
Extended Generalized Sinh-Normal Distribution



1
Departamento de Matemática y Estadística, Facultad de Ciencias Básicas, Universidad de Córdoba, Montería 230001, Colombia
2
Departamento de Matemática, Facultad de Ingeniería, Universidad de Atacama, Copiapó 1530000, Chile
3
Grupo de Investigación Davinci, Facultad de Ciencias Exactas y Aplicadas, Instituto Tecnológico Metropolitano, Medellín 050034, Colombia
*
Author to whom correspondence should be addressed.
†
Present address: Programa de Pós-Graduação em Modelagem e Métodos Quantitativos, Universidade Federal do Ceará, Fortaleza 60020-181, Brazil.
Mathematics 2021, 9(21), 2793; https://doi.org/10.3390/math9212793
Submission received: 21 September 2021
/
Revised: 20 October 2021
/
Accepted: 25 October 2021
/
Published: 4 November 2021
(This article belongs to the Section Probability and Statistics)
Abstract
:Positively skewed data sets are common in different areas, and data sets such as material fatigue, reaction time, neuronal reaction time, agricultural engineering, and spatial data, among others, need to be fitted according to their features and maintain a good quality of fit. Skewness and bimodality are two of the features that data sets like this could present simultaneously. So, flexible statistical models should be proposed in this sense. In this paper, a general extended class of the sinh-normal distribution is presented. Additionally, the asymmetric distribution family is extended, and as a natural extension of this model, the extended Birnbaum–Saunders distribution is studied as well. The proposed model presents a better goodness of fit compared to the other studied models.
1. Introduction
When materials are exposed to pressure or stress levels, material structural damage could occur. This is known as material fatigue, and a statistical model to fit random variables to model the failure time of fatigue for material was proposed by Birnbaum and Saunders (1969) [1], known in the literature as Birnbaum–Saunders distribution and generally denoted by , where represents a shape parameter and is a scale parameter and the median of the distribution. Later, Desmond (1985) [2] showed that the BS distribution describes the time failure that occurs when some kind of damage is accumulated after a given time.
A distribution associated with that of Birnbaum and Saunders (BS) is the sinh-normal (SHN) distribution. This distribution, introduced by Rieck and Nederman (1991) [3], is based on a nonlinear transformation of a normal distribution. Therefore, let where and are location and scale parameters, respectively, and is a shape parameter. Then, random variable (r.v.) Y follows a sinh-normal distribution denoted by . A probability density function (pdf) of a random variable with a SHN distribution is given by
where , is a derivative of with respect to y, and is the pdf of the normal distribution. It can be shown that the s-th moment of a random variable with a SHN distribution is given by
where
From this result, we obtain that and . It can also be shown, from the two central moments, that is a symmetric distribution with respect to . In general, we find that
Asymmetric extensions of the SHN model have been considered, for instance, by Leiva et al. (2010) ([4]) and Lemonte et al. (2011) ([5]), who studied the skewed SHN model, as well as by Martínez-Flórez et al. (2017) [6], who investigated the power SHN model, and Moreno-Arenas et al. (2016) [7], who presented the Proportional Hazard BS model (PHBS).
The SHN distribution is also known as the log-Birnbaum–Saunders (LBS) distribution because , then follows a BS distribution, with parameters and
The pdf of a random variable is given by
where
An important feature of this distribution is its robustness concerning the estimation of its parameters—an aspect that was analyzed by Barros, Paula, and Leiva (2010) [8]. Moreover, extensions of this distribution to an elliptical family and to a skew elliptical family (this latter is known as the double generalized BS distribution) have been studied by Díaz-García et al. (2005) [9] and by Vilca-Labra and Leiva-Sánchez (2006) [10], respectively. Martínez-Flórez et al. [11] present an extension to a power-skew-elliptical family. Other types of extensions have also been considered by authors such as Castillo et al. (2011) [12], Cordeiro and Lemonte. (2014) [13], and Reyes et al. (2018) [14].
All these extensions are particularly characterized by fitting skew unimodal data while not being appropriate to fit bimodal data. However, Martinez-Florez et al. (2017) [6] and Olmos et al. (2017) [15] recently presented BS models to fit positive bimodal data. Likewise, Bolfarine et al. (2011) [16] introduced another model to fit positive bimodal data generated by the log-skew-normal distribution.
Cortés et al. (2018) [17] presented a class of extended distribution, generated by the pdf, , of the bimodal-normal distribution. They specifically defined a general class of distributions with a pdf given by
where is a pdf, is a shape parameter, and h is a continuous positive function such that This distribution is called the “general class of distributions”. Further, the authors study the normal, t-student, Laplace, and BS distributions as special cases. As special cases of this family, from Elal-Olivero et al. (2010) [18] and the bimodal log-skew-normal of Bolfarine et al. (2011) [16], the class of bimodal skew-elliptical distributions can be found in the literature.
In this study, we analyze and study a general extended class of the SHN distributions, which has an extra parameter to the SHN model and introduces flexibility to the SHN distribution. Additionally, an extension of the BS model is presented. We highlight that this kind of model could be applied to data sets related to material fatigue [2], reaction and neuronal reaction time [19], agricultural engineering [20], and spatial data (see [21,22], among others). Note that this distribution can fit bimodal data sets, which could be present in problems where the population is divided by groups such as gender or different levels of HIV-RNA.
This paper unfolds as follows: Section 2 presents the extended sinh-normal distribution (ESHN) model. Section 3 provides the statistical approximation of the moments of an ESHN random variable. Section 4 outlines the properties of the extended generalized sinh-normal (EGSHN) distribution. Section 5 shows the features of the extended sinh-normal regression model. Section 6 presents the results of a simulation study to analyze the properties of the EGSHN model. Section 7 develops two numerical illustrations to evaluate the relevance of the EGSHN. Section 8 discusses the statistical and practical implications of the proposed distribution.
2. Extended Sinh-Normal Distribution
We now propose an extension of the SHN case introduced by Rieck and Nederman (1991) [3] to a general class of distributions. Then, taking and in equation (7), where and are defined as in (1), the extended class of SHN distribution is defined through the pdf given by
with and defined as the SHN distribution of Rieck and Nederman (1991) [3], and as a shape parameter. This distribution is denoted by , which, for some values of the parameter, could be bimodal. In this context, could be considered as a bimodality parameter. It can be easily deduced that for , the SHN distribution is obtained, and if , then which is a new family of distributions. It can be also shown that a random variable
where is the extended normal distribution, as studied by Cortés et al. (2018) [17].
Denoting then, we find that ; thus, when , then and where (see Rieck et al. [3]). Next, it is possible to conclude that when then
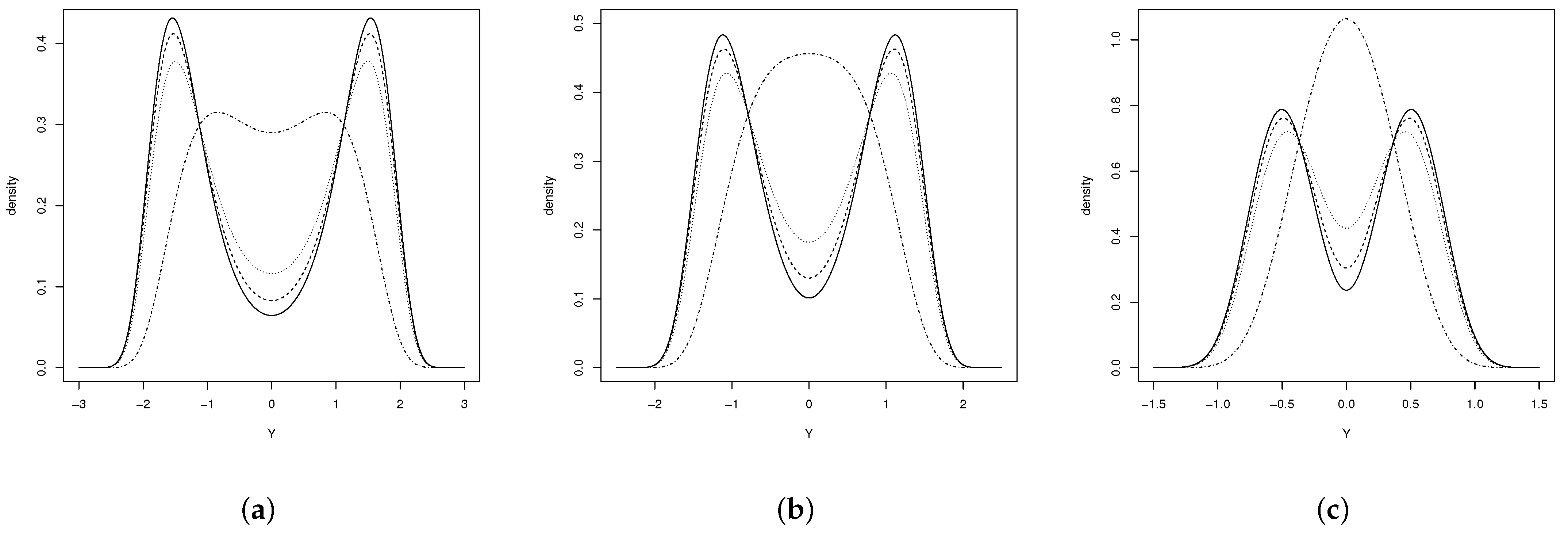
Figure 1 shows the pdf for an extended sinh-normal (ESHN) distribution with two parameters, respectively, where it can be seen that the distribution, for , is symmetric and unimodal in cases (b) and (c), and for the other cases, it is strongly bimodal.
Denoting and then, the pdf of could be written as a mixture of two distributions:
From (9) and remembering that a cumulative distribution function (cdf) of is given by , then it can be shown that the cdf of the distribution is given by
Thus, the survival, risk (or hazard), and inverse risk functions of this distribution are, respectively, given by
and
where is defined as , with , and being the survival, hazard and inverse risk functions of the model
Another important result of this distribution is presented as follows:
Let ; then, the random variable follows an distribution, and where and is related to the extended BS distribution, whose properties and moments are studied in Cortés et al. (2018) [17]. So, if , then (i) with and (ii)
3. Moments of an Extended Sinh-Normal Random Variable
For a random variable , the r-th moment is given by:
where
From (9), it can be shown that the k-th moment of the distribution is
where the second step is obtained using the transformation. Then, denoting
we find that
The location case of the model can be obtained using the binomial theorem and the previous result in the expression
From this result, and given that , it is obtained that and It can also be shown, from the central moments, that which is a symmetric distribution with respect to and
4. Extended Generalized Sinh-Normal Distribution
The ESHN distribution studied in the previous section has the main feature of bimodal symmetric data fitting, for which it is necessary to extend this model to asymmetric data; this asymmetric extension comes from the results found by Azzalini and Capitanio (2003) [23] and Azzalini (2005) [24], who showed that if g is a pdf symmetric around zero, and H is a cdf so that its density h is symmetric around zero as well, then for any odd function , we find that for is a pdf in
Then, since the pdf () of the standard distribution, , is continuous and symmetric around zero; is an absolutely continuous distribution function that is symmetric around zero and whose density, , is also symmetric around zero; and for constant values , is an odd function, then is a pdf for any Thus, the location-scale-extended generalized sinh-normal (EGSN) distribution is defined through the pdf given by
where is a skewness parameter. So, in this work, this model is denoted by .
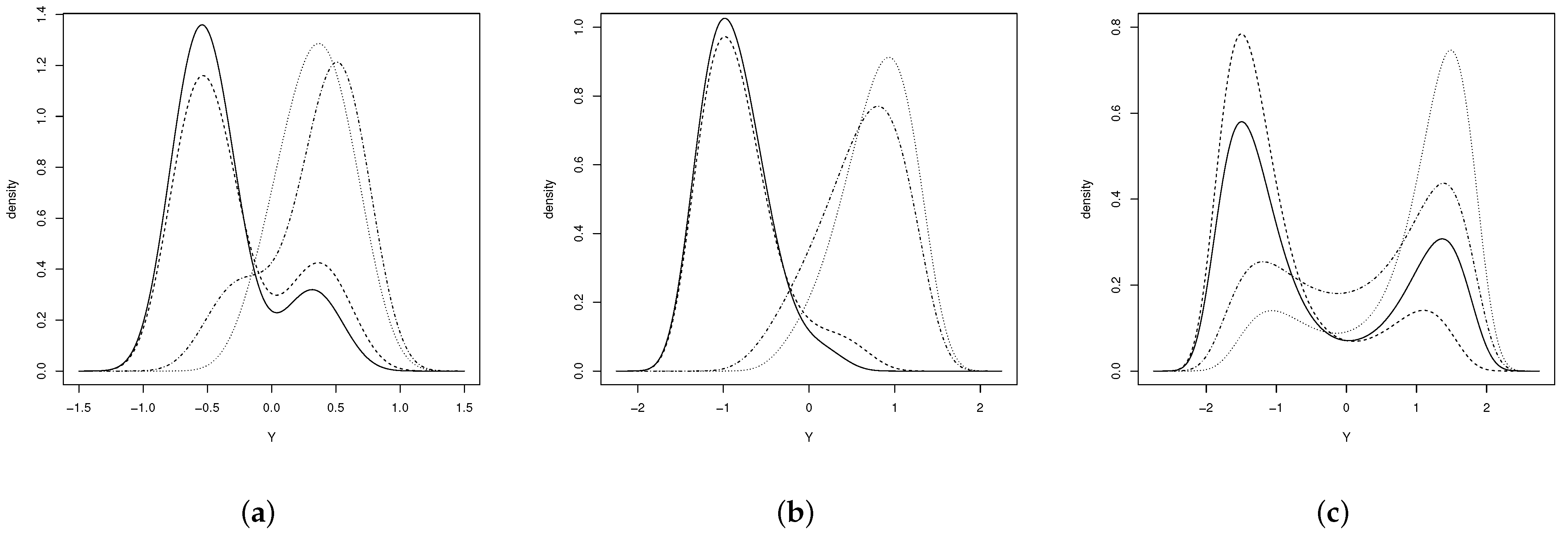
Figure 2 shows the pdf of the EGSHN distribution for different values of the parameters. As observed, the distribution could be unimodal or bimodal depending on such values.
Likewise, for , we obtain the asymmetric SHN distribution based on the model considered by Leiva et al. (2010) [4]. In addition, if , analogously to the ESHN case, we have the new family of distributions Now, for , an SHN model is followed. It can also be shown that a random variable
where is the extended skew-normal distribution, which was introduced by Elal-Olivero et al. (2009) [25]. As in the ESHN model, it can be shown that when then
For p, as in the case of the ESHN model, the pdf of the distribution could be written as
From (18), it follows that the cdf of is given by
where and denote the cdf and pdf of the skew-normal distribution, respectively, with a location parameter of 0 and a scale parameter of 1.
Then, the survival, risk (or hazard), and inverse risk functions of this distribution are, respectively, given by
where and are the survival, hazard, and inverse risk functions of the skew-SHN function, respectively.
4.1. Stochastic Representation
The stochastic representation of the EGSHN model is based on Elal-Olivero (2010) [18] and Elal-Olivero, et al. (2009) [25]. This is presented below.
Definition 1.
If the random variable X has a pdf given by
then we say that X follows a bimodal-normal distribution, and it is denoted as (see [18]).
Remark 1.
Let W and U independent random variables with , a chi-square distribution with three degrees of freedom, and U a pdf, such that . If then .
Remark 2.
Let and considers the random variable which is defined as
then,
Then,
which is denoted as .
Proposition 1.
Let and , and say that is a uniform random variable, independent of and If
with then .
Proof.
so
□
Definition 2.
If the random variable W has a pdf
with then W follows a and this is denoted as .
Proposition 2.
Let Z and X be independent random variables with and .
If
then .
Proof.
Note that is an odd function and the density of both the random variables and the distribution function of Z are symmetric around zero; thus, applying Lemma 1 as in [24], the result follows. □
Location-Scale Extension
Let and let then
Then, the pdf of V is given by
which is denoted by
4.2. Moments of an Extended Generalized Sinh-Normal Random Variable
For a random variable , the r-th moment is given by
where
4.3. Extended Generalized Birnbaum–Saunders Distribution
Let Then, the distribution of a random variable follows an extended generalized BS distribution, which is denoted by , where The proof of this result is obtained from the transformation theorem of random variables. The pdf of an random variable is given by
where and are defined as in (6).
Note that, for , we have the doubly generalized BS distribution developed by Vilca et al. (2006) [10] for the special case of the skew-normal distribution introduced by Azzalini (1985) [26], BSSN. If , then if , then follows the extended BS distribution class studied by Cortés et al. (2018) [17], and for , follows a BS model. Likewise, it can be shown that a random variable
As in the EGSHN model, it can be shown that the cdf of the distribution is given by
Then, the survival, risk, or hazard, and inverse risk functions of this distribution are given, respectively, by
and
where e are the survival, hazard, and inverse risk functions of the BS skew-normal model, For the BSSN model, ; then, for the EGBS model, it follows that
Some properties of the BS model remain true for the EGBS model. Thus, if , then (i) , with , and (ii) .
The moments of an EGBS random variable with parameters and can be obtained by means of the following expression:
where is the expectation operator of the Birnbaum–Saunders skew-normal distribution (BSSN). To calculate the mean, variance, and the skewness and kurtosis coefficients of the EGBS model, the expressions of the corollaries 2.1 and 2.2 of Vilca et al. [10] could be used.
For , the log-likelihood function corresponding to the random sample is
The score function is composed of the following elements:
where , with Iterative numerical methods must be used to solve this system of nonlinear equations.
5. Extended Sinh-Normal Regression Model
One of our main goals is to develop a log-BS regression model based on the model. This regression model will be an optimal alternative to the log-BS model introduced by Rieck et al. (1991) [3] in order to fit bimodal or survival asymmetric data. Now, the extended generalized log-linear BS regression model is defined following the considerations given by Rieck et al. (1991) [3] and considering that is a dependent variable; that a set (p) of explanatory variables, denoted by , is given; and that is a p-dimensional vector of unknown parameters, where a linear predictor, , is obtained for .
Then, let us suppose that are independent and identically distributed random variables (i.i.d. r.v.) such that . Now, let us suppose that the distribution of is independent of the set of explanatory variables, , where
- for with being a p-dimensional vector of unknown parameters.
- The shape, bimodality, and skew parameters do not consider i.e.,
Let us suppose that Then, the extended generalized log-linear BS regression model is defined as
where , for and is the log-survival for the i-th individual. This model is denoted by When it follows the log-BS regression model, , of Rieck et al. [3]; i.e., the MRESHN model is more flexible than the log-BS model in terms of skewness and kurtosis.
When it follows that , for ; then, important results are obtained. Thus, we find that and ; additionally, as the errors are independent random variables, then for , it follows that Furthermore, considering that the explanatory variables are independent of the shape parameter, from the above results, it is therefore possible to conclude that for furthermore, like , it can be shown that so the linear estimators for can be derived from the ordinary least squares method, whose solution is given by
with covariance matrix
So, a biased estimator for could be
Now, the model provided in (26) is a linear regression model similar to the models of the theory of linear models, with the characteristic that the random component follows a distribution; that is, assume that these parameters are located around zero and have a scale parameter equal to 2. Then, the interpretation of their parameters, with relation to the observed variable Y, is given in the same manner as the linear regression model.
For the vector , we find that the log-likelihood function corresponding to the random sample is
where and with , for The elements of the score function are given by
where
The maximum likelihood estimator of , ; ; and is the solution to equations , for ; ; and , respectively, which require iterative numerical methods.
The least squares estimator () may be used to initialize the iterative numerical process for , and with these initial values, we can calculate
The elements of the observed information matrix, defined as minus the second derivative of the log-likelihood function, are denoted by and , and are, respectively, given by
The information matrix () could be estimated as the expected value of the elements of the observed information matrix, which must be calculated using numerical approximation methods. For the sub-matrix of vector of the information matrix has the following elements:
where and with the error function (see Prudnikov et al. [27]).
For , the determinant of the information sub-matrix is not equal to zero; that is, . Thus, it is possible to conclude that the information matrix of the ESHN model is nonsingular. Likewise, for , we find that
where denotes the expected value function, and is the gamma distribution with parameters a and b, respectively. The rows or columns of the information matrix of the parameters vector of the regression model in the case of are linearly independent, Therefore, the information matrix of this model is nonsingular, and its inverse is the variance–covariance matrix, of the estimator vector of maximum likelihood of the parameters vector; then, the estimated standard errors of the estimators are the square root of the matrix
Then, when , the approximation might be used to obtain a confidence interval for the parameter for , which is given by where corresponds to the r-th element of the diagonal of the sub-matrix and is quartile of the standard normal distribution.
6. Simulation Study
A simulation study is presented to analyze the performance of the maximum likelihood estimation of the parameters of the regression model. In general, simulations with , and 500 were generated for different scenarios. So, the following model, with and , is studied.
Note that, for takes values of a uniform random variable , and The statistics of the empirical standard deviation (sd), relative bias (RB) and for the EGSHN model are calculated.
The results for each studied scenario are described as follows.
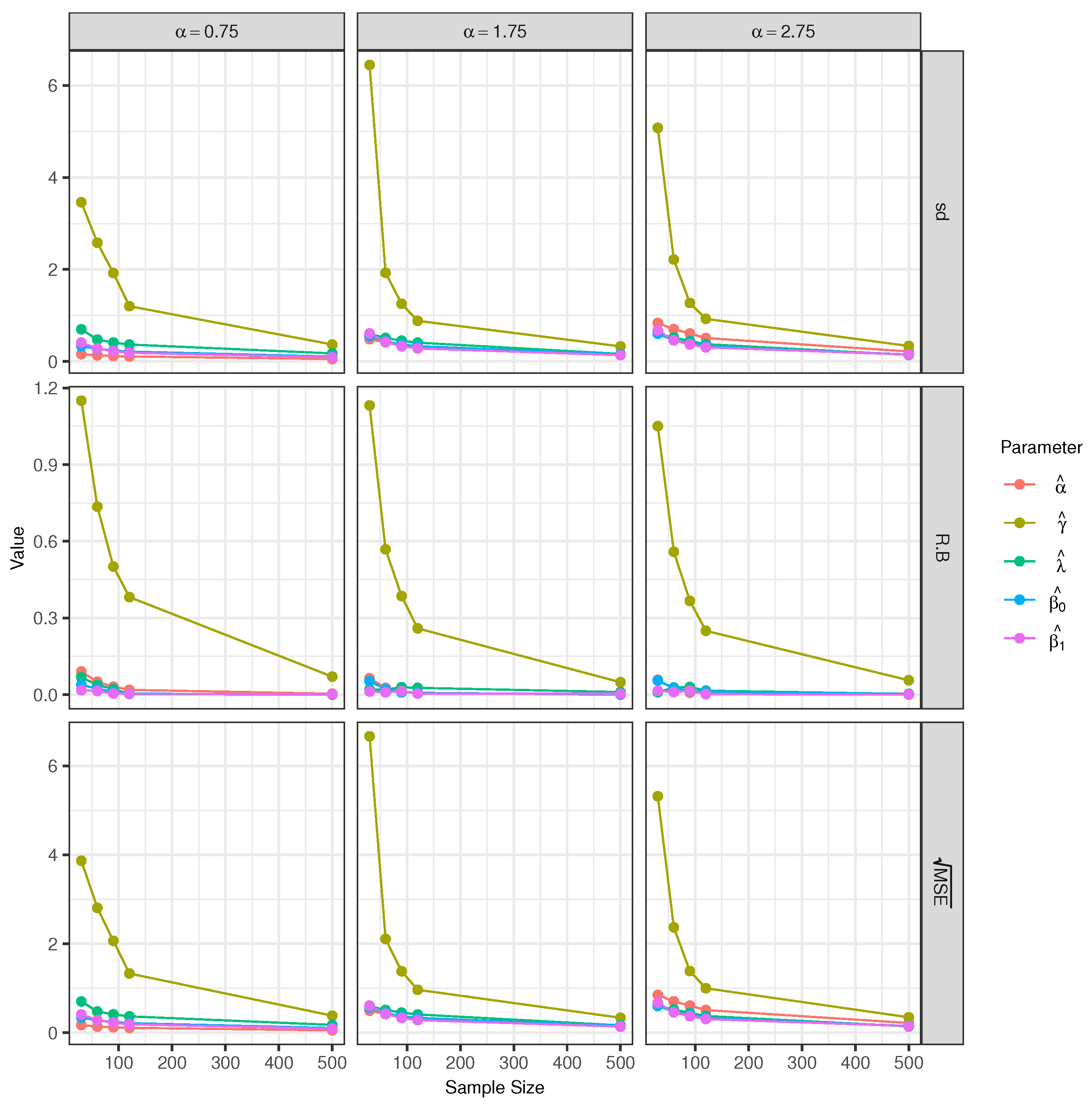
Scenario 1 (Varying α): In this scenario, the used alpha values are , , and , keeping and fixed. For each studied case of the model (see Figure 3 and Table 1), it can be seen that for the parameters and , the relative biases are small, especially for the parameter . Note that the statistics RB, sd, and decrease when the sample size is increased.
Additionally, it can also be observed that the relative bias of the parameter is not very important (not very large). Something similar is observed for the parameter . On the other hand, the relative bias and the root of the mean square error of the parameter are not very small, especially when the sample size is small (30 or 60).
The statistics RB, sd, and for the parameters decrease when the sample size increases. These results guarantee a lack of bias and the asymptotic consistency of the estimates of the parameters .
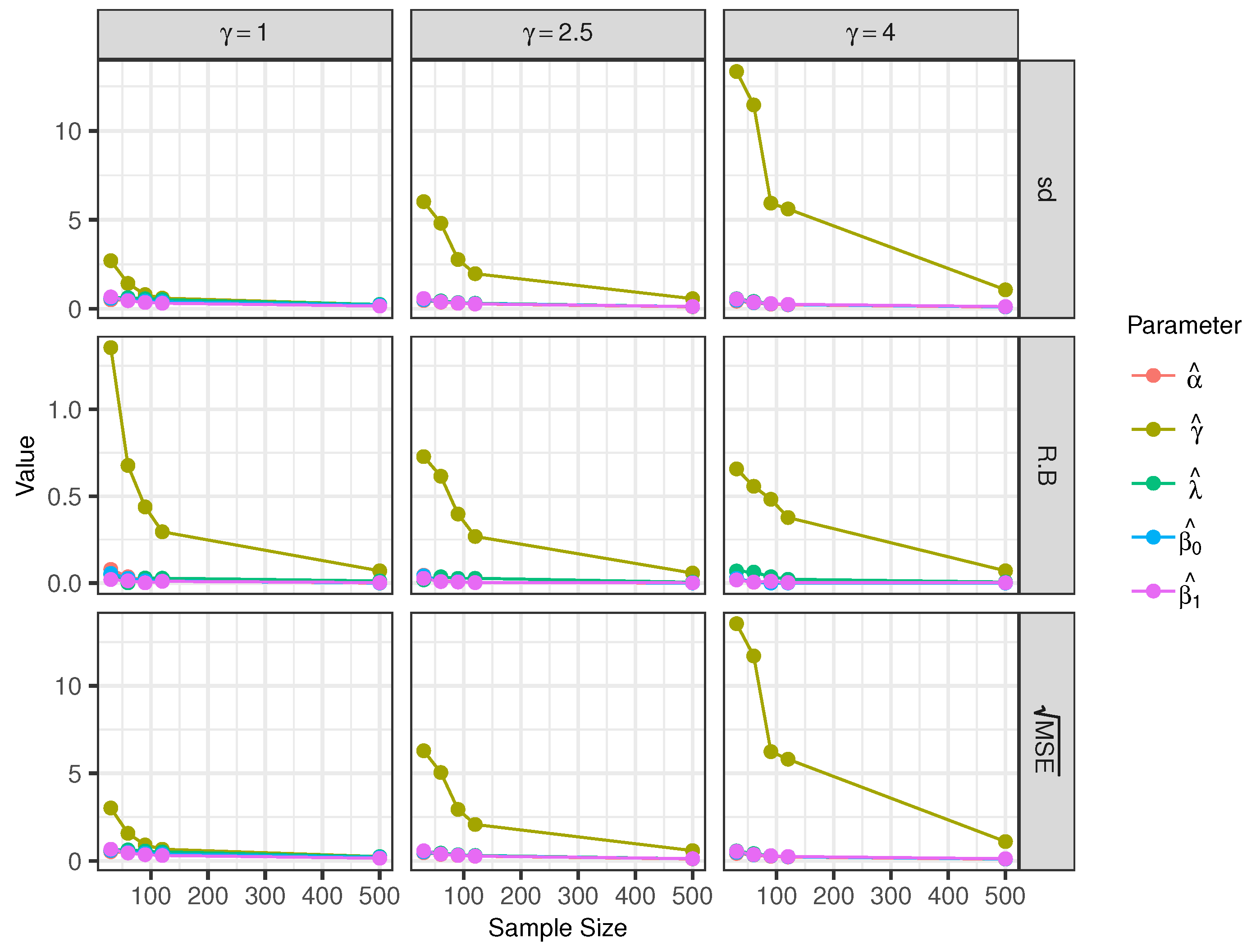
Scenario 2 (Varying γ): Here, the used gamma values are 1, 2.5, and 4, keeping and fixed. Similar to scenario 1, we can see that the parameters and present small relative biases (see Figure 4 and Table 2). The statistics RB, sd, and of the model decrease when the sample size is increased.
The parameters and show very small relative biases, but the parameter presents large relative biases and . This behavior of the gamma parameter is more striking for small sample sizes.
The asymptotic consistency of the estimates of the parameters can be guaranteed because the calculated statistics for decrease when sample size increases.
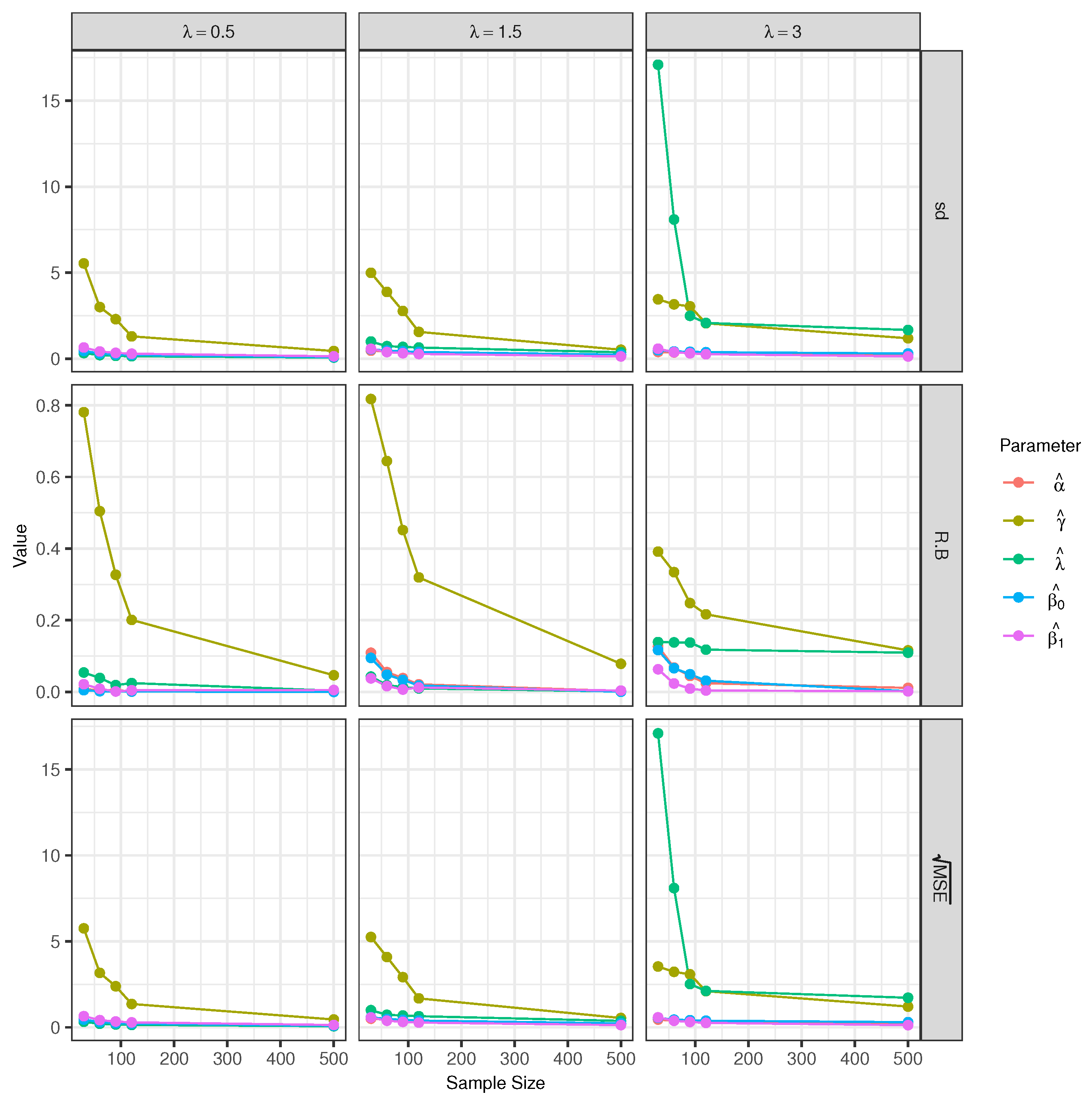
Scenario 3 (Varying λ): In scenario 3, where the model is considered, the used lambda values are , , and 3, keeping and fixed (see Figure 5 and Table 3). As in the previous simulation scenarios, the relative biases for the parameters and are small, especially for the parameter . It is possible to see that the statistics RB, sd, and tend to decrease when the sample size increase.
The RB and of the parameter are large for small sample sizes. The parameter presents small relative biases, but the parameter shows a large sd and when . In general, we can see that the asymptotic consistency of the estimates of the parameters is satisfied.
7. Numerical Illustrations
7.1. Illustration 1
In this paper, we employed the dataset studied by Hirose (1993) [28] to show the relevance of the EGSHN model. This dataset contains the results of an accelerated life test on polyethylene terephthalate (PET) (used in electrical isolation) in SF6 gas-insulated transformers. Such an accelerated life test was performed at four voltage levels (5, 7, 10, and 15), with 7, 15, 10, and 9 observations per level, respectively. The main purpose of the study was to analyze the resistance times (t) of the insulating films at different voltages (v). Hence, we here consider the following regression model:
where follows an distribution.
In this work, the SHN and ESHN models are fitted (see Ortega et al. [29]). To compare these models, the Akaike (AIC) information criterion (Akaike, [30]) and the corrected Akaike (AICC) criterion (Cavanaugh, [31]) are implemented. These measures are defined as follows:
where p is the number of parameters and is the log-likelihood function evaluated for the MLEs of parameters. The best model is that with the smallest AIC or AICC value. To fit the bivariate model, we used the optim function of the statistical package R Core Team.
The estimated parameters of these models, accompanied by their standard errors in parentheses, are obtained using the maximum likelihood method. Table 4, shows the results. Note that according to the AIC and AICC, the EGSHN and ESHN models present the best fits.
In order to identify atypical observations and/or the misspecifications of models, we analyzed the transformation of the martingale residual, rMTi, proposed by Barros et al. [8]. These residuals are defined by
where is the martingale residual proposed by Ortega et al. [32], where indicates whether the i-th observation is censored or not, respectively; denotes the sign of ; and represents the survival function evaluated in , where are the MLE for .
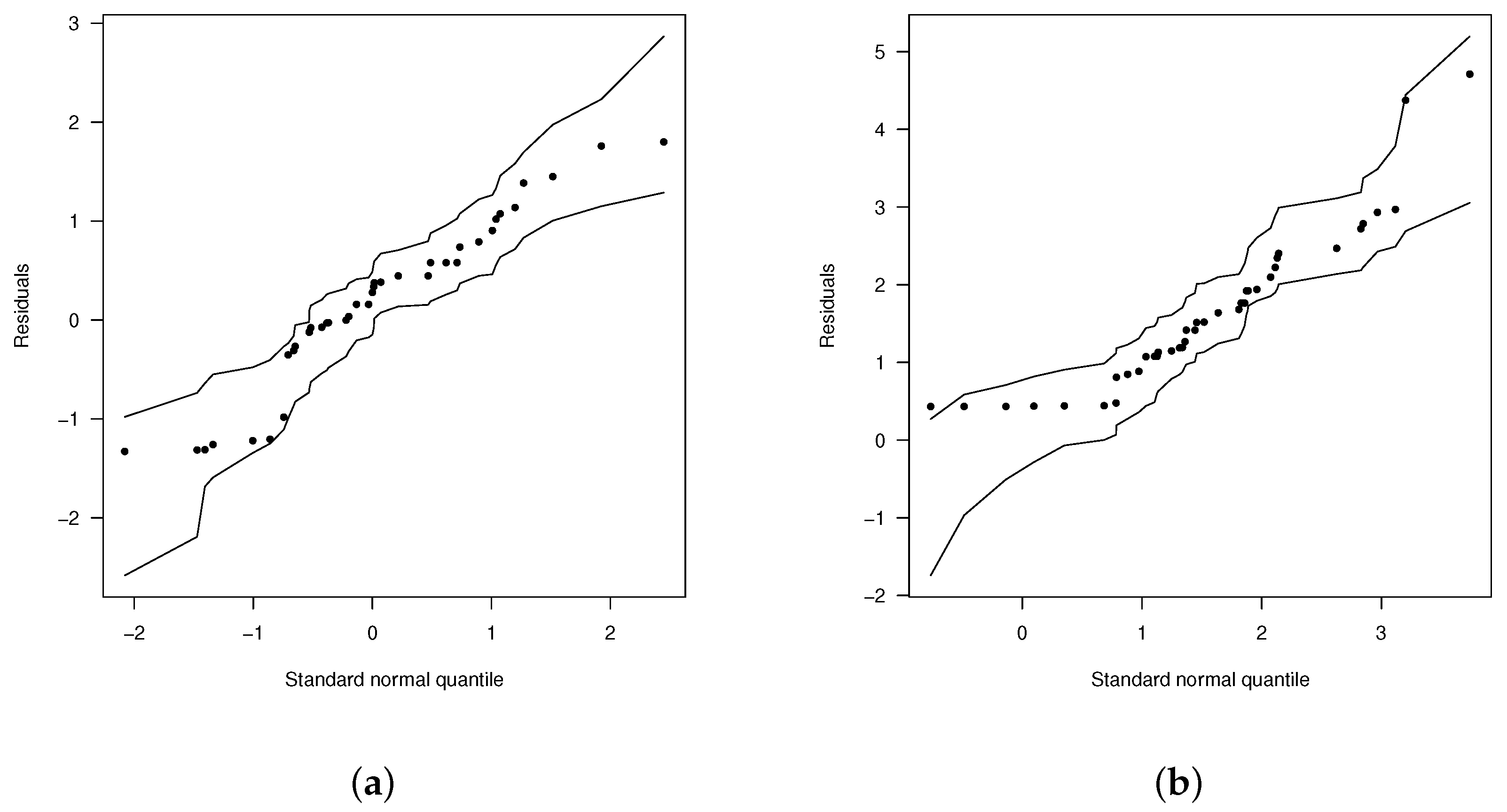
The plots of with generated confidence envelopes is presented in Figure 6. From this figure, we can see clearly that the EGSHN model fits better to the data than the SHN and ESHN models, since, in these cases, there are no observations that lie outside the envelopes.
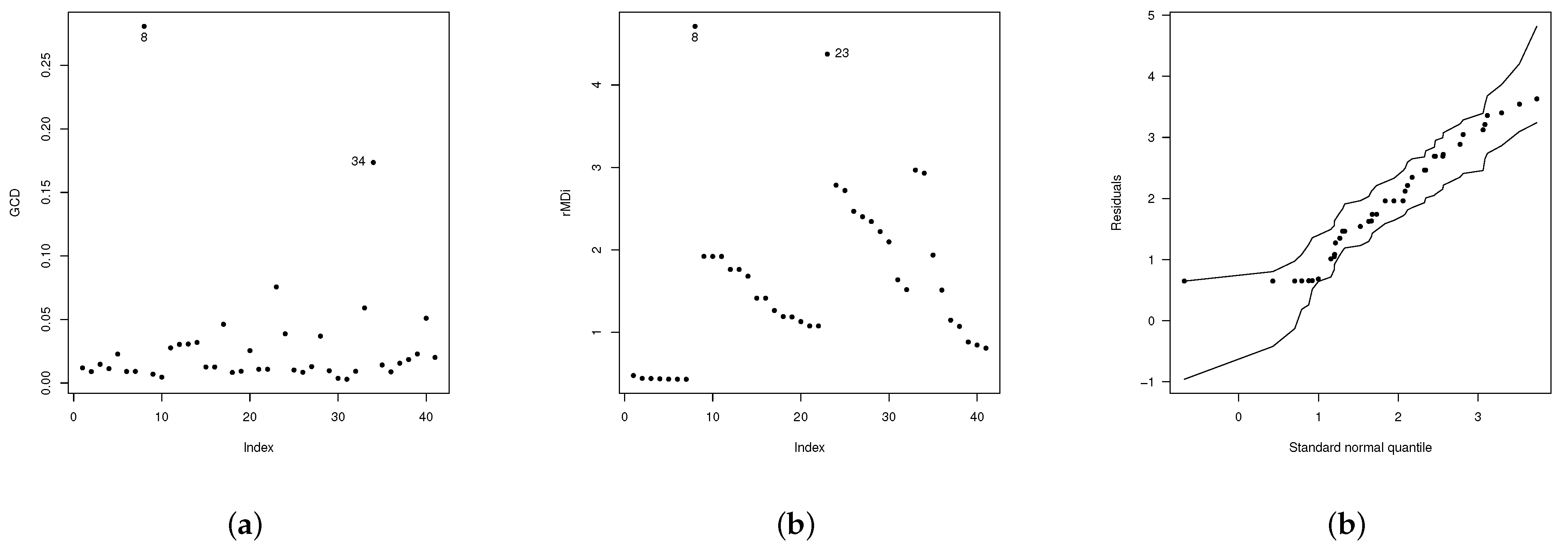
In Figure 6b, we observe two points: one in the border and the other outside it. There is also a point far from the set of observations. Since these points could be values influencing the estimates of the parameters, we calculated the generalized Cook’s distance (GCD) and showed the residual components of the deviation plot. Figure 7 illustrates the behavior of these two statistics. As can be seen in this figure, observations 8, 23, and 34 could be possible influential values. Thus, to calculate their impact on the estimates, we computed the estimates by eliminating each of these observations or groups of them.
The relative change (RC), in percentage, of each parameter estimate is used to evaluate the effect of the potentially influential case. The RC is given by , where denotes the MLE of after removing the i-th observation. Table 5 lists the obtained RC values. According to this table, the relative changes of the MLE of parameter are excessively pronounced in all the models, mainly for observation 8 and the set. Thus, after deleting observations 8 and 23, the new estimates of the parameter are and with and as illustrated in Figure 7c.
7.2. Illustration 2
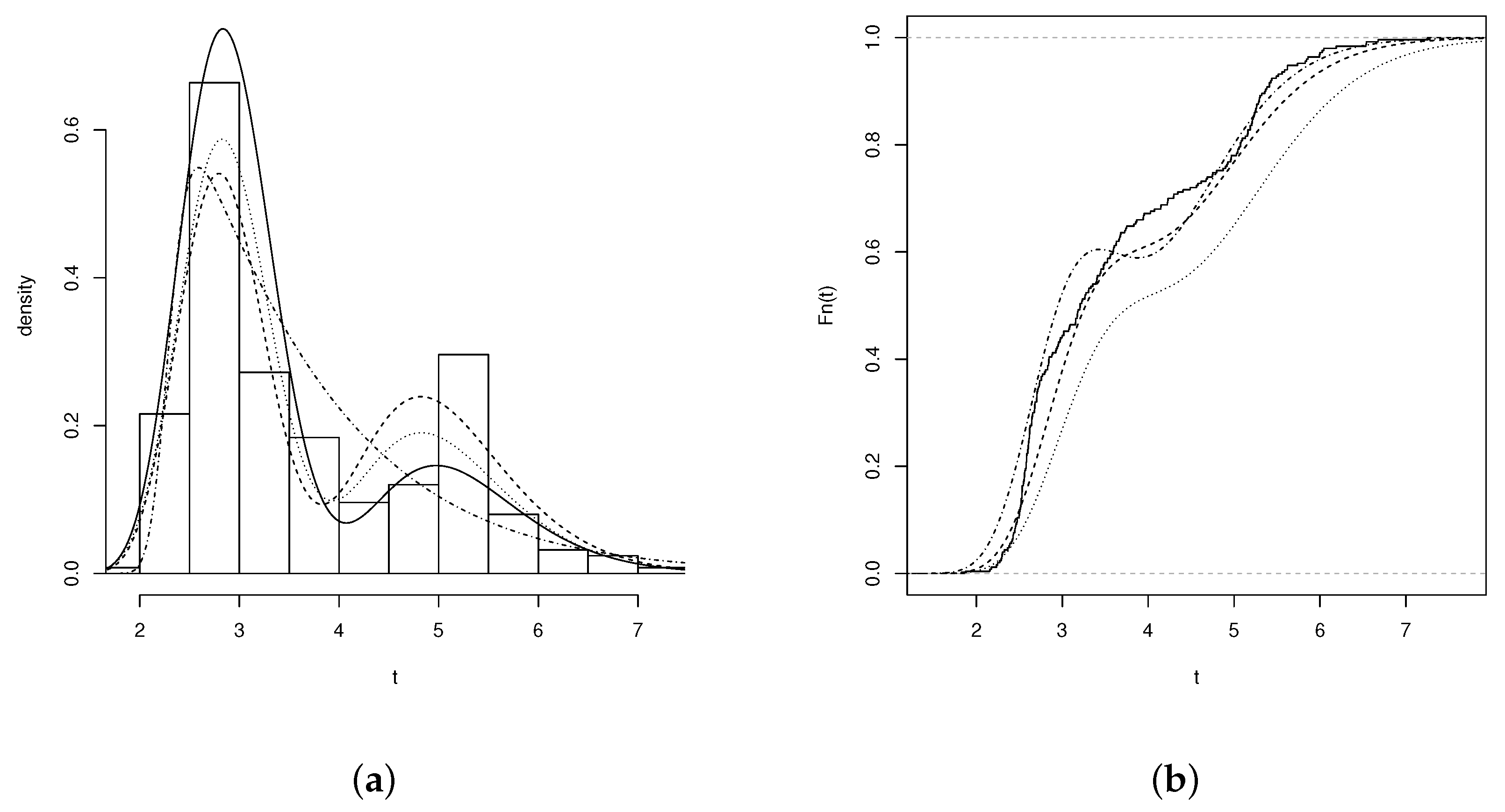
We used the dataset reported by the Center for Applied Statistics of the Institute of Mathematics and Statistics at the University of São Paulo to illustrate the relevance of the EGBSSN model. This dataset contains data on the amount of DNA within the nucleus (ploidy) of mammary cells (250 samples) from women with breast cancer. The ploidy variable exhibits a bimodal asymmetric performance, with D = 0.0399 and p-value = 0.0059 after performing the Hartigan and Hartigan (1985) [33] bimodality test. In addition, according to its descriptive statistics (presented in Table 6), this variable has a considerable positive skewness and high kurtosis. Additionally, Figure 8a shows a bimodal distribution of the data, which is why the EGBSSN model becomes an alternative to fit this kind of data.
In this study, the Birnbaum–Saunders (BS) and Birnbaum–Saunders skew-normal models were fitted. We also considered the following bimodal models: the log-skew-normal model developed by Bolfarine et al. (2011) [16], the extended class (EBN) introduced by Cortez et al. (2018) [17], and the EGBS model.
Table 7 presents the maximum likelihood estimates and AIC and AICC values of five models. As observed in this table, the BS and BSSN models provide a poor fit to the DNA dataset. Conversely, the EGBS model shows the best fit among the fitted models, which is explained by its flexibility to fit asymmetric bimodal data.
Figure 8a,b shows the estimated densities of the models with the best fit (BSSN, BLSN, EBS, and EGBS); the empirical cumulative distribution functions of the BLSN, EBS, and EGBS models; and the parameter estimates. Note that the EGBS model provides the best fit when compared to the BSSN, BLSN, EBN, and BS models.
8. Discussion
Bimodality and skewness are two common features that may be present in data from engineering, geo-spatial, medicine, and other areas. The natural complexity of data from these areas needs to be fitted using models that offer great flexibility and goodness of fit. In some cases, the data only present positive skewness, or in other cases, the distribution is only bimodal, but these two features could be present simultaneously. Thus, in this paper, a distribution capable of fitting bimodal and positively skewed data sets was proposed. In addition, the extended Birnbaum–Saunders distribution was studied as well.
Although there are proposals in the literature such as those cited in the previous sections, which allow the fitting of asymmetric or bimodal data, our model has the characteristic of modeling data that simultaneously have these two characteristics and has great flexibility and goodness of fit for data with these conditions. It is a new, promising, and user-friendly option to consider in statistical analysis.
To conclude, the EGBS model was proposed as a new statistical distribution suitable to fit real data sets with positive skewness and bimodality that presents a great performance compared with models available in the literature and that aim to achieve the same objective.
Author Contributions
The contributions of the authors in this paper are described as follows: Conceptualization, G.M.-F., D.E.-O. and C.B.-C.; methodology, G.M.-F. and D.E.-O.; formal analysis, G.M.-F. and C.B.-C.; investigation, G.M.-F., D.E.-O. and C.B.-C.; resources and data curation, G.M.-F. and C.B.-C.; writing, original draft preparation, C.B.-C.; writing, review and editing, C.B.-C.; visualization, C.B.-C.; supervision, G.M.-F. and C.B.-C.; project administration, G.M.-F. and C.B.-C.; funding acquisition, C.B.-C. and D.E.-O. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Instituto Tecnológico Metropolitano (ITM) through the project (P20244) Priorización de zonas para la restauración ecológica y de uso público mediante la armonización de técnicas de mapeo participativo y modelación espacial multicriterio en el municipio de Belmira, Antioquia, Colombia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
C.B.-C. extends their sincere gratitude to the Instituto Tecnológico Metropolitano (ITM) and South Pole for their support. D.E.-O. thanks to the DIUDA REGULAR project No. 22409 of the Universidad de Atacama, Chile, and the project Distribuições de Probabilidade Mutivariadas Assimétricas e Flexíveis, Universidade Federal do Ceará, Fortaleza, Brazil. G.M.-F. thanks Universidad de Córdoba and Universidade Federal do Ceará, Brazil.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Birnbaum, Z.W.; Saunders, S.C. A New Family of Life Distributions. J. Appl. Probab. 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Desmond, A. Stochastic models of Failure in random environments. Can. J. Stat. 1985, 13, 171–183. [Google Scholar] [CrossRef]
- Rieck, J.R.; Nedelman, J.R. A log-linear model for the Birnbaum-Saunders distribution. Technometrics 1991, 33, 51–60. [Google Scholar]
- Leiva, V.; Vilca-Labra, F.; Balakrishnan, N.; Sanhueza, A. A skewed sinh-normal distribution and its properties and application to air pollution. Commun. Stat. Theory Methods 2010, 39, 426–443. [Google Scholar] [CrossRef]
- Lemonte, A.J. A log-Birnbaum-Saunders regression model with asymmetric errors. J. Stat. Comput. Simul. 2011, 82, 1775–1787. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. The Log-Linear Birnbaum-Saunders Power Model. Methodol. Comput. Appl. Probab. 2017, 19, 913–933. [Google Scholar] [CrossRef]
- Moreno-Arenas, G.; Martínez-Flórez, G.; Barrera-Causil, C. Proportional Hazard Birnbaum-Saunders Distribution with Application to the Survival Data Analysis. Rev. Colomb. Estad. 2016, 39, 129–147. [Google Scholar] [CrossRef]
- Barros, M.; Galea, M.; Gonzalez, M.; Leiva, V. Influence diagnostics in the tobit censored response model. Stat. Methods Appl. 2010, 19, 379–397. [Google Scholar] [CrossRef]
- Díaz-García, J.A.; Leiva-Sánchez, V. A new family of life distributions based on the elliptically contoured distributions. J. Stat. Plan. Inference 2005, 128, 445–457. [Google Scholar] [CrossRef]
- Vilca-Labra, F.; Leiva-Sanchez, V. A new fatigue life model based on the family of skew-elliptical distributions. Commun. Stat. Theory Methods 2006, 35, 229–244. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, Y.M.; Gómez, H.W. A Unification of Families of Birnbaum.Saunders Distributions with Applications. REVSTAT Stat. J. 2020, 15, 637–660. [Google Scholar]
- Castillo, N.; Gomez, H.W.; Bolfarine, H. Epsilon Birnbaum-Saunders distribution family: Properties and inference. Stat. Pap. 2011, 52, 871–883. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Lemonte, A.J. The exponentiated generalized Birnbaum-Saunders distribution. Appl. Math. Comput. 2014, 247, 762–779. [Google Scholar] [CrossRef]
- Reyes, J.; Barranco-Chamorro, I.; Gallardo, D.I.; Gómez, H.W. Generalized Modified Slash Birnbaum-Saunders Distribution. Symmetry 2018, 10, 724. [Google Scholar] [CrossRef] [Green Version]
- Olmos, N.M.; Martínez-Flórez, G.; Bolfarine, H. Bimodal Birnbaum-Saunders Distribution with Application to Corrosion Data. Commun. Stat. Theory Methods 2017, 46, 6240–6257. [Google Scholar] [CrossRef]
- Bolfarine, H.; Gómez, H.W.; Rivas, L. The log-bimodal-skew-normal model. A geochemical application. J. Chemom. 2011, 25, 329–332. [Google Scholar] [CrossRef]
- Cortés, M.A.; Elal-Olivero, D.; Olivares-Pacheco, J.F. A New Class of Distributions Generated by the Extended Bimodal-Normal Distribution. J. Probab. Stat. 2018, 2018, 9753439. [Google Scholar] [CrossRef]
- Elal-Olivero, D. Alpha-skew-normal distribution. Proyecc. J. Math. 2010, 29, 224–240. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Flórez, G.; Barrera-Causil, C.; Marmolejo-Ramos, F. The Exponential-Centred Skew-Normal Distribution. Symmetry 2020, 12, 1140. [Google Scholar] [CrossRef]
- Garcia-Papani, F.; Uribe-Opazo, M.A.; Leiva, V.; Aykroyd, R.G. Birnbaum-Saunders spatial modelling and diagnostics applied to agricultural engineering data. Stoch. Environ. Res. Risk Assess. 2017, 31, 105–124. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, L.; Leiva, V.; Galea, M.; Saulo, H. Birnbaum-Saunders quantile regression models with application to spatial data. Mathematics 2020, 8, 1000. [Google Scholar] [CrossRef]
- Martinez, S.; Giraldo, R.; Leiva, V. Birnbaum-Saunders functional regression models for spatial data. Stoch. Environ. Res. Risk Assess. 2019, 33, 1765–1780. [Google Scholar] [CrossRef]
- Azzalini, A.; Capitanio, A. Distributions generated by perturbation of symmetry with emphasis on a multivariate skew t-distribution. J. R. Stat. Soc. Ser. B Stat. Methodol. 2003, 65, 367–389. [Google Scholar] [CrossRef]
- Azzalini, A. The skew-normal distribution and related multivariate families. Scand. J. Stat. Theory Appl. 2005, 32, 159–200. [Google Scholar] [CrossRef]
- Elal-Olivero, D.; Gómez, H.W.; Quintana, F.A. Bayesian modeling using a class of bimodal skew-elliptical distributions. J. Stat. Plan. Inference 2009, 139, 1484–1492. [Google Scholar] [CrossRef]
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Prudnikov, A.P.; Brychkov, Y.A.; Marichev, O.I. Integrals and Series; Gordon and Breach Science Publishers: Amsterdam, The Netherlands, 1990; Volumes 1–3. [Google Scholar]
- Hirose, H. Estimation of threshold stress in accelerated life-testing. IEEE Trans. Reliab. 1993, 42, 650–657. [Google Scholar] [CrossRef]
- Ortega, E.M.; Cordeiro, G.; Lemonte, A. A log-linear regression model for the β-Birnbaum-Saunders distribution with censored data. Comput. Stat. Data Anal. 2012, 56, 698–718. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Cavanaugh, J.E. Unifying the derivations for the Akaike and corrected Akaike information criteria. Stat. Probab. Lett. 1997, 33, 201–208. [Google Scholar] [CrossRef]
- Ortega, E.M.; Bolfarine, H.; Paula, G.A. Influence diagnostics in generalized log-gamma regression models. Comput. Stat. Data Anal. 2003, 42, 165–186. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Hartigan, P.M. The dip test of unimodality. Ann. Stat. 1985, 13, 70–84. [Google Scholar] [CrossRef]
Figure 1.
Distribution (a) for (solid line), (dashed line), (dotted line) y (dash-dotted line), (b) for (solid line), (dashed line), (dotted line) and (dash-dotted line) and (c) for (solid line), (dashed line), (dotted line) and (dash-dotted line).
Figure 1.
Distribution (a) for (solid line), (dashed line), (dotted line) y (dash-dotted line), (b) for (solid line), (dashed line), (dotted line) and (dash-dotted line) and (c) for (solid line), (dashed line), (dotted line) and (dash-dotted line).

Figure 2.
EGSHN distribution (a) (solid line), (dashed line), (dotted line) and (dash-dotted line), (b) (solid line), (dashed line), (dotted line) and (dash-dotted line) and (c) (solid line), (dashed line), (dotted line) and (dash-dotted line).
Figure 2.
EGSHN distribution (a) (solid line), (dashed line), (dotted line) and (dash-dotted line), (b) (solid line), (dashed line), (dotted line) and (dash-dotted line) and (c) (solid line), (dashed line), (dotted line) and (dash-dotted line).

Figure 3.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.
Figure 3.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.

Figure 4.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.
Figure 4.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.

Figure 5.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.
Figure 5.
Empirical sd, relative bias, and for the estimators of the model parameters with sample sizes of 30, 60, 90, 120 and 500.

Figure 6.
Normal probability plots for with envelopes of Q-qplots for the scaled residuals, from the fitted models. (a) ESHN and (b) EGSHN.
Figure 6.
Normal probability plots for with envelopes of Q-qplots for the scaled residuals, from the fitted models. (a) ESHN and (b) EGSHN.

Figure 7.
Influence measures for the EGSHN model (a) Cook’s distance, (b) , (c) envelope picture of EGSHN model.
Figure 7.
Influence measures for the EGSHN model (a) Cook’s distance, (b) , (c) envelope picture of EGSHN model.

Figure 8.
(a) Histogram of the variable (amount of DNA in cancer cells) for the EGBS (solid line), EBS (dashed line), BLSN (dotted line), and BSSN (dash-dotted line) adjusted distributions; and (b) empirical cumulative distribution (solid line) and for the EGBS (dashed line), EBS (dotted line), and BLSN (dash-dotted line) models.
Figure 8.
(a) Histogram of the variable (amount of DNA in cancer cells) for the EGBS (solid line), EBS (dashed line), BLSN (dotted line), and BSSN (dash-dotted line) adjusted distributions; and (b) empirical cumulative distribution (solid line) and for the EGBS (dashed line), EBS (dotted line), and BLSN (dash-dotted line) models.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Empirical sd, relative bias, and for the model.
| n | sd | RB | sd | RB | sd | RB | sd | RB | sd | RB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 0.1600 | 0.0903 | 0.1737 | 3.4599 | 1.1505 | 3.8661 | 0.6997 | 0.0677 | 0.7029 | 0.3332 | 0.0386 | 0.3443 | 0.4105 | 0.0177 | 0.4107 | |
| 60 | 0.1339 | 0.0502 | 0.1390 | 2.5812 | 0.7354 | 2.8067 | 0.4756 | 0.0380 | 0.4770 | 0.2737 | 0.0226 | 0.2784 | 0.2818 | 0.0145 | 0.2819 | |
| 0.75 | 90 | 0.1194 | 0.0311 | 0.1216 | 1.9235 | 0.5013 | 2.0651 | 0.4127 | 0.0216 | 0.4132 | 0.2396 | 0.0117 | 0.241 | 0.2252 | 0.0046 | 0.2252 |
| 120 | 0.1087 | 0.0187 | 0.1096 | 1.2017 | 0.3818 | 1.3311 | 0.3681 | 0.0028 | 0.3681 | 0.2147 | 0.0040 | 0.2148 | 0.1897 | 0.0034 | 0.1897 | |
| 500 | 0.0541 | 0.0038 | 0.0542 | 0.3686 | 0.0705 | 0.3834 | 0.1759 | 0.0002 | 0.1759 | 0.1069 | 0.0017 | 0.1069 | 0.0913 | 0.0026 | 0.0913 | |
| 30 | 0.4831 | 0.0640 | 0.4958 | 6.4445 | 1.1316 | 6.6637 | 0.5962 | 0.0201 | 0.5965 | 0.5550 | 0.0531 | 0.5677 | 0.6102 | 0.0124 | 0.6102 | |
| 60 | 0.4162 | 0.0263 | 0.4187 | 1.9279 | 0.5686 | 2.1079 | 0.5113 | 0.0198 | 0.5116 | 0.4404 | 0.0211 | 0.4429 | 0.4255 | 0.0093 | 0.4255 | |
| 1.75 | 90 | 0.3661 | 0.0135 | 0.3669 | 1.2541 | 0.3858 | 1.3811 | 0.4518 | 0.0292 | 0.4527 | 0.3657 | 0.0086 | 0.3662 | 0.3324 | 0.0137 | 0.3325 |
| 120 | 0.3354 | 0.0063 | 0.3356 | 0.8840 | 0.2594 | 0.9657 | 0.4098 | 0.0267 | 0.4107 | 0.3303 | 0.0072 | 0.3307 | 0.2839 | 0.0040 | 0.2839 | |
| 500 | 0.1476 | 0.0012 | 0.1476 | 0.3285 | 0.0486 | 0.3364 | 0.1646 | 0.0101 | 0.1649 | 0.1568 | 0.0001 | 0.1568 | 0.1379 | 0.0036 | 0.1379 | |
| 30 | 0.8355 | 0.0578 | 0.8504 | 5.0777 | 1.0509 | 5.3163 | 0.6025 | 0.0095 | 0.6025 | 0.6021 | 0.0555 | 0.6149 | 0.6722 | 0.0149 | 0.6722 | |
| 60 | 0.7030 | 0.0225 | 0.7056 | 2.2156 | 0.5590 | 2.3687 | 0.5214 | 0.0280 | 0.5221 | 0.4612 | 0.0257 | 0.4648 | 0.4591 | 0.0102 | 0.4591 | |
| 2.75 | 90 | 0.6090 | 0.0079 | 0.6094 | 1.2718 | 0.3672 | 1.3858 | 0.4443 | 0.0301 | 0.4452 | 0.3931 | 0.0139 | 0.3943 | 0.3725 | 0.0151 | 0.3727 |
| 120 | 0.5096 | 0.0104 | 0.5104 | 0.9270 | 0.2499 | 0.9998 | 0.3758 | 0.0157 | 0.3761 | 0.3296 | 0.0127 | 0.3308 | 0.3076 | 0.0022 | 0.3075 | |
| 500 | 0.2182 | 0.0033 | 0.2184 | 0.3371 | 0.0563 | 0.3475 | 0.1417 | 0.0027 | 0.1417 | 0.1525 | 0.0022 | 0.1525 | 0.1496 | 0.0000 | 0.1496 | |
Table 2.
Empirical sd, relative bias, and for the model.
| n | sd | RB | sd | RB | sd | RB | sd | RB | sd | RB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 0.5060 | 0.0784 | 0.5242 | 2.6997 | 1.3552 | 3.0205 | 0.6351 | 0.0473 | 0.6368 | 0.5845 | 0.0553 | 0.5975 | 0.6630 | 0.0204 | 0.6631 | |
| 60 | 0.4768 | 0.0359 | 0.4809 | 1.4215 | 0.6769 | 1.5743 | 0.6234 | 0.0014 | 0.6233 | 0.4910 | 0.0272 | 0.4948 | 0.4506 | 0.0130 | 0.4507 | |
| 1.0 | 90 | 0.4368 | 0.0159 | 0.4376 | 0.7941 | 0.4384 | 0.9071 | 0.5594 | 0.0290 | 0.5601 | 0.4321 | 0.0130 | 0.4330 | 0.3520 | 0.0017 | 0.3520 |
| 120 | 0.3930 | 0.0121 | 0.3935 | 0.5962 | 0.2952 | 0.6652 | 0.5107 | 0.0281 | 0.5115 | 0.3900 | 0.0113 | 0.3908 | 0.3088 | 0.0100 | 0.3088 | |
| 500 | 0.1957 | 0.0000 | 0.1957 | 0.2305 | 0.0703 | 0.2409 | 0.2402 | 0.0121 | 0.2404 | 0.1977 | 0.0005 | 0.1977 | 0.1493 | 0.0026 | 0.1493 | |
| 30 | 0.4612 | 0.0446 | 0.4677 | 6.0222 | 0.7279 | 6.2906 | 0.5485 | 0.0185 | 0.5487 | 0.5092 | 0.0417 | 0.5178 | 0.5756 | 0.0272 | 0.5759 | |
| 60 | 0.3695 | 0.0123 | 0.3701 | 4.8084 | 0.6148 | 5.0476 | 0.4371 | 0.0360 | 0.4386 | 0.3835 | 0.0093 | 0.3841 | 0.3859 | 0.0084 | 0.3859 | |
| 2.5 | 90 | 0.3035 | 0.0089 | 0.3039 | 2.7667 | 0.3974 | 2.9394 | 0.3429 | 0.0270 | 0.3439 | 0.3177 | 0.0083 | 0.3182 | 0.3121 | 0.0062 | 0.3121 |
| 120 | 0.2655 | 0.0026 | 0.2655 | 1.9695 | 0.2684 | 2.0805 | 0.3056 | 0.0274 | 0.3068 | 0.2768 | 0.0029 | 0.2768 | 0.2694 | 0.0026 | 0.2690 | |
| 500 | 0.1129 | 0.0007 | 0.1129 | 0.5670 | 0.0575 | 0.5849 | 0.1213 | 0.0049 | 0.1214 | 0.1257 | 0.0008 | 0.1257 | 0.1270 | 0.0014 | 0.1270 | |
| 30 | 0.4246 | 0.0245 | 0.4267 | 13.3364 | 0.6570 | 13.5521 | 0.5613 | 0.0693 | 0.5655 | 0.4786 | 0.0269 | 0.4824 | 0.5404 | 0.0179 | 0.5406 | |
| 60 | 0.3298 | 0.0048 | 0.3298 | 11.4564 | 0.5569 | 11.7093 | 0.4094 | 0.0631 | 0.4142 | 0.3450 | 0.0060 | 0.3452 | 0.3628 | 0.0054 | 0.3628 | |
| 4.0 | 90 | 0.2629 | 0.0015 | 0.2629 | 5.9366 | 0.4821 | 6.2414 | 0.2938 | 0.0363 | 0.2960 | 0.2792 | 0.0002 | 0.2792 | 0.2922 | 0.0103 | 0.2922 |
| 120 | 0.2210 | 0.0018 | 0.2210 | 5.6103 | 0.3773 | 5.8091 | 0.2506 | 0.0218 | 0.2515 | 0.2328 | 0.0005 | 0.2328 | 0.2498 | 0.0027 | 0.2498 | |
| 500 | 0.0982 | 0.0007 | 0.0982 | 1.0651 | 0.0704 | 1.1016 | 0.1075 | 0.0057 | 0.1076 | 0.1111 | 0.0001 | 0.1111 | 0.1218 | 0.0018 | 0.1218 | |
Table 3.
Empirical sd, relative bias, and for the model.
| n | sd | RB | sd | RB | sd | RB | sd | RB | sd | RB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30 | 0.3354 | 0.0083 | 0.3357 | 5.5409 | 0.7808 | 5.7563 | 0.3244 | 0.0541 | 0.3255 | 0.4508 | 0.0048 | 0.4509 | 0.6493 | 0.0215 | 0.6494 | |
| 60 | 0.2278 | 0.0042 | 0.2279 | 3.0014 | 0.5044 | 3.1661 | 0.2077 | 0.0389 | 0.2086 | 0.2991 | 0.0020 | 0.2991 | 0.4186 | 0.0087 | 0.4186 | |
| 0.50 | 90 | 0.1779 | 0.0055 | 0.1782 | 2.2964 | 0.3269 | 2.3874 | 0.1637 | 0.0189 | 0.1640 | 0.2386 | 0.0014 | 0.2386 | 0.3376 | 0.0011 | 0.3376 |
| 120 | 0.1570 | 0.0008 | 0.1570 | 1.2968 | 0.2010 | 1.3575 | 0.1412 | 0.0246 | 0.1417 | 0.2094 | 0.0011 | 0.2094 | 0.2892 | 0.0046 | 0.2890 | |
| 500 | 0.0711 | 0.0018 | 0.0711 | 0.4458 | 0.0465 | 0.4554 | 0.0639 | 0.0035 | 0.0639 | 0.0955 | 0.0000 | 0.0955 | 0.1374 | 0.0053 | 0.1374 | |
| 30 | 0.4651 | 0.1093 | 0.5029 | 4.9920 | 0.8175 | 5.2525 | 0.9968 | 0.0428 | 0.9988 | 0.5470 | 0.0949 | 0.5872 | 0.5720 | 0.0377 | 0.5727 | |
| 60 | 0.4308 | 0.0552 | 0.4414 | 3.8817 | 0.6443 | 4.0896 | 0.7276 | 0.0189 | 0.7276 | 0.4703 | 0.0479 | 0.4824 | 0.3853 | 0.0162 | 0.3855 | |
| 1.5 | 90 | 0.4041 | 0.0385 | 0.4096 | 2.7730 | 0.4517 | 2.9162 | 0.6860 | 0.0133 | 0.6860 | 0.4268 | 0.0335 | 0.4333 | 0.3179 | 0.0066 | 0.3179 |
| 120 | 0.3746 | 0.0211 | 0.3764 | 1.5575 | 0.3195 | 1.6834 | 0.6473 | 0.0097 | 0.6475 | 0.3894 | 0.0179 | 0.3915 | 0.2758 | 0.0123 | 0.2760 | |
| 500 | 0.2312 | 0.0024 | 0.2312 | 0.5188 | 0.0785 | 0.5420 | 0.3727 | 0.0013 | 0.3738 | 0.2313 | 0.0004 | 0.2313 | 0.1314 | 0.0037 | 0.1314 | |
| 30 | 0.3930 | 0.1271 | 0.4515 | 3.4510 | 0.3915 | 3.5384 | 17.0967 | 0.1390 | 17.0977 | 0.4872 | 0.1168 | 0.5535 | 0.5789 | 0.0631 | 0.5808 | |
| 60 | 0.3635 | 0.0677 | 0.3823 | 3.1596 | 0.3342 | 3.2292 | 8.0921 | 0.1382 | 8.0979 | 0.4215 | 0.0661 | 0.4469 | 0.3792 | 0.0234 | 0.3796 | |
| 3.0 | 90 | 0.3421 | 0.0446 | 0.3508 | 3.0435 | 0.2479 | 3.0834 | 2.4923 | 0.1378 | 2.5170 | 0.4013 | 0.0493 | 0.4163 | 0.3132 | 0.0092 | 0.3133 |
| 120 | 0.3237 | 0.0240 | 0.3264 | 2.0577 | 0.2166 | 2.1026 | 2.0773 | 0.1180 | 2.1181 | 0.3781 | 0.0313 | 0.3846 | 0.2592 | 0.0039 | 0.2592 | |
| 500 | 0.2590 | 0.0113 | 0.2597 | 1.1857 | 0.1159 | 1.208 | 1.6695 | 0.1095 | 1.7197 | 0.2996 | 0.0019 | 0.2996 | 0.1298 | 0.0018 | 0.1290 | |
Table 4.
Estimated parameters, with their standard errors for the SHN, ESHN, and EGSHN models.
| Estimator | SHN | ESHN | EGSHN |
|---|---|---|---|
| 245.9799 | 66.9952 | 7.9489 | |
| (230.85) | (48.8845) | (2.6274) | |
| 9.2750 | 9.3422 | 9.3456 | |
| (0.1595) | (0.1666) | (0.1616) | |
| −0.4217 | −0.4077 | −0.4144 | |
| (0.0190) | (0.0165) | (0.0189) | |
| 0.3572 | 0.4306 | 0.7539 | |
| (0.0536) | (0.0585) | (0.0903) | |
| 0.3070 | 6.1671 | ||
| (0.1166) | (3.3568) | ||
| −0.6493 | |||
| (0.1965) | |||
| AIC | 89.59 | 74.42 | 73.1924 |
| AICC | 93.30 | 78.89 | 78.58 |
Table 5.
Relative change of the estimates of the EGSHN model.
| Observation | ||||||
|---|---|---|---|---|---|---|
| 8 | 0.0752 | 1.0751 | 3.6291 | 4.4136 | 0.2496 | 9.5977 |
| 23 | 0.1942 | 0.0200 | 0.2091 | 1.2090 | 0.0877 | 2.5542 |
| 34 | 0.2357 | 1.5518 | 4.3536 | 1.0540 | 0.3764 | 7.9936 |
| 8, 23 | 0.0839 | 0.8594 | 2.8812 | 5.7076 | 0.3233 | 13.8282 |
| 8, 34 | 0.0253 | 0.6924 | 2.0139 | 3.4098 | 0.1873 | 10.0372 |
| 23, 34 | 0.0731 | 0.9189 | 3.0378 | 0.6211 | 0.2350 | 8.8319 |
| 8, 23, 34 | 0.0326 | 0.6332 | 1.7068 | 5.2954 | 0.2438 | 14.2785 |
Table 6.
Descriptive statistics of the ploidy dataset.
| 3.636 | 1.432 | 0.452 | 0.865 |
Table 7.
Estimated parameters (standard errors) for the fitted models.
| Estimators | BS | BSSN | BLSN | EBS | EGBS |
|---|---|---|---|---|---|
| (0.3145) | 0.5254 | 1.3564 | 0.2033 | 0.2136 | |
| (0.0140) | (0.0263) | (0.0169) | (0.0066) | (0.0082) | |
| 3.5194 | 2.3042 | 0.2066 | 3.7995 | 4.0200 | |
| (0.0698) | (0.032) | (0.0070) | (0.0551) | (0.0643) | |
| 3.9845 | 4.4899 | 5.6760 | |||
| (1.2161) | (1.7541) | (2.5460) | |||
| 7.7814 | −0.2874 | −0.3724 | |||
| (1.2943) | (0.0677) | (0.0701) | |||
| AIC | 745.58 | 698.51 | 671.95 | 668.41 | 637.8484 |
| AICC | 747.68 | 700.68 | 674.20 | 670.58 | 640.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Martínez-Flórez, G.; Elal-Olivero, D.; Barrera-Causil, C. Extended Generalized Sinh-Normal Distribution. Mathematics 2021, 9, 2793. https://doi.org/10.3390/math9212793
AMA Style
Martínez-Flórez G, Elal-Olivero D, Barrera-Causil C. Extended Generalized Sinh-Normal Distribution. Mathematics. 2021; 9(21):2793. https://doi.org/10.3390/math9212793
Chicago/Turabian StyleMartínez-Flórez, Guillermo, David Elal-Olivero, and Carlos Barrera-Causil. 2021. "Extended Generalized Sinh-Normal Distribution" Mathematics 9, no. 21: 2793. https://doi.org/10.3390/math9212793
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.