
A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews
by
 , , , and
, , , and
Sandipan Sahu
1 ,
,
Raghvendra Kumar
1,
Pathan MohdShafi
2,
Jana Shafi
3,
SeongKi Kim
4,* and
Muhammad Fazal Ijaz
5,* 1
Department of Computer Science and Engineering, GIET University, Rayagada 765022, India
2
Department of Computer Science and Engineering, MITADT University, Loni Kalbhor 412201, India
3
Department of Computer Science, College of Arts and Science, Prince Sattam bin Abdul Aziz University, Wadi Ad Dawasir 11991, Saudi Arabia
4
National Centre of Excellence in Software, Sangmyung University, Seoul 03016, Korea
5
Department of Intelligent Mechatronics Engineering, Sejong University, Seoul 05006, Korea
*
Authors to whom correspondence should be addressed.
Mathematics 2022, 10(9), 1568; https://doi.org/10.3390/math10091568
Submission received: 8 April 2022
/
Revised: 24 April 2022
/
Accepted: 3 May 2022
/
Published: 6 May 2022
Abstract
:Movies are one of the integral components of our everyday entertainment. In today’s world, people prefer to watch movies on their personal devices. Many movies are available on all popular Over the Top (OTT) platforms. Multiple new movies are released onto these platforms every day. The recommendation system is beneficial for guiding the user to a choice from among the overloaded contents. Most of the research on these recommendation systems has been conducted based on existing movies. We need a recommendation system for forthcoming movies in order to help viewers make a personalized decision regarding which upcoming new movies to watch. In this article, we have proposed a framework combining sentiment analysis and a hybrid recommendation system for recommending movies that are not yet released, but the trailer has been released. In the first module, we extracted comments about the movie trailer from the official YouTube channel for Netflix, computed the overall sentiment, and predicted the rating of the upcoming movies. Next, in the second module, our proposed hybrid recommendation system produced a list of preferred upcoming movies for individual users. In the third module, we finally were able to offer recommendations regarding potentially popular forthcoming movies to the user, according to their personal preferences. This method fuses the predicted rating and preferred list of upcoming movies from modules one and two. This study used publicly available data from The Movie Database (TMDb). We also created a dataset of new movies by randomly selecting a list of one hundred movies released between 2020 and 2021 on Netflix. Our experimental results established that the predicted rating of unreleased movies had the lowest error. Additionally, we showed that the proposed hybrid recommendation system recommends movies according to the user’s preferences and potentially promising forthcoming movies.
Keywords:
OTT platform; recommendation system; sentiment analysis; hybrid recommendation system; predicted ratingMSC:
94A151. Introduction
In today’s internet-connected world, lots of information is available online. Due to this overpressure of digital content, sometimes users are becoming overwhelmed. A recommendation system helps users to cope with this information explosion. As a result, Amazon, Netflix, other e-commerce platforms, and movie OTT platforms all use a recommendation system.
Recently, movie recommendations have become very popular due to the personalized approach of the user. Currently, people are most comfortable watching movies on their personal devices; as a result, most of the OTT platforms, such as Netflix, Amazon, Disney+, etc., have become very popular [1,2,3]. Recommendation systems can be classified into two broader types: collaborative and content-based filtering methods. Content-based (CBF) works by analyzing and examining the properties of items to make predictions. Collaborative filtering (CF) finds the similarities of different users or items to make predictions about what a particular user may like. CF approaches work based on the wisdom of the viewer. The viewer selected the items they liked most based on their tests and preferences. According to the authors of [4], high sparsity and user–item interaction are significant factors of recommendation systems. The best performance is introduced when content-based filtering (CBF) and collaborative filtering (CF) are both triggered.
CBF and CF have encountered a limitation as a cold start problem [5,6] and sparse rating problem [7,8,9], as many users do not rate items. Therefore, cold start problems are also categorized into two types: the new user cold-start problem and the new item cold-start problem. On the other hand, CBF only suffers from new user problems where no information about their likes/dislikes is available. Moreover, due to sparse user–item rating matrices, nearest neighbors or nearest items can be challenging to identify [10].
To overcome these limitations, comments on different social media platforms, such as YouTube, Twitter, and Quora, have been used [1]. Based on the sentiments in the comments, the content has been analyzed. Most of this research has been performed using sentiment analysis of comments about released movies on social media, but there are still some challenges for upcoming movies. For example, rating information and liking information are not available for impending movies; minimal metadata is available. Due to the scarcity of information, it is challenging to build a recommendation system for a unreleased movie.
In this study, we have developed a recommendation system that can effectively recommend upcoming movies to a user. In addition, we have also proposed a framework to predict the rating of the forthcoming movies using a sentiment analysis of YouTube trailer reviews.
To solve the above problems, first, we randomly selected a list of one hundred movies released between 2020 and 2021 on Netflix; we then scraped the movie trailer comments from the official YouTube channel of Netflix. Then, using the sentiment analysis, we computed the overall sentiment of the movie from the trailer reviews and predicted the rating of the unreleased movie. We also used movie data and movie intrinsic features from the TMDb dataset and new movie sets. Then, by combining the previous movie data and forthcoming movie data, we built a hybrid recommender system to produce a list of preferred upcoming movies. We were then finally able to offer potentially popular forthcoming movies to the user, according to their preferences. Our method fuses the predicted ranking and preferred list of upcoming movies from modules one and two.
Our experimental results show that the predicted rating of unreleased movies has a minimum error. Additionally, we have demonstrated that the proposed hybrid recommendation system recommends movies according to the user’s choices and potentially promising impending movies.
The main contributions of this research are:
- This research work is one of the first studies to build a framework combining sentiment analysis and a hybrid recommendation system for recommending movies that are not yet released, but where only the trailer has been released.
- We also proposed a model that predicts the movie’s rating before the movie’s official release by analyzing the sentiment of comments from trailer videos on YouTube.
- We have proposed a new way of calculating the comprehensive sentiment of a unreleased movie.
- We also proposed a new framework of a hybrid recommendation system, which can recommend an upcoming new movie to a user based on their preferences.
- We have proposed an idea to calculate the weighting of each movie feature in order to calculate the similarity between two movies.
The rest of this paper is arranged as follows. Section 2 summarizes related studies on recommendation systems and sentiment analysis. Section 3 outlines our proposed framework in detail and discusses dataset descriptions. In Section 4, the proposed model is described elaborately. Section 5 presents the experimental results and a comparative study of other statistical models is shown and explained. Finally, in Section 6 our research contributions and their limitations as well as further research directions are discussed.
2. Related Works
In this section, we have presented a detailed survey on related previous studies. Our work includes a recommendation system and sentiment analysis to recommend the preferred items. Recommendation systems are primarily divided into three types [11,12,13,14,15]: collaborative filtering (CF) [16,17,18], content-based filtering (CBF) [19,20], and hybrid filtering [21,22,23]. Sentiment analysis is the mining of textual content to extract the internal information in the content [24,25,26]. These approaches are discussed as follows.
2.1. Recommendation System
CF is a procedure that can refine things that a user might prefer based on responses by similar users. Cold start is one of the significant problems of CF. Yang et al. [27] proposed a system that uses user records to infer ratings. If more the pages are read by a user, then this implies increased interest in the document. This system is helpful in overcoming the problem of cold start but is domain specific. Optimizing the recommendation system is a multidimensional problem. Therefore, various optimization algorithms have been proposed by researchers. Some of these are mentioned as follows. Katarya et al. [28] proposed a recommender system formed on grey wolf optimization and fuzzy c-mean on Movie lens data to predict user ratings. Hsu et al. [29] proposed an artificial bee colony optimization technique to implement a personalized auxiliary material recommendation system. Bobadilla et al. [30] used genetic algorithms to optimize the recommendation system. Ujjin et al. [31] proposed a particle swarm optimization compared with the genetic algorithm. Katarya et al. [32] improved their collaborative movie recommendation system [28] by using an artificial bee colony and k-mean cluster (ABC km). Their proposed system alleviates the cold start problem. Zhang et al. [33] proposed a framework that clusters users based on the user’s profile attributes in order to implement a personalized, collaborative movie recommendation system. This work handles the time complexity concern of CF. Lavanya et al. [34] used implicit feedback and predicted ratings to implement CF. This approach reduces the data sparsity problem. Chen et al. [35] proposed a framework of CF where they built two separate lists for each user, one with the movies they like and the other with their disliked movies.
Content-based filtering (CBF) [19,20,36,37] is a popular and extensively researched recommendation system model. Content-based recommender systems utilize metadata information of items or textual items [38]. Linked open data (LOD) initiation suggests new ideas to extend item information with outside knowledge sources [39,40]. Uluyagmur et al. [41] used a content-based movie recommender that proposed which users and movie features are used. The proposed movie rating system used a movie feature dataset. Content-based movie recommendation systems consider different movie attributes such as movie genre, names of the actors, names of the directors, and other attributes to build a recommender system. Reddy et al. [42] proposed a recommendation system where which movie genre users preferred to watch was used to build a recommender system using the Movie Lens dataset. Correlations between content and attributes are measured to determine the similarity between items. Son et al. [43] proposed a multi-attribute network to calculate correlations and recommend items to users. The similarity between directly or indirectly correlated items is calculated using network analysis. Ali et al. [44] proposed a hybrid model where genomic tags of the movie were used with CBF to recommend movies with similar tastes. Belarbi et al.’s [45] proposed model reduces the computational complexity by using principal component analysis (PCA) and Pearson correlation procedures to reduce redundant tags and dispense a low variance. Elahi et al. [46] leveraged the gap between high-level and low-level features in their study. They have used low-level feature colors, motion exceeds, and lighting from a film to make a hybrid recommendation system. A new movie recommendation system was proposed by Deldjoo et al. [47]. They have addressed the cold start problem for anew item. They have offered audio and visual descriptions extracted from videos and developed a video genome. Breitfuss et al. [48] built a knowledge graph by using user sentiment from existing movies. Based on the knowledge graph, they then developed a recommendation system.
Current research has revealed that the hybrid strategy (HRS) [21,22,23,49,50] is more effective than conventional strategies. In addition, hybrid techniques attenuate the deficiency of individual strategies due to the blend of both recommendation strategies. Melville et al. [51] designed a hybrid recommender system that used advanced content-based features in a collaborative model. This strategy improved the prediction and the sparsity problem. Zhang et al. [52] proposed an HRS using user recommender interaction. Taking input from the user recommended N items, based on the user’s choice, it continues to use the recommender system. Walek et al. [53] proposed an HRS for movie recommendations using a fuzzy expert system. The proposed model uses a user’s preferred and unpreferred genres, while a fuzzy expert system resolves the definitive list of recommended movies. Bahl et al. [54] proposed a hybrid movie recommendation system model combining CBF with CF. The matrix factorization (SVD) technique was used to implement collaborative filtering. Kumar et al. [55] developed a hybrid recommendation system for movies; the proposed system uses CF and CBF and sentiment analysis of tweets. Here, sentiment analysis has been used to determine current trends and user choices. Duan et al. [56] have proposed a hybrid recommendation system to offer users services based on an explicit rating mechanism using latent semantics (LSIER). The system perceives feedback from the users, and the LSIER model generates a list of recommended services.
2.2. Sentiment Analysis
Sentiment analysis [24,25,26,57,58,59] is a procedure for computationally determining and classifying individuals’ sentiments as described in reviews, comments, or surveys as negative, positive, or neutral. Previous research has preliminarily analyzed the user’s textual comments and classified the reviews into negative or positive sentiments. Sun et al. [60] developed a social media recommendation system framework using sentiment analysis. CF usually suffers from data sparsity problems. This work uses the inferred sentiment from the user feedback to improve the performance of the recommendation system. Hui et al. [61] proposed a model that mines users’ social media information from their microblog. Then, the authors analyze the preference information and find the similarity between TV shows and online movies. The presented approach alleviates the cold start problem of the recommendation system. Diao et al. [62] proposed a probabilistic model using CF and topic modeling. They have used IMDB user reviews to track user interest and the distribution of movies’ content. Revealing the user’s interests and information about the movie helps the model create recommendations appropriately. Wang et al. [63] presented a Twitter sentiment analysis model. The model has combined the textual information of Twitter messages and sentiment diffusion patterns to achieve a better performance on sentiment analysis. Social media data can be used to understand user’s characteristics. Dang et al. [64] proposed a recommendation system model that combined sentiment analysis of a users’ social media data with collaborative filtering to achieve better accuracy. Data augmentation has been used to solve data scarcity issues, which affect the performance of deep learning (DL) models. Xiang et al. [65] proposed a lexical substitution for data augmentation (PLSDA) based on part-of-speech (POS) strategies to improve the performance of ML algorithms in sentiment analysis [24,66]. Effective computing and sentiment analysis are emerging research fields that leverage information retrieval, human–computer interaction, and multimodal signal processing to discover people’s sentiments from online social data. Cambria et al. [67] proposed a neuro symbolic framework based on commonsense to overcome the limitations of AI modules in the circumstance of sentiment analysis. They have used reproducible and unsupervised sub symbolic strategies to efficiently convert natural language into a protolanguage that interprets induced sentiment. Most of the studies in sentiment analysis consider only positive and negative sentences. We typically ignore neutral and ambivalence sentences, but in some studies [68,69], neutral or ambivalence sentiments have been used to improve the model’s performance. Sentiment analysis from a conversation [70] is much more complex than single-sentence sentiment analysis, mainly because it presents contextual information. Another fine-grained sentiment analysis is aspect-based. Here, sentiment polarity is determined by a given aspect. Graph convolution neural networks [71,72,73] have been used in aspect-based sentiment analysis.
In most studies, a recommendation system was used for already existing released movies. Recommendation systems for upcoming movies are uncommon. Our proposed model is a hybrid recommendation system for efficiently recommending upcoming movies. First, we have used sentiment analysis to predict the rating of unreleased movies. Then, based on that, we recommend potentially good movies according to the user’s personal preferences.
3. Material and Methods
This study aimed to develop a recommendation system for upcoming new movies based the choices of an individual user with the help of a hybrid recommendation system and sentiment analysis. Specifically, we have used viewer comments from movie trailer videos on YouTube for sentiment analysis.
3.1. Proposed Framework
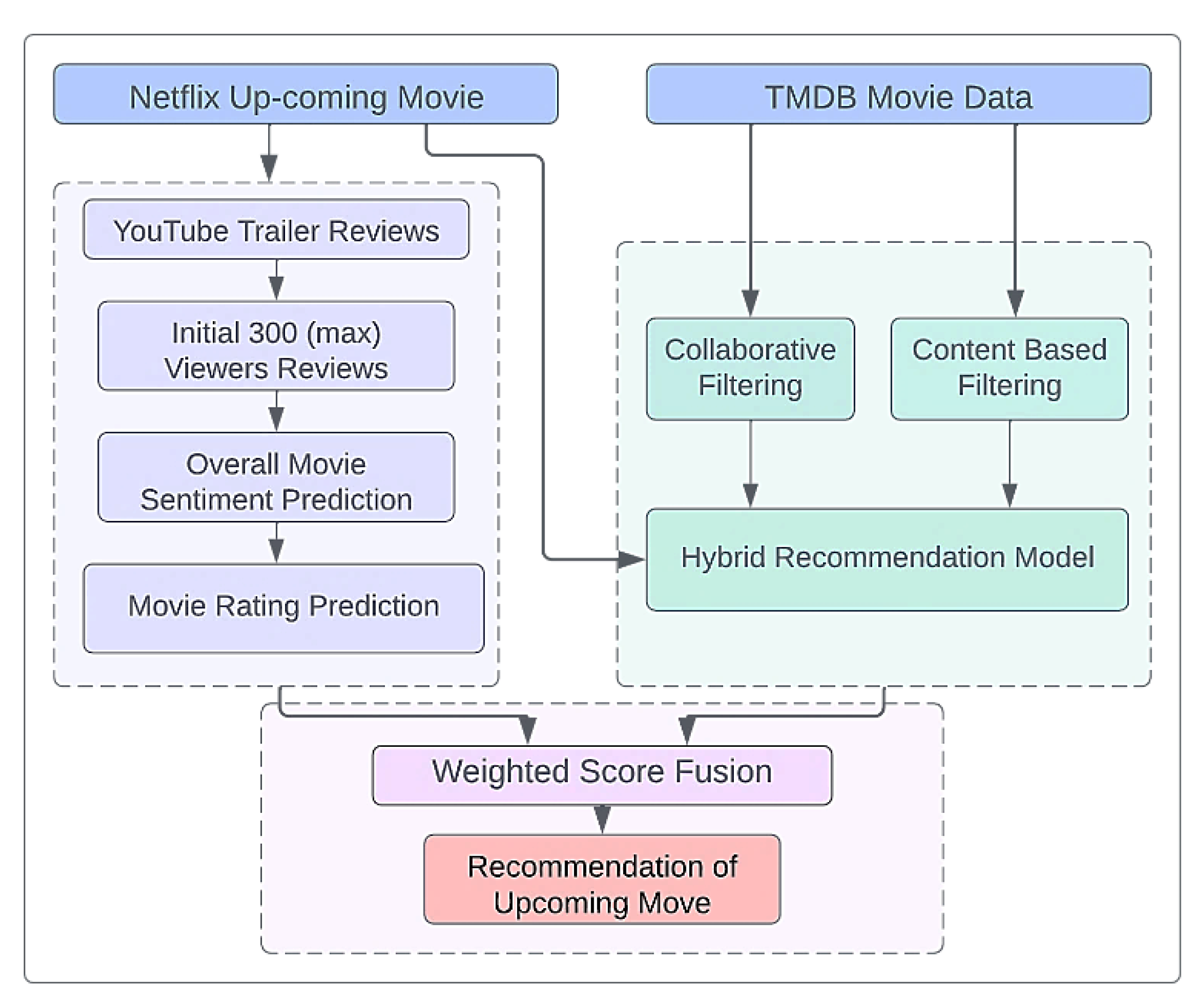
Our proposed system has three significant models, which are described below. Figure 1 shows the proposed framework.
- Movie trailers are usually released well before the release of the actual movie. Forthcoming movie trailers are generally available on YouTube. Viewers share their views about the trailer and express their thoughts regarding the unreleased movie by posting comments on the YouTube trailer video. In our proposed work, module one extracts the movie trailer comments from the official YouTube channel of Netflix. We then compute the overall sentiment and also predict the rating of the forthcoming movie.
- In module 2, our objective is to produce a list of unreleased movies according to the preferences or likes of the individual user. Here, we have used the TMDb dataset, which contains movie metadata and user rating data. Firstly, we compute user preferences using the TMDb user rating dataset. Next, with the help of intrinsic movie data, we have discovered similar movies from the upcoming movie dataset that align with the user’s taste. This module combines the previous and upcoming movies data and builds a hybrid recommendation system in order to produce a list of preferred upcoming movies.
- The first module assesses the popularity of the forthcoming movies by predicting the rating of each new movie. The second module presents a list of new movies closely similar to the user’s existing preferred movies. In the third module, we fuse the predicted ranking and preferred list of forthcoming movies from modules one and two. Finally, we are able to offer potentially popular unreleased movies to the user, according to their preference.
3.2. Dataset Description
The proposed method uses two separate datasets. Firstly, we have created a dataset of 100 movies representing a set of upcoming movies. This dataset consists of YouTube trailer reviews and some basic intrinsic features of each movie. Secondly, we used a publicly available TMDb dataset. The choice of this dataset is due to the presence of movie metadata and user rating data in a single dataset.
3.2.1. YouTube Trailer Review Dataset
In the proposed work, YouTube review data of movie trailers have been used. The objective is to analyze the sentiment of each review to predict the overall sentiment of an upcoming movie. User reviews of each movie trailer are scraped from the official YouTube channel of Netflix.
We randomly selected a list of one hundred movies released between 2020 and 2021 on Netflix. First, official trailers of each movie were identified on the Netflix YouTube channel. Then, we scraped each movie trailer’s initial 300 (max) comments. In this study, comments were taken chronologically from the beginning to obtain initial responses from the viewers. Since movie trailers are published at least 1–2 months before the movie’s official release, the initial comments we are using can be considered to have been given before the movie’s release. Some examples of YouTube trailer review comments of the movie The Starling are shown in Table 1.
We have created a dataset of one hundred movies listed previously. For each movie, we have extracted the IMDb rating, movie genre, cast, director name, and keywords of the movie from the IMDb website (https://www.imdb.com/ accessed on 2 May 2022). The created data set was used as a set of new movies. Table 2 displays movie features and example values of a movie.
3.2.2. TMDb Data Set
Several publicly available popular data sets are used for various recommendation systems. The different experiments were conducted using a movie dataset, such as the IMDb dataset, Movie lens 100 K, Movie lens 20 M, Netflix prize dataset, and TMDb data set.
This work uses the TMDb data set [74] to build a hybrid recommendation system. The dataset contains intrinsic movie features as well as user ratings. Movie features are used to obtain the content-based similarity between two movies, and user ratings are used to obtain the user preferences or choices. In our model, four movie features were used to compare the similarity between the two movies. The selected features are movie genre, director, cast (three primary cast members), and keywords. In addition, we also used IMDb movie ratings for collaborative filtering.
4. Experimental Methods
4.1. Analysis of Review Data
The scraping of YouTube comments was performed using Google script. For each movie trailer, 300 viewer comments from the beginning were scraped. All the selected movies were released on Netflix. Therefore, the trailer of each movie was released on the official YouTube channel of Netflix before the original movie’s release. As shown in Table 1, extracted review comments have tremendous noise, such as emojis, repetitive words, symbols, and other event data. Therefore, all the comments need to be cleaned using several preprocessing steps. Figure 2 shows the steps of data analysis.
4.1.1. Preprocessing of Review Data
To perform the sentiment analysis properly, data cleaning and preprocessing are necessary. In data cleaning, noise is removed by deleting the noise, and in the preprocessing step, the noise is cleaned by correcting the data. In the proposed work, data cleaning and data preprocessing have been performed to create purified review comments machine-understandable.
Multiple steps have been performed to clean the data, such as: removing emoji symbols, deleting words with only consonants, and deleting words with more than three repetitive and consecutive consonants and vowels. We also removed consecutive whitespaces. It is important to delete all the stop words. We deleted all unusable data, as shown in Table 3, which add no value in sentiment analysis. In the preprocessing part, lemmatization is one of the significant steps.
4.1.2. Sentiment Analysis
We have used VADER from the nltk sentiment analyzer to determine the sentiment’s polarity of each review comment. The VADER measures the intensity of each word of the review and determines the overall sentiment of the comments. For each comment, it produces values of four components of sentiment. The initial three components are positive, neutral, and negative. The value lies between [0, 1]. The fourth component is the compound score—the normalized value of positive, negative, and neutral scores. The domain value of the compounds score is between [–1, 1]. Where +1 represents extreme positive sentiment, and −1 represents extreme negative sentiment. Compounds with a score greater than zero (>0) classify the comment as a positive sentiment. Similarly, a lower compound score of less than zero (<0) is a comment with negative sentiment. Table 4 shows the values of four parameters for some example comments.
Overall Sentiment Score (os): In order to determine the overall sentiment of the movie from the individual comments, we have used the compound score (cs) of each comment. If the compound score of a review is zero (cs = 0), this means the review holds a completely neutral sentiment. Neutral sentiment adds nothing to the positivity or negativity of the movie. Therefore, we dropped all the reviews with cs = 0. Next, we calculated the overall sentiment of a movie by taking the average of all the non-zero compound scores (cs). Equation (1) shows how to calculate .
In the equation, is the total number of reviews () of the movie for which . The overall score ranges between [−1, 1].
Predicted Rating (pr): In this study, we calculated each movie’s predicted rating from the overall sentiment that was computed earlier. The Overall sentiment is scaled in the range [1, 10] using Equation (2). Table 5 shows some examples of the overall score and the predicted rating .
4.2. Hybrid Recommendation System
In the proposed work, a forthcoming movie is recommended to the user considering their preferences. Therefore, we have designed a hybrid recommendation system (HRS) model that combines collaborative and content-based filtering. We have shown the basic framework of the proposed HRS in Figure 3. Initially, a user-preferred list is created. Next, we find the similarity between new movies and that preferred movie set. Finally, we fuse the similarity score, predicted rating, and the rating of preferred movies to make a final recommendation of upcoming movies (Algorithm 1).
| Algorithm 1: Hybrid Recommendation System for up-coming Movie Recommendations. |
| Input: Set of Users Set of Movies Set of New Movies User Rating Matrix Movie Feature vector Feature Weight vector IMDb Rating of all movies Predicted Rating of all new movies Output: Recommendmost promising upcoming movies according to the preference .
|
In this study, we have used a user rating matrix , where set of users and is a set of existing movies. We then generated a preferred movie list of movies of each user . Next, considering the preferred list and a user , taking each movie from the list we can find similar movies from the set of new movies . For each preferred movie we have considered as the most similar new movies . In this manner, we created a pool of movies . is a potential set of new movies for recommendation to the user . Finally, we can make a final recommendation by fusing the weighted scores.
Movie similarity: The similarity between two movies is determined by using movie metadata. Let and representthe feature vector of the movie and weight vector, respectively. The computed similarity between any two movies and concerning the feature as:
The similarity between two movies is measured by combining the distance of features. All the features do not have the same priority. We also have an dimensional weight vector . Equation (3) computed the cosine similarity of the feature values between two movies and . We have used cosine similarity to find the distance. The overall similarity between the two movies and is computed using Equation (4).
Features weight (): To compute the weight vector , we have used user preferences. Let where is a set of users. is a set of ,the most preferred movies of the user . In the same way is the collection of the preferred movie set of all users . Considering each user and the preferred set of movies we have discovered the importance of each movie feature. In this process, we first calculated the similarity between two movies concerning feature .
Equation (5) determines the total similarity value of the feature for the user . Next, in Equation (6) we can determine the total similarity value of a feature among all users . This has been carried forward and generated as the vector having a total similarity value of each feature , considering all users .
In the vector , a higher value implies greater importance of the feature. Similarly, less essential features have a lower value. We have determined the feature weight vector by normalizing the value of , and can thus generate .
4.3. Weighted Score Fusion
In this work, our objective is to recommend new movies that should match three primary criteria: (1) Recommended new movie must be a potentially good movie. (2) has significant similarity with . (3) Existing preferred movie needs to be a good movie (with a higher IMDb rating). Using the sentiment analysis of the review comments, we have tried to figure out potential hit movies. We have assigned a predicted rating to each of the new films .Using the hybrid recommendation system, we have been able to obtain the user’s choice and find similar films from the set of new movies, thus creating a pool of movies for each user . Each of the new movies is similar to the movie and the similarity is measured by .
To make the final recommendation to the user , we have used predicted rating of the new movie and the IMDb rating of the corresponding similar movie . We have then fused these two ratings using the similarity score . We have used Equation (8) to compute the combined score of the new movie .
According to the combined movies are selected to make a final recommendation to the user .
5. Result and Discussion
5.1. New Movie Rating Prediction
We randomly selected one hundred movies released on Netflix in the proposed work from 2020 to 2021. We scraped comments from the official Netflix YouTube channel from each selected movie trailer. We analyzed each comment and predicted the movie’s overall rating, as discussed in Section 4.1.The movie’s rating was predicted by using the Vader lexicon and TextBlob lexicon models. Table 6 has taken some of the example movies and shows that the Vader model’s prediction is comparatively better than TextBlob. Vader predictions were much closer to the IMDB rating than the TextBlob model.
From Figure 4, we can observe the performance of the Vader model and TextBlob. The presented performance results are computed considering all the selected movies. Vader performs significantly better in mean square error, R2-score, root mean square error, and mean absolute error.
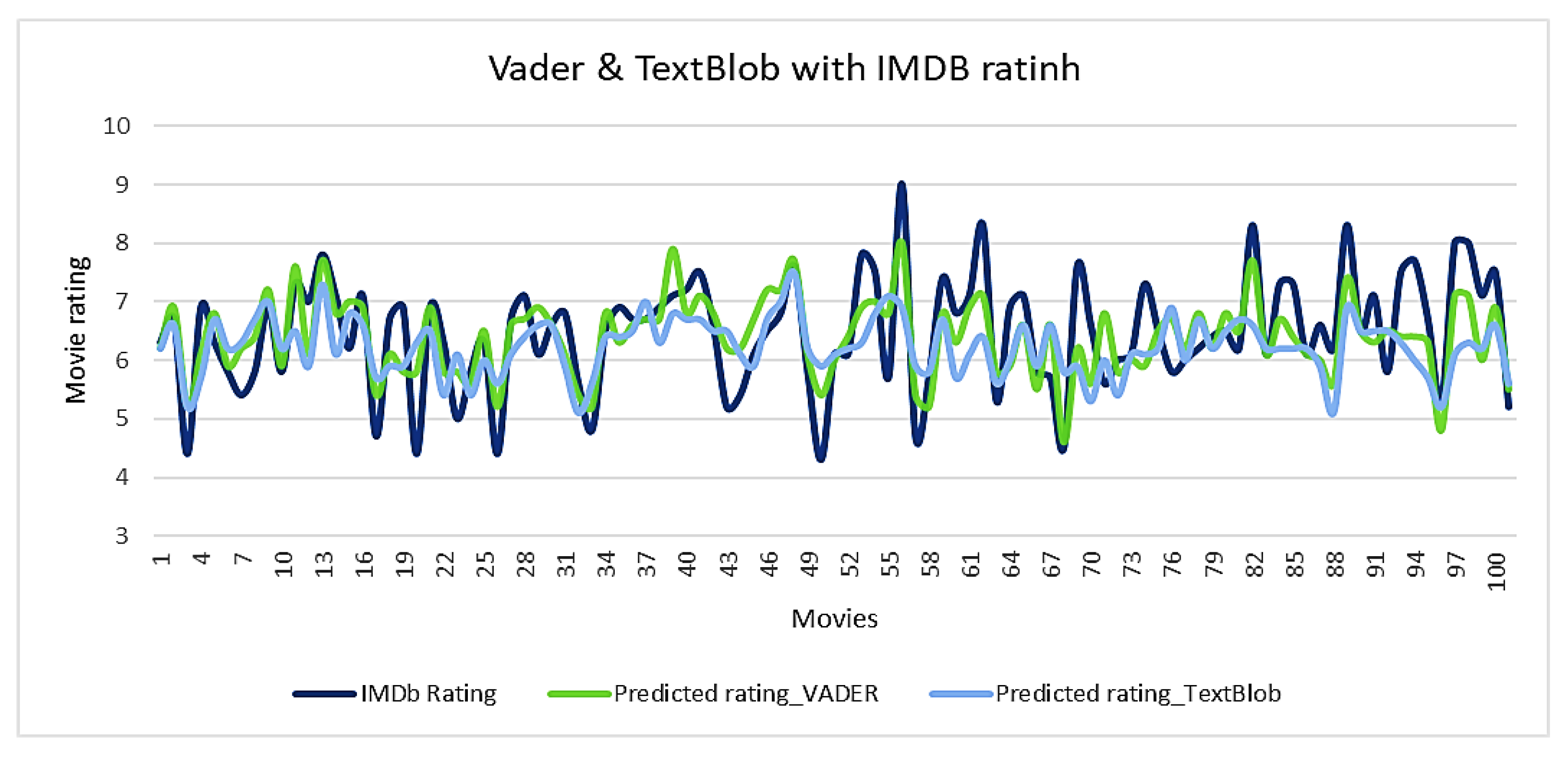
Figure 5 plotted the IMDb rating, Vader, and TextBlob predicted ratings for all 100 movies. The graph shows that both models are performing moderately well in general. However, the IMDB rating is drastically low for some specific movies, such as movie number 50. In those cases, Vader performs better than the TextBlob model. Again, for movies number 55 and 60 the IMDB ratings are significantly higher than average. We can observe in the graph that the Vader model is also performing better here than the other model.
5.2. Movie Similarity
At first, we analyzed how content-based movie similarity performed. The similarity between two movies is computed using Equation (4) after calculating the similarity distance from each parameter. Table 7 shows similar movies to the movie The Terminator. Table 7 presents the 10 most similar movies to The Terminator and we also calculated the overall similarity from the selected movie to each of the similar movies. Additionally, we presented the genre and director of each of the listed movies. The similarity distance between two movies defines the similarity between them. According to the computation, Terminator 2 is the most similar movie to The Terminator. The measured overall similarity is 0.7319 (73.19% similar); this is the minimum score among all the movies. The genres of the movie The Terminator are action, thriller, and science fiction. All the selected movies are also mostly grouped in the same genres. The director of the first four listed movies is “James Cameron”, who is also the director of The Terminator. Table 8 lists similar movies to the film American Beauty. The genre of the movie is drama. Here, all listed movies also have the same genre. The overall calculated similarity values are also shown in Table 8. According to the system, Revolutionary Road is the most similar movie to American Beauty, and the overall similarity distance is 0.4512 (i.e., 45.12% similar). Here, again, we can see that “Sam Mendes” is the director of the film American Beauty and the director of the top four similar movies listed in Table 8.
5.3. Hybrid Recommender System
In this section, we analyzed our proposed hybrid recommendation system (HRS). Our objective is to recommend potentially good upcoming movies according to each user’s previously liked movies. At first, we selected user 6 (u_6) randomly from the TMDB (user_rating) dataset. According to the dataset, u_6 had rated a total of 44 movies. Users can rate a movie between 5 and 0.5. Table 9 shows the rating distribution of the user u_6.
We considered only the top-rated (rating 5) movies of the user. User had only four movies with a rating of 5. Table 10 presents the list of the four movies that were used to create the user’s preferred movie list specifically forthe user . All the selected movies have almost the same genres: adventure, action, and drama.
Next, we computed the similar movies from the set of new movies for each preferred movie. We have taken the five most similar movies of each preferred movie. In our new movie dataset we have 100 movies. From the set of those one hundred movies, we have created a pool of twenty movies . Table 11, Table 12, Table 13 and Table 14 present the five most similar movies of each preferred movie in Table 10.
Table 11 presents the five similar movies to the film The Lord of the Rings: The Return of the King. The genres of this movie are adventure, fantasy, and action. All the selected movies are also within the same genres. The most similar movies are Jaguar and Project Power, and the similarity score is 0.2041. In Table 11, we have also shown the predicted ratings calculated by VADER of each new movie . We also presented a combined score of each prereleased movie.
Table 12 presents five similar movies to the film Taxi Driver. The genres of the movie are crime and drama. All the selected movies also within the same genres. Here, the similarity scores are identical for all the selected movies, but the combined scores are different. The movie The Trial of the Chicago 7 has the highest cs because it has the highest predicted rating ). Movie numbers 4 and 5 have the lowest because they have lowest .
Table 13 presents the five most similar movies to Lawrence of Arabia. The genres of the movie are adventure, drama, history, and war. The most similar movie has two genres in common with Lawrence of Arabia: adventure and drama. The other four movies only have one common genre: drama. The movie Two Distant Strangers has the lowest score; therefore, it hasthe lowest .
Table 14 presents five similar movies to The Lord of the Rings: The Two Towers. The movies The Lord of the Rings: The Return of the King and The Lord of the Rings: The Two Towers are highly similar with similarity score (0.8231). Therefore, they have generated the same list from the new movie set. However, the IMDb rating of The Lord of the Rings: The Return of the King (9) is slightly higher than The Lord of the Rings: The Two Towers (8.8), which affects the combined scores as shown in Table 11 and Table 14. For example, the movie Jaguar has a in Table 11 of 3.1639 and in Table 14 the same movie has a of 3.1230.
5.4. Combined Score (CS)
We have produced a collection of movies, as a potential set of new movies for recommendation to the user . Next, we can make the final selection by computing the combined score using weighted score fusion (WSF), as shown in Equation (8). To implement a WSF, we need the predicted rating of each new movie, the IMDB rating of each preferred movie, and the similarity score . We have computed the compound score (cs) of each movie in . Next, we sort the movies according to their compound score (cs). Finally, we have made a final selection. Table 15 presents ten movies, which are finally recommended to the user . The recommended movies satisfy the preference of the user and also are all potentially good movies taken from all the available movies. In Table 15, we can observe that all the selected movies have high similarity scores and predicted ratings among all the movies in .
.
Figure 6 plots the combined score (cs) and the similarity scores (ss). The figure shows that the combined score and similarity score are directly proportionate. Therefore, with the increasing value of the similarity score, cs also increase. However, again, the increment of the combined score is not the same for all movies, and it depends on the predicted rating of new movies and the IMDB rating of the corresponding old movie. In the figure, scattered vertical lines indicate the difference between and , which affects the value of cs.
Figure 7 plots the normalized value of the combined score (cs) with the similarity score (ss) and the predicted rating (pr). We have scaled the values between 1 to 0. Figure 7 shows that the cs changes with the value of sc. Next, we plotted the decreasing similarity score value. Figure 7 shows that the combined score decreases with the decreasing value of sc. One important thing that needs to be noticed is that cs is also influenced by the value of the predicted rating (pr). From movies number 3 to 8, the similarity scores remain constant, but the combined score constantly decreases with the decreasing value of the predicted rating. Again, for movie 9, cs increases as the value of pr increases. This shows that the predicted rating also influences the value of the combined score.
5.5. Qualitative Analysis
This section compares our proposed hybrid recommendation system with IMDb, TMDb recommendation system, and the model offered by Kumar et al. [55]. Although we have worked with only unreleased movies, we simulated our proposed hybrid recommendation system using the existing TMDb dataset to compare the current models qualitatively.
The Hollywood movie Wonder Woman was often recommended all the earlier systems. The movie’s genres are action, adventure, animation, and science fiction. The movie’s director is Lauren Montgomery and the IMDb rating is 7.2. Table 16 presents the recommended movies by our proposed HRS. Table 17 and Table 18 show the recommended movies according to the IMDb and TMDb recommendation systems. Table 19 presents the recommended movies according to Kumar et al.’s model [55]. Movies in bold in Table 16 intersect with at least one of the other tables.
In Table 17, movies recommended by IMDb are all very similar to the movie Wonder Woman. We can observe that the movies in Table 16 and Table 17 are closely related. However, movies such as Suicide Squad have a low IMDb rating, which is not present in Table 16. Similarly, in Table 18 and Table 19, several movies do not have satisfactory IMDb ratings. Movies such as Kong: Skull Island, Life, Warcraft, and Batman and Harley Quinn are not high-quality movies according to IMDb ratings. All these films mentioned above are not included in Table 16. The average IMDb rating of all the movies listed in Table 16 is 7.4, which is highest among all there commendation systems. The average rating for the movies in Table 17 is 7.18, in Table 18 the average rating is 7.06, and Table 19 the average rating is 6.72—which is lowest among all the recommendation systems. Wonder Woman is an animated movie; most of the films (6 out of 10) recommended by our system in Table 16 are also animated movies. In Table 17 and Table 18 only two animated movies are listed. Table 19 has four animated movies. Movies such as Life and Baby Driver present in Table 18 are not similar to the animated movie Wonder Woman. Our proposed model recommended all the movies with high similarity and high IMDb ratings.
6. Conclusions and Future Works
The best method for information filtering is the recommendation system. Currently, this method is commonly used for handling vast amounts of data and meaningful mapping with the user. Our focus is on movie recommendations of forthcoming movies based on sentiment analysis of a user’s social media. In our proposed model, we extracted the movie trailer comments from the official YouTube channel of Netflix. Then, we computed the overall sentiment and predicted an unreleased movie’s rating. Secondly, we accepted movie data and a movie’s intrinsic features from the TMDb dataset. Then, we combined the previous movie data and impending movie data by building a hybrid recommender system to produce a list of preferred upcoming movies. For sentiment analysis, we chose the Vader and TextBlob approaches where we predicted the Vader rating and TextBlob rating. When compared to the IMDB rating, an import factor was found. In most cases, Vader and TextBlob predictions showed accurate results, but in this experiment we found movie numbers 50, 55, and 60 showed some different results. This experiment only scraped YouTube comments from the official channel of Netflix in the English language. Furthermore, future studies could experiment with different social media platforms such as Twitter, etc., with other cross-lingual comments, could include more frequent access keywords such as “Lol” and ” Omg”, and could also consider emojis.
Author Contributions
Conceptualization, S.S., R.K. and P.M.; methodology, J.S., S.K. and M.F.I.; software, S.S., R.K. and P.M.; validation J.S., S.K. and M.F.I.; formal analysis, S.S., R.K., P.M., J.S., S.K. and M.F.I.; investigation and resources, P.M.; data duration, writing—review and editing, and visualization, S.S., R.K., P.M., J.S., S.K. and M.F.I.; supervision, S.K. and M.F.I.; project administration, S.K. and M.F.I.; funding acquisition, S.K. and M.F.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the MSIT (Ministry of Science, ICT), Korea, under the National Program for Excellence in SW, supervised by the IITP (Institute of Information & communications Technology Planning& Evaluation) in 2022(2019-0-01880).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
Jana Shafi would like to thank the Deanship of Scientific Research, Prince Sattam bin Abdul Aziz University, for supporting this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Carrer-Neto, W.; Hernández-Alcaraz, M.L.; Valencia-García, R.; García-Sánchez, F. Social knowledge-based recommender system. Application to the movies domain. Expert Syst. Appl. 2012, 39, 10990–11000. [Google Scholar] [CrossRef] [Green Version]
- Winoto, P.; Tang, T.Y. The role of user mood in movie recommendations. Expert Syst. Appl. 2010, 37, 6086–6092. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September2016; pp. 233–240. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30October2008; pp. 931–940. [Google Scholar]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15August 2002; pp. 253–260. [Google Scholar]
- Ma, H.; Zhou, T.C.; Lyu, M.R.; King, I. Improving recommender systems by incorporating social contextual information. ACM Trans. Inf. Syst. (TOIS) 2011, 29, 1–23. [Google Scholar] [CrossRef]
- Sarwar, B.M. Sparsity, Scalability, and Distribution in Recommender Systems; University of Minnesota: Minneapolis, MN, USA, 2001. [Google Scholar]
- Huang, Z.; Chen, H.; Zeng, D. Applying associative retrieval techniques to alleviate the sparsity problem in collaborative filtering. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 116–142. [Google Scholar] [CrossRef] [Green Version]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Lu, Z.; Dou, Z.; Lian, J.; Xie, X.; Yang, Q. Content-based collaborative filtering for news topic recommendation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Sharma, L.; Anju, G. A survey of recommendation system: Research challenges. Int. J. Eng. Trends Technol. (IJETT) 2013, 4, 1989–1992. [Google Scholar]
- Das, N.; Borra, S.; Dey, N.; Borah, S. Social networking in web based movie recommendation system. In Social Networks Science: Design, Implementation, Security, and Challenges; Springer: Cham, Switzerland, 2018; pp. 25–45. [Google Scholar]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Shani, G.; Gunawardana, A. Evaluating recommendation systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 257–297. [Google Scholar]
- Melville, P.; Sindhwani, V. Recommender systems. Encycl. Mach. Learn. 2010, 1, 829–838. [Google Scholar]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 77–118. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Lops, P.; Gemmis, M.D.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 73–105. [Google Scholar]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web; Springer: Heidelberg/Berlin, Germany, 2007; pp. 325–341. [Google Scholar]
- Burke, R. Hybrid recommender systems: Survey and experiments. User Modeling User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web; Springer: Heidelberg/Berlin, Germany, 2007; pp. 377–408. [Google Scholar]
- Paradarami, T.K.; Bastian, N.D.; Wightman, J.L. A hybrid recommender system using artificial neural networks. Expert Syst. Appl. 2017, 83, 300–313. [Google Scholar] [CrossRef]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017; pp. 1–10. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Yang, C.; Wei, B.; Wu, J.; Zhang, Y.; Zhang, L. CARES: A ranking-oriented CADAL recommender system. In Proceedings of the 9th ACM/IEEE-CS Joint Conference on Digital Libraries, New York, NY, USA, 15–19 June2009; pp. 203–212. [Google Scholar]
- Katarya, R.; Verma, O.P. Recommender system with grey wolf optimizer and FCM. Neural Comput. Appl. 2018, 30, 1679–1687. [Google Scholar] [CrossRef]
- Hsu, C.C.; Chen, H.C.; Huang, K.K.; Huang, Y.M. A personalized auxiliary material recommendation system based on learning style on Facebook applying an artificial bee colony algorithm. Comput. Math. Appl. 2012, 64, 1506–1513. [Google Scholar] [CrossRef] [Green Version]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Alcalá, J. Improving collaborative filtering recommender system results and performance using genetic algorithms. Knowl.-Based Syst. 2011, 24, 1310–1316. [Google Scholar] [CrossRef]
- Ujjin, S.; Bentley, P.J. Particle swarm optimization recommender system. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium, SIS’03 (Cat. No. 03EX706), Indianapolis, IN, USA, 26 April 2003; pp. 124–131. [Google Scholar]
- Katarya, R. Movie recommender system with metaheuristic artificial bee. Neural Comput. Appl. 2018, 30, 1983–1990. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Yuan, Z.; Jin, Q. Personalized real-time movie recommendation system: Practical prototype and evaluation. Tsinghua Sci. Technol. 2019, 25, 180–191. [Google Scholar] [CrossRef]
- Lavanya, R.; Bharathi, B. Movie Recommendation System to Solve Data Sparsity Using Collaborative Filtering Approach. Trans. Asian Low-Resour. Lang. Inf. Processing 2021, 20, 1–14. [Google Scholar] [CrossRef]
- Chen, Y.L.; Yeh, Y.H.; Ma, M.R. A movie recommendation method based on users’ positive and negative profiles. Inf. Processing Manag. 2021, 58, 102531. [Google Scholar] [CrossRef]
- Philip, S.; Shola, P.; Ovye, A. Application of content-based approach in research paper recommendation system for a digital library. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 37–40. [Google Scholar] [CrossRef] [Green Version]
- Viard, T.; Fournier-S’niehotta, R. Movie rating prediction using content-based and link stream features. arXiv 2018, arXiv:1805.02893. [Google Scholar]
- Belkin, N.J.; Croft, W.B. Information filtering and information retrieval: Two sides of the same coin? Commun. ACM 1992, 35, 29–38. [Google Scholar] [CrossRef]
- Di Noia, T.; Mirizzi, R.; Ostuni, V.C.; Romito, D.; Zanker, M. Linked open data to support content-based recommender systems. In Proceedings of the 8th International Conference on Semantic Systems, Graz, Austria, 5–7 September 2012; pp. 1–8. [Google Scholar]
- Musto, C.; Lops, P.; de Gemmis, M.; Semeraro, G. Semantics-aware recommender systems exploiting linked open data and graph-based features. Knowl.-Based Syst. 2017, 136, 1–14. [Google Scholar] [CrossRef]
- Uluyagmur, M.; Cataltepe, Z.; Tayfur, E. Content-based movie recommendation using different feature sets. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 24–26 October 2012; Volume 1, pp. 17–24. [Google Scholar]
- Reddy, S.R.S.; Nalluri, S.; Kunisetti, S.; Ashok, S.; Venkatesh, B. Content-based movie recommendation system using genre correlation. In Smart Intelligent Computing and Applications; Springer: Singapore, 2019; pp. 391–397. [Google Scholar]
- Son, J.; Kim, S.B. Content-based filtering for recommendation systems using multiattribute networks. Expert Syst. Appl. 2017, 89, 404–412. [Google Scholar] [CrossRef]
- Ali, S.M.; Nayak, G.K.; Lenka, R.K.; Barik, R.K. Movie recommendation system using genome tags and content-based filtering. In Advances in Data and Information Sciences; Springer: Singapore, 2018; pp. 85–94. [Google Scholar]
- Belarbi, M.A.; Mahmoudi, S.; Belalem, G. PCA as dimensionality reduction for large-scale image retrieval systems. Int. J. Ambient. Comput. Intell. (IJACI) 2017, 8, 45–58. [Google Scholar] [CrossRef] [Green Version]
- Elahi, M.; Deldjoo, Y.; Bakhshandegan Moghaddam, F.; Cella, L.; Cereda, S.; Cremonesi, P. Exploring the semantic gap for movie recommendations. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 326–330. [Google Scholar]
- Deldjoo, Y.; Dacrema, M.F.; Constantin, M.G.; Eghbal-Zadeh, H.; Cereda, S.; Schedl, M.; Ionescu, B.; Cremonesi, P. Movie genome: Alleviating new item cold start in movie recommendation. User Modeling User-Adapt. Interact. 2019, 29, 291–343. [Google Scholar] [CrossRef] [Green Version]
- Breitfuss, A.; Errou, K.; Kurteva, A.; Fensel, A. Representing emotions with knowledge graphs for movie recommendations. Future Gener. Comput. Syst. 2021, 125, 715–725. [Google Scholar] [CrossRef]
- Aslanian, E.; Radmanesh, M.; Jalili, M. Hybrid recommender systems based on content feature relationship. IEEE Trans. Ind. Inform. 2016. [Google Scholar] [CrossRef]
- Porcel, C.; Tejeda-Lorente, A.; Martínez, M.A.; Herrera-Viedma, E. A hybrid recommender system for the selective dissemination of research resources in a technology transfer office. Inf. Sci. 2012, 184, 1–19. [Google Scholar] [CrossRef]
- Melville, P.; Mooney, R.J.; Nagarajan, R. Content-boosted collaborative filtering for improved recommendations. In Proceedings of the Eighteenth National Conference on Artificial Intelligence (AAAI-2002), Edmonton, Canada, 28 July–1 August 2002; Volume 23, pp. 187–192. [Google Scholar]
- Zhang, H.R.; Min, F.; He, X.; Xu, Y.Y. A hybrid recommender system based on user-recommender interaction. Math. Probl. Eng. 2015, 2015, 145636. [Google Scholar] [CrossRef] [Green Version]
- Walek, B.; Fojtik, V. A hybrid recommender system for recommending relevant movies using an expert system. Expert Syst. Appl. 2020, 158, 113452. [Google Scholar] [CrossRef]
- Bahl, D.; Kain, V.; Sharma, A.; Sharma, M. A novel hybrid approach towards movie recommender systems. J. Stat. Manag. Syst. 2020, 23, 1049–1058. [Google Scholar] [CrossRef]
- Kumar, S.; De, K.; Roy, P.P. Movie recommendation system using sentiment analysis from microblogging data. IEEE Trans. Comput. Soc. Syst. 2020, 7, 915–923. [Google Scholar] [CrossRef]
- Duan, L.; Gao, T.; Ni, W.; Wang, W. A hybrid intelligent service recommendation by latent semantics and explicit ratings. Int. J. Intell. Syst. 2021, 36, 7867–7894. [Google Scholar] [CrossRef]
- Prabowo, R.; Thelwall, M. Sentiment analysis: A combined approach. J. Informetr. 2009, 3, 143–157. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Wang, G.; Cheng, X.; Fu, Y. Mining affective text to improve social media item recommendation. Inf. Processing Manag. 2015, 51, 444–457. [Google Scholar] [CrossRef]
- Li, H.; Cui, J.; Shen, B.; Ma, J. An intelligent movie recommendation system through group-level sentiment analysis in microblogs. Neurocomputing 2016, 210, 164–173. [Google Scholar] [CrossRef]
- Diao, Q.; Qiu, M.; Wu, C.Y.; Smola, A.J.; Jiang, J.; Wang, C. Jointly modeling aspects, ratings and sentiments for movie recommendation (JMARS). In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August2014; pp. 193–202. [Google Scholar]
- Wang, L.; Niu, J.; Yu, S. SentiDiff: Combining textual information and sentiment diffusion patterns for Twitter sentiment analysis. IEEE Trans. Knowl. Data Eng. 2019, 32, 2026–2039. [Google Scholar] [CrossRef]
- Dang, C.N.; Moreno-García, M.N.; Prieta, F.D.L. An Approach to Integrating Sentiment Analysis into Recommender Systems. Sensors 2021, 21, 5666. [Google Scholar] [CrossRef] [PubMed]
- Xiang, R.; Chersoni, E.; Lu, Q.; Huang, C.R.; Li, W.; Long, Y. Lexical data augmentation for sentiment analysis. J. Assoc. Inf. Sci. Technol. 2021, 72, 1432–1447. [Google Scholar] [CrossRef]
- Cambria, E. Affective Computing and Sentiment Analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Liu, Q.; Decherchi, S.; Xing, F.; Kwok, K. SenticNet 7: A Commonsense-based Neurosymbolic AI Framework for Explainable Sentiment Analysis. LREC. 2022. Available online: https://sentic.net/publications/#sentiment-analysis (accessed on 2 May 2022).
- Wang, Z.; Ho, S.B.; Cambria, E. Multi-level fine-scaled sentiment sensing with ambivalence handling. Int. J. UncertainFuzziness Knowl.-Based Syst. 2020, 28, 683–697. [Google Scholar] [CrossRef]
- Valdivia, A.; Luzón, M.V.; Cambria, E.; Herrera, F. Consensus vote models for detecting and filtering neutrality in sentiment analysis. Inf. Fusion 2018, 44, 126–135. [Google Scholar] [CrossRef]
- Li, W.; Shao, W.; Ji, S.; Cambria, E. BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis. Neurocomputing 2022, 467, 73–82. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Zhao, M.; Yang, J.; Zhang, J.; Wang, S. Aggregated graph convolutional networks for aspect-based sentiment classification. Inf. Sci. 2022, 600, 73–93. [Google Scholar] [CrossRef]
- Dai, A.; Hu, X.; Nie, J.; Chen, J. Learning from word semantics to sentence syntax by graph convolutional networks for aspect-based sentiment analysis. Int. J. Data Sci. Anal. 2022, 1–10. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/tmdb/tmdb-movie-metadata (accessed on 2 May 2022).
Figure 1.
Framework workflow.

Figure 2.
Framework of review data analysis.

Figure 3.
Framework of proposed hybrid recommendation system.

Figure 4.
Comparative analysis of prediction error between Vader and TextBlob lexicons.

Figure 5.
Comparison between Predicted rating by Vader and TextBlob and IMDb rating.

Figure 6.
Relation between combined score and similarity score.

Figure 7.
Relation between combined score with similarity score andpredicted rating.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Example of YouTube trailer review comments of the movie The Starling.
| Reviewer Name | Comments | Time |
|---|---|---|
| Helen and Lolly | This film is going to break my heart. I can never have children. I have a long term illness. 😞 | 2021-09-06T16:00:12Z |
| Christina Watkins | Finally, a good Netflix movie trailer!!! Cannot wait to see Melissa play a more serious role ✨💕 | 2021-09-06T18:01:37Z |
| Samantha Richele | I'm already crying and it was just the trailer. 🥺😭 | 2021-09-07T00:57:40Z |
Table 2.
Example of movie features extracted.
| Features | Value |
|---|---|
| Original title | The Starling |
| IMDb Rating | 6.3 |
| Director | Theodore Melfi |
| Cast | Melissa McCarthy, Chris O’Dowd, Kevin Kline |
| Release Year | 2021 |
| Genres | Comedy, Drama |
| Keywords | woman adjusting life loss contends feisty bird garden husband who’s struggling find forward |
Table 3.
Example of types of noise in the review comments.
| Type of Noise | Example |
|---|---|
| Stop words | The, an, a, in, are, as, at, be |
| Words more than three same consecutive latter | 2pacccccccccccc is better perioddddddddddddd baby baby stole pacs style babyyyyyyyyyyyyyyyyyyy |
| Weblink | May I know the background music name from <ahref=“https://www.youtube.com/watch?v=n4Uv5VHRDZg&t=0m33s”>0:33</a>❤......I just love it! |
| Special characters | #, @, !, $, %, …** |
| Emojis | 😂🤣❤□👍❤□ |
Table 4.
Values of four parameters of some example comments.
| Cleaned Comments | Positive | Neutral | Negative | Compound Score |
|---|---|---|---|---|
| looks really good hope movie trailerjitniacchi | 0.515 | 0.485 | 0 | 0.7485 |
| waste your time this boring chaotic with a stupid ending | 0 | 0.294 | 0.706 | −0.9006 |
| basically, Netflix does not want people to sleep alwaysbinge-watching | 0.14 | 0.86 | 0 | 0.0772 |
Table 5.
Examples of some overall scores, predicted ratings, and IMDb ratings.
| Movie Name | Overall Sentiment | Predicted Rating | IMDb Rating |
|---|---|---|---|
| The Starling | 0.2359 | 6.2 | 6.3 |
| AjeebDaastaans | 0.3774 | 6.9 | 6.7 |
| Sentinelle | 0.0838 | 5.4 | 4.7 |
| Dance Dreams: Hot Chocolate Nutcracker | 0.5858 | 7.9 | 7.1 |
Table 6.
Comparative analysis of predicted ratings of Vader and TextBlob with IMDb rating.
| S. No. | Movie Name | IMDb Rating | Vader Rating | TextBlob Rating |
|---|---|---|---|---|
| 1 | Caught by a Wave | 5.8 | 5.9 | 6.2 |
| 2 | The Starling | 6.4 | 6.2 | 6.2 |
| 3 | Squid Game | 8 | 7.1 | 6.3 |
| 4 | Dealer | 7.1 | 6.8 | 6.1 |
| 5 | Irul | 5.8 | 5.9 | 6.2 |
| 6 | The Midnight Sky | 5.6 | 5.4 | 5.1 |
| 7 | I Care a Lot | 6.3 | 5.8 | 5.4 |
| 8 | Ludo | 7.6 | 7.7 | 7.5 |
| 9 | Mank | 6.9 | 6.7 | 6.3 |
| 10 | The Devil All The Time | 7.1 | 6.6 | 6.6 |
Table 7.
Similar movies to the movie The Terminator.
| Sl. No | Original Title | Genres | Director | Similarity |
|---|---|---|---|---|
| 1 | Terminator2: Judgment Day | Action, Thriller, Science Fiction | James Cameron | 0.7319 |
| 2 | The Abyss | Adventure, Action, Thriller, Science Fiction | James Cameron | 0.5498 |
| 3 | Aliens | Horror, Action, Thriller, Science Fiction | James Cameron | 0.5498 |
| 4 | True Lies | Action, Thriller | James Cameron | 0.5375 |
| 5 | Terminator 3: Rise of the Machines | Action, Thriller, Science Fiction | Jonathan Mostow | 0.4534 |
| 6 | Terminator Genisys | Science Fiction, Action, Thriller, Adventure | Alan Taylor | 0.4139 |
| 7 | Avatar | Action, Adventure, Fantasy, Science Fiction | James Cameron | 0.3943 |
| 8 | Terminator Salvation | Action, Science Fiction, Thriller | Mcg | 0.3501 |
| 9 | The Running Man | Action, Science Fiction | Paul Michael Glaser | 0.3169 |
| 10 | Fortress | Action, Thriller, Science Fiction | Stuart Gordon | 0.3046 |
Table 8.
Similar movies to the movie American Beauty.
| Sl. No | Original Title | Genres | Director | Similarity |
|---|---|---|---|---|
| 1 | Revolutionary Road | Drama, Romance | Sam Mendes | 0.4512 |
| 2 | Jarhead | Drama, War | Sam Mendes | 0.4268 |
| 3 | Road to Perdition | Thriller, Crime, Drama | Sam Mendes | 0.3943 |
| 4 | Away We Go | Drama, Comedy, Romance | Sam Mendes | 0.3943 |
| 5 | Regarding Henry | Drama | Mike Nichols | 0.3333 |
| 6 | The Wackness | Drama | Jonathan Levine | 0.313 |
| 7 | Albatross | Drama | Niall MacCormick | 0.2945 |
| 8 | The Cement Garden | Drama | Andrew Birkin | 0.2937 |
| 9 | Faces | Drama | John Cassavetes | 0.2886 |
| 10 | Liberty Heights | Drama | Barry Levinson | 0.2886 |
Table 9.
Distribution of ratings by user .
| Rating | 5 | 4.5 | 4 | 3.5 | 3 | 2.5 | 2 | 1.5 | 1 | 0.5 |
| No. of movies | 4 | 6 | 11 | 3 | 7 | 0 | 7 | 3 | 2 | 1 |
Table 10.
Preferred movie set of a user.
| Sl. No | Original Title | Genres | IMDB Rating |
|---|---|---|---|
| 1 | The Lord of the Rings: The Return of the King | Adventure, Fantasy, Action | 9 |
| 2 | Taxi Driver | Crime, Drama | 8.3 |
| 3 | Lawrence of Arabia | Adventure, Drama, History, War | 8.3 |
| 4 | The Lord of the Rings: The Two Towers | Adventure, Fantasy, Action | 8.8 |
Table 11.
Similar movies to the movie The Lord of the Rings: The Return of the King.
| Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score | |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1639 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.1026 |
| 3 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.55 |
| 4 | Thunder Force | Action, Adventure, Comedy | 0.1666 | 5.2 | 2.3666 |
| 5 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2805 |
Table 12.
Similar movies to the movie Taxi Driver.
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | The Trial of the Chicago 7 | Drama | 0.1767 | 6.9 | 2.6870 |
| 2 | The White Tiger | Drama | 0.1767 | 6.7 | 2.6516 |
| 3 | All Together Now | Drama | 0.1767 | 6.5 | 2.6162 |
| 4 | Two Distant Strangers | Drama | 0.1767 | 6.1 | 2.5455 |
| 5 | Rogue City | Action, Crime, Drama | 0.1767 | 6.1 | 2.5455 |
Table 13.
Similar movies to the movie Lawrence of Arabia.
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Mosul | Action, Adventure, Drama | 0.1625 | 6.8 | 2.4537 |
| 2 | The Trial of the Chicago 7 | Drama | 0.125 | 6.9 | 1.9 |
| 3 | The White Tiger | Drama | 0.125 | 6.7 | 1.875 |
| 4 | All Together Now | Drama | 0.125 | 6.5 | 1.85 |
| 5 | Two Distant Strangers | Drama | 0.125 | 6.1 | 1.8 |
Table 14.
Similar movies to the movie The Lord of the Rings: The Two Towers.
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1230 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.0618 |
| 3 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.5166 |
| 4 | Thunder Force | Action, Adventure, Comedy | 0.1666 | 5.2 | 2.3333 |
| 5 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2516 |
Table 15.
Recommended movies for user .
| Sl. No | Original Title | Genres | Similarity | Predicted Rating VADER | Combined Score |
|---|---|---|---|---|---|
| 1 | Jaguar | Action, Adventure | 0.2041 | 6.5 | 3.1639 |
| 2 | Project Power | Action, Adventure | 0.2041 | 6.2 | 3.1026 |
| 3 | The Trial of the Chicago 7 | Drama | 0.1767 | 6.9 | 2.6870 |
| 4 | The White Tiger | Drama | 0.1767 | 6.7 | 2.6516 |
| 5 | All Together Now | Drama | 0.1767 | 6.5 | 2.6162 |
| 6 | Ganglands | Crime, Action, Adventure | 0.1666 | 6.3 | 2.55 |
| 7 | Two Distant Strangers | Drama | 0.1767 | 6.1 | 2.5455 |
| 8 | Rogue City | Action, Crime, Drama | 0.1767 | 6.1 | 2.5455 |
| 9 | Mosul | Action, Adventure, Drama | 0.1625 | 6.8 | 2.4537 |
| 10 | Dealer | Crime, Action, Adventure | 0.1443 | 6.8 | 2.2516 |
Table 16.
Recommended movies for the movie Wonder Woman according to our proposed hybrid recommendation system.
Table 16.
Recommended movies for the movie Wonder Woman according to our proposed hybrid recommendation system.
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Justice League: Crisis on Two Earths | Action, Adventure, Animation | 7.1 |
| Batman: Year One | Action, Adventure, Animation, Crime, Science Fiction | 7.1 |
| Batman: Mask of the Phantasm | Action, Adventure, Animation, Family | 7.4 |
| Justice League: The Flashpoint Paradox | Fantasy, Science Fiction, Animation, Action, Adventure | 7.3 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Captain America: Civil War | Adventure, Action, Science Fiction | 7.8 |
| Batman: Under the Red Hood | Action, Animation | 7.6 |
| Batman: The Dark Knight Returns, Part 1 | Action, Animation | 7.7 |
| Captain America: The Winter Soldier | Action, Adventure, Science Fiction | 7.6 |
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
Table 17.
Recommended movies for the movie Wonder Woman according to IMDb.
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Justice League | Action, Adventure, Animation | 7.1 |
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
| Suicide Squad | Action, Adventure, Crime, Fantasy, Science Fiction | 5.9 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Spiderman: Homecoming | Action, Adventure, Science Fiction | 7.4 |
| Deadpool | Action, Adventure, Comedy | 7.4 |
| Logan | Action, Drama, Science Fiction | 7.6 |
| Captain America: Civil War | Adventure, Action, Science Fiction | 7.8 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
Table 18.
Recommended movies for the movie Wonder Woman according to TMDb.
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
| Spiderman: Homecoming | Action, Adventure, Science Fiction | 7.4 |
| Logan | Action, Drama, Science Fiction | 7.6 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Justice League | Action, Adventure, Animation | 7.1 |
| Pirates of the Caribbean: Dead Men Tell No Tales | Action, Adventure, Fantasy | 6.6 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Baby Driver | Action, Crime | 7.2 |
| Kong: Skull Island | Action, Adventure, Fantasy | 6.2 |
| Life | Comedy, Crime | 6.4 |
Table 19.
Recommended movies for the animated movie Wonder Woman according to the hybrid recommendation system proposed in [55].
Table 19.
Recommended movies for the animated movie Wonder Woman according to the hybrid recommendation system proposed in [55].
| Movie Name | Genres | IMDb Rating |
|---|---|---|
| Batman v Superman: Dawn of Justice | Action, Adventure, Fantasy | 6.5 |
| Suicide Squad | Action, Adventure, Crime, Fantasy, Science Fiction | 5.9 |
| Thor: Ragnarok | Action, Adventure, Comedy | 7.9 |
| Justice League | Action, Adventure, Animation | 7.1 |
| Warcraft | Action, Adventure, Fantasy | 6.3 |
| Doctor Strange | Action, Animation, Family, Fantasy, Science Fiction | 6.6 |
| Guardians of the Galaxy Vol. 2 | Action, Adventure, Comedy, Science Fiction | 7.6 |
| Kong: Skull Island | Action, Adventure, Fantasy | 6.2 |
| The LEGO Batman Movie | Action, Animation, Comedy, Family, Fantasy | 7.2 |
| Batman and Harley Quinn | Animation, Action, Adventure | 5.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sahu, S.; Kumar, R.; MohdShafi, P.; Shafi, J.; Kim, S.; Ijaz, M.F. A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics 2022, 10, 1568. https://doi.org/10.3390/math10091568
AMA Style
Sahu S, Kumar R, MohdShafi P, Shafi J, Kim S, Ijaz MF. A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews. Mathematics. 2022; 10(9):1568. https://doi.org/10.3390/math10091568
Chicago/Turabian StyleSahu, Sandipan, Raghvendra Kumar, Pathan MohdShafi, Jana Shafi, SeongKi Kim, and Muhammad Fazal Ijaz. 2022. "A Hybrid Recommendation System of Upcoming Movies Using Sentiment Analysis of YouTube Trailer Reviews" Mathematics 10, no. 9: 1568. https://doi.org/10.3390/math10091568
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.