
| MSCA | 0.7793 | 0.3996 | 40.3255 | 199.9213 | 5935.7161 |
| IHS | 1.1250 | 0.6250 | 58.2902 | 43.6927 | 7197.7300 |
| GSA | 1.1250 | 0.6250 | 55.9887 | 84.4542 | 8538.8359 |
| PSO | 0.8125 | 0.4375 | 42.0913 | 176.7465 | 6061.0777 |
| GA_1 | 0.8125 | 0.4345 | 40.3239 | 200.0000 | 6288.7445 |
| GA_2 | 0.8125 | 0.4375 | 42.0974 | 176.6541 | 6059.9463 |
| GA_3 | 0.9375 | 0.5000 | 48.3290 | 112.6790 | 6410.3811 |
| ES | 0.8125 | 0.4375 | 42.0981 | 176.6405 | 6059.7456 |
| DE | 0.8125 | 0.4375 | 42.0984 | 176.6377 | 6059.7340 |
| ACO | 0.8125 | 0.4375 | 42.1036 | 176.5727 | 6059.0888 |
| GWO | 0.8125 | 0.4375 | 42.0892 | 176.7587 | 6061.0135 |
| HHO | 0.8176 | 0.4073 | 42.0917 | 176.7196 | 6000.4626 |
| WOA | 0.8125 | 0.4375 | 42.0983 | 176.6390 | 6059.7410 |
| Constraints | ||||
|---|---|---|---|---|
| Algorithm | ||||
| ESCA | −2.81 × | −3.59 × | −5.57 × | −6.34 × |
| SCA | −3.59 × | −3.61 × | −9.97 × | −6.30 × |
| MSCA | −9.75 × | −1.49 × | −1.26 × | −4.01 × |
| IHS | −1.05 × | −6.89 × | 6.57 × | −1.96 × |
| GSA | −4.44 × | −9.09 × | −2.71 × | −1.56 × |
| PSO | −1.39 × | −3.59 × | −1.16 × | −6.33 × |
| GA_1 | −3.42 × | −4.98 × | −3.04 × | −4.00 × |
| GA_2 | −2.02 × | −3.59 × | −2.49 × | −6.33 × |
| GA_3 | −4.75 × | −3.89 × | −3.65 × | −1.27 × |
| ES | −6.92 × | −3.59 × | 2.90 | −6.34 × |
| DE | −6.68 × | −3.59 × | −3.71 | −6.34 × |
| ACO | 9.99 × | −3.58 × | −1.22 | −6.34 × |
| GWO | −1.79 × | −3.60 × | −4.06 × | −6.32 × |
| HHO | −5.21 × | −5.74 × | −6.57 × | −6.33 × |
| WOA | −3.39 × | −3.59 × | −1.25 | −6.34 × |
| Variables | |||||
|---|---|---|---|---|---|
| Algorithm | h | l | t | b | Function Cost |
| ESCA | 0.205727 | 3.470570 | 9.036625 | 0.205730 | 1.724862 |
| SCA | 0.205661 | 3.471731 | 9.037817 | 0.205742 | 1.725213 |
| GSA | 0.182129 | 3.856979 | 10.000000 | 0.202376 | 1.879952 |
| RO | 0.203687 | 3.528467 | 9.004233 | 0.207241 | 1.735344 |
| IHS | 0.203687 | 3.528467 | 9.004233 | 0.207241 | 1.735344 |
| GA_3 | 0.248900 | 6.173000 | 8.178900 | 0.253300 | 2.433100 |
| GWO | 0.205676 | 3.478377 | 9.03681 | 0.205778 | 1.726240 |
| HHO | 0.204039 | 3.531061 | 9.027463 | 0.206147 | 1.731990 |
| WOA | 0.205396 | 3.484293 | 9.037426 | 0.206276 | 1.730499 |
| Constraints | |||||||
|---|---|---|---|---|---|---|---|
| Algorithm | |||||||
| ESCA | −7.80 × | −5.98 × | −3.00 × | −3.43 | −8.07 × | −2.36 × | −3.20 × |
| SCA | −0.699753 | −9.721939 | −0.000081 | −3.432575 | −0.080661 | −0.235547 | −1.602377 |
| GSA | −5.35 × | −5.10 × | −2.02 × | −3.26 | −5.71 × | −2.39 × | −1.33 × |
| RO | −2.24 | −4.13 | −3.55 × | −3.42 | −7.87 × | −2.35 × | −1.24 × |
| IHS | −2.24 | −4.13 | −3.55 × | −3.42 | −7.87 × | −2.35 × | −1.24 × |
| GA_3 | −5.76 × | −2.56 × | −4.40 × | −2.98 | −1.24 × | −2.34 × | −2.39 × |
| GWO | −2.12 × | −8.29 | −1.02 × | −3.43 | −8.07 × | −2.36 × | −4.31 |
| HHO | −6.21 × | 5.72 × | −2.11 × | −3.43 | −7.90 × | −2.36 × | −3.26 × |
| WOA | −2.15 × | −8.48 × | −8.80 × | −3.43 | −8.04 × | −2.36 × | −4.83 × |
| Algorithm | |||||||
|---|---|---|---|---|---|---|---|
| Design Variables | SCA | GA_4 | TLBO | MBA | SDO | HHO | ESCA |
| 125.719015 | 125.717100 | 125.719100 | 125.715300 | 125.700000 | 125.000000 | 125.718960 | |
| 21.425557 | 21.423000 | 21.425590 | 21.423300 | 21.424905 | 21.000000 | 21.425563 | |
| Z | 11.000000 | 11.000000 | 11.000000 | 11.000000 | 11.000000 | 11.090000 | 11.000000 |
| 0.515000 | 0.515000 | 0.515000 | 0.515000 | 0.515002 | 0.515000 | 0.515000 | |
| 0.515000 | 0.515000 | 0.515000 | 0.515000 | 0.515930 | 0.515000 | 0.515000 | |
| 0.490213 | 0.415900 | 0.424266 | 0.488805 | 0.487755 | 0.400000 | 0.465124 | |
| 0.672451 | 0.651000 | 0.633948 | 0.627829 | 0.629992 | 0.600000 | 0.653542 | |
| 0.300000 | 0.300043 | 0.300000 | 0.300149 | 0.300039 | 0.300000 | 0.300000 | |
| e | 0.070763 | 0.022300 | 0.068858 | 0.097305 | 0.053510 | 0.050474 | 0.020149 |
| 0.760058 | 0.751000 | 0.799498 | 0.646095 | 0.665982 | 0.600000 | 0.736634 | |
| Function cost | 81,859.508 | 81,841.511 | 81,859.738 | 81,843.686 | 81,575.185 | 83,011.883 | 81,859.552 |
| Algorithm | |||||||
|---|---|---|---|---|---|---|---|
| Constraints | SCA | GA_4 | TLBO | MBA | SDO | HHO | ESCA |
| 0.000009 | 0.000822 | 0.000004 | 0.000564 | −0.001272 | 0.013477 | 0.000003 | |
| 8.536204 | 13.733000 | 13.152560 | 8.630250 | 8.706960 | 14.000000 | 10.292446 | |
| 4.220456 | 2.724000 | 1.525180 | 1.101430 | 1.249630 | 0.000000 | 2.896814 | |
| 1.376183 | 1.107000 | 2.559350 | −2.040450 | −1.445445 | −3.000000 | 0.673457 | |
| 0.719015 | 0.717100 | 0.719100 | 0.715300 | 0.700000 | 0.000000 | 0.718960 | |
| 16.971735 | 4.857900 | 16.495400 | 23.610950 | 12.677500 | 12.618500 | 4.318290 | |
| 0.000047 | 0.002129 | −0.000022 | 0.000518 | 0.009240 | 0.700000 | 0.000070 | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000002 | 0.000000 | 0.000000 | |
| 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000930 | 0.000000 | 0.000000 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belazi, A.; Migallón, H.; Gónzalez-Sánchez, D.; Gónzalez-García, J.; Jimeno-Morenilla, A.; Sánchez-Romero, J.-L. Enhanced Parallel Sine Cosine Algorithm for Constrained and Unconstrained Optimization. Mathematics 2022, 10, 1166. https://doi.org/10.3390/math10071166
Belazi A, Migallón H, Gónzalez-Sánchez D, Gónzalez-García J, Jimeno-Morenilla A, Sánchez-Romero J-L. Enhanced Parallel Sine Cosine Algorithm for Constrained and Unconstrained Optimization. Mathematics. 2022; 10(7):1166. https://doi.org/10.3390/math10071166
Chicago/Turabian StyleBelazi, Akram, Héctor Migallón, Daniel Gónzalez-Sánchez, Jorge Gónzalez-García, Antonio Jimeno-Morenilla, and José-Luis Sánchez-Romero. 2022. "Enhanced Parallel Sine Cosine Algorithm for Constrained and Unconstrained Optimization" Mathematics 10, no. 7: 1166. https://doi.org/10.3390/math10071166