
Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Previous Work
2. Materials and Methods
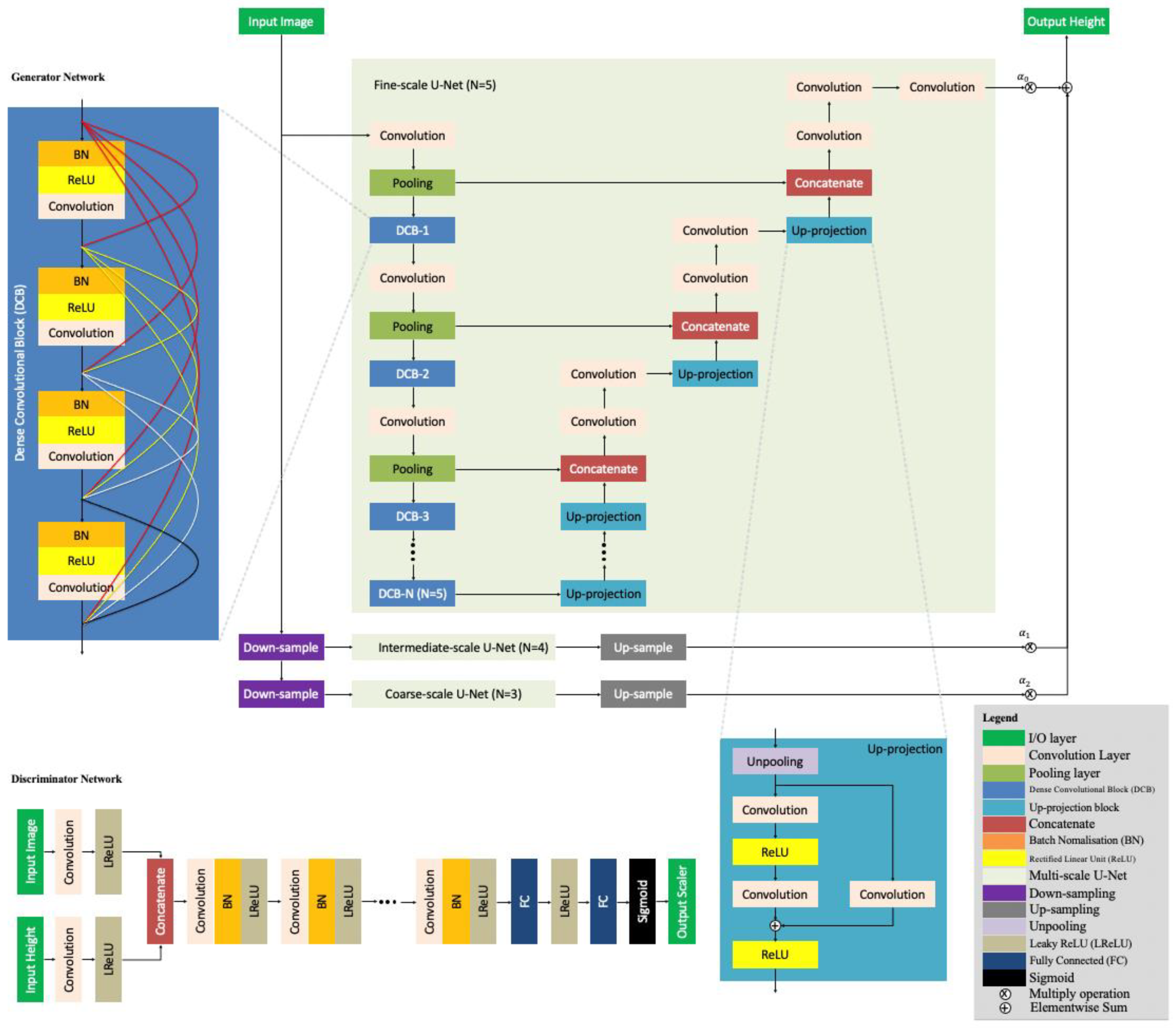
2.1. Network Architecture
2.2. Loss Functions
2.3. Training Dataset
2.4. Training Details
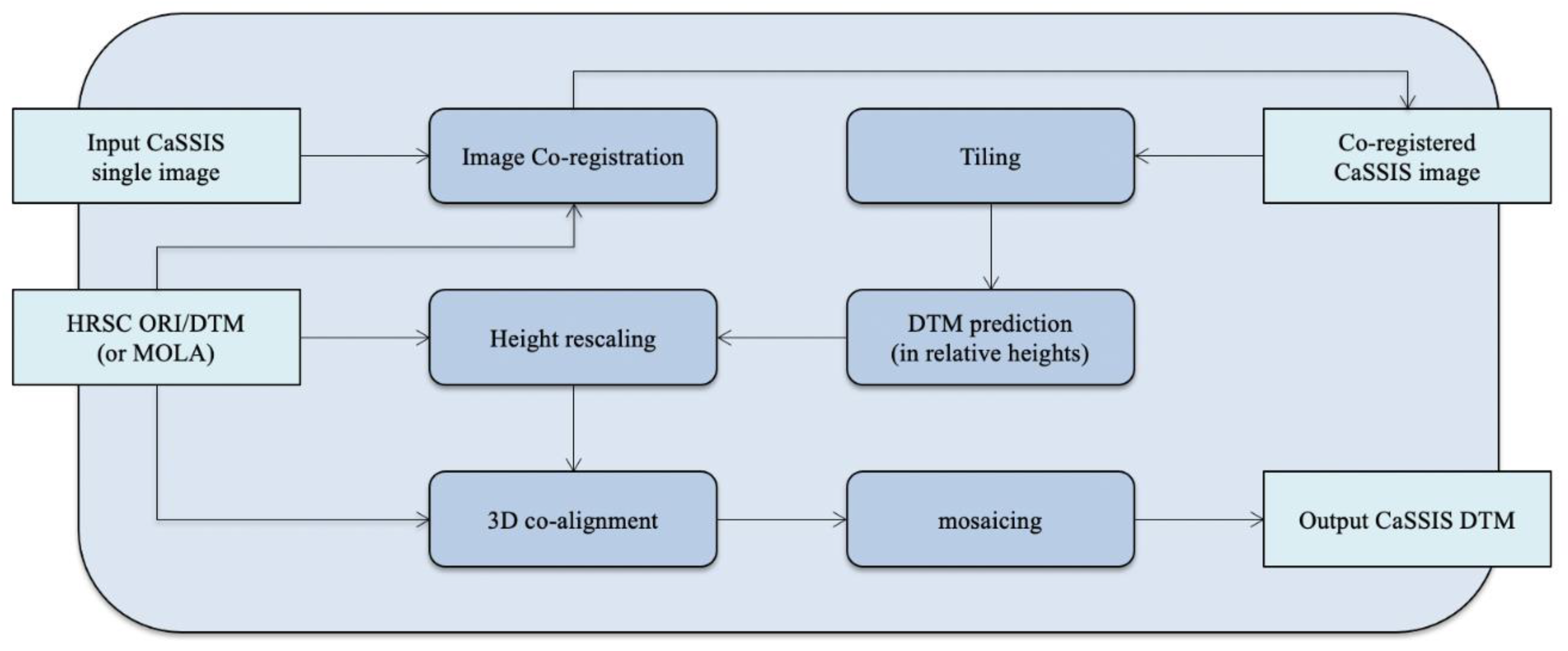
2.5. Overall Processing Chain
2.6. Study Sites
3. Results
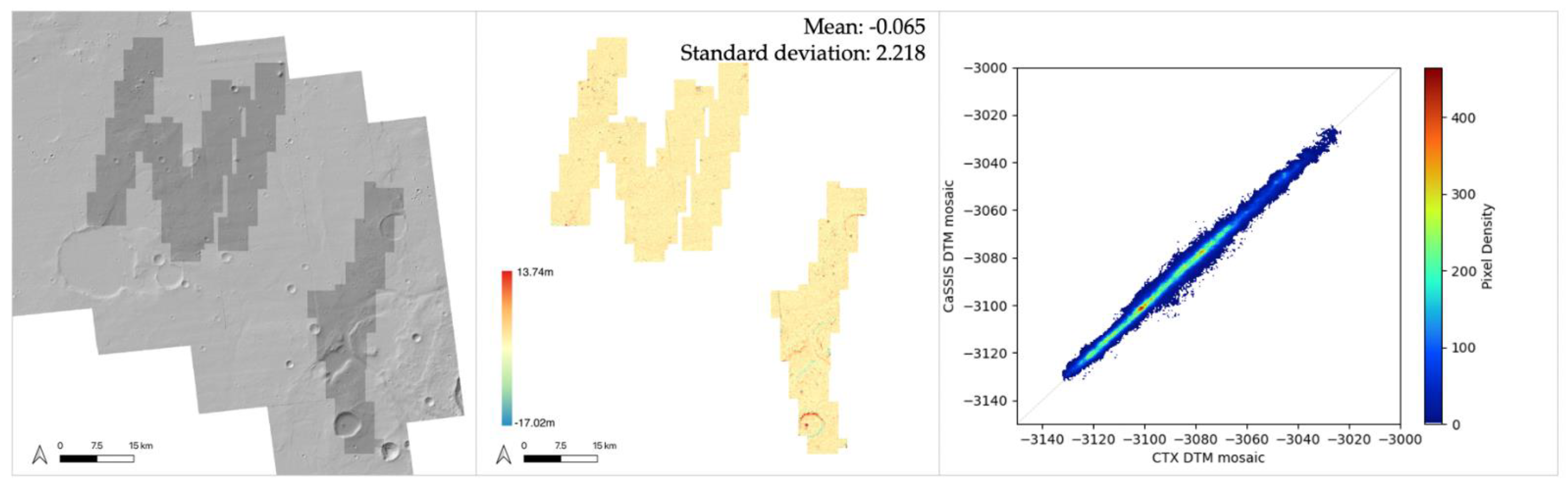
3.1. Overview of Data and Products for Oxia Planum
3.2. Oxia Planum Results and Assessments
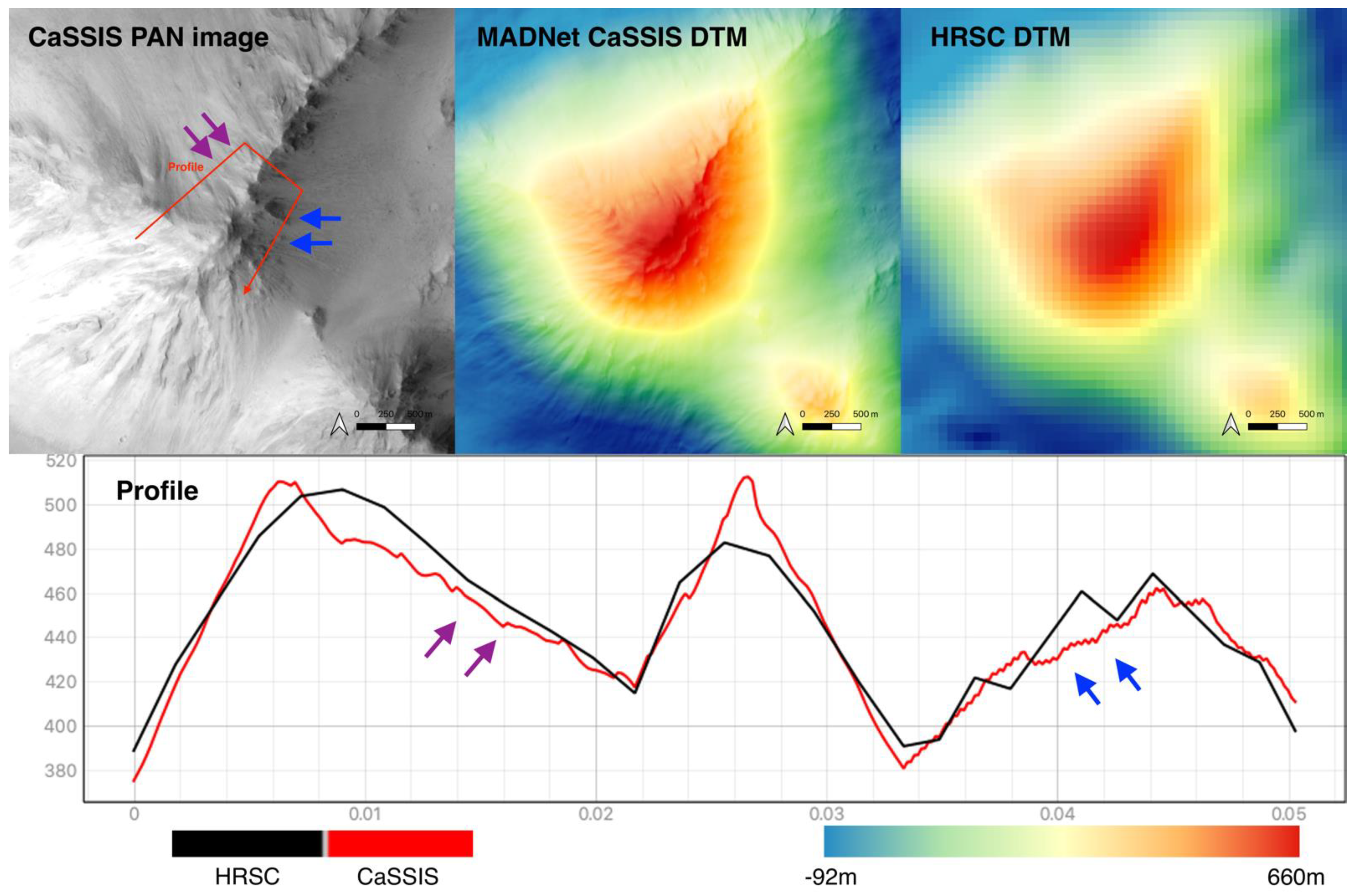
3.3. Science Case Study: Site-1
3.4. Science Case Study: Site-2
4. Discussion
4.1. Photogrammetry, Photoclinometry, or Deep Learning?
4.2. Extendibility with Other Datasets
4.3. Future Improvements
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neukum, G.; Jaumann, R. HRSC: The high resolution stereo camera of Mars Express. Sci. Payload 2004, 1240, 17–35. [Google Scholar]
- Malin, M.C.; Bell, J.F.; Cantor, B.A.; Caplinger, M.A.; Calvin, W.M.; Clancy, R.T.; Edgett, K.S.; Edwards, L.; Haberle, R.M.; James, P.B.; et al. Context camera investigation on board the Mars Reconnaissance Orbiter. J. Geophys. Res. Space Phys. 2007, 112, 112. [Google Scholar] [CrossRef] [Green Version]
- McEwen, A.S.; Eliason, E.M.; Bergstrom, J.W.; Bridges, N.T.; Hansen, C.J.; Delamere, W.A.; Grant, J.A.; Gulick, V.C.; Herkenhoff, K.E.; Keszthelyi, L.; et al. Mars reconnaissance orbiter’s high resolution imaging science experiment (HiRISE). J. Geophys. Res. Space Phys. 2007, 112. [Google Scholar] [CrossRef] [Green Version]
- Thomas, N.; Cremonese, G.; Ziethe, R.; Gerber, M.; Brändli, M.; Bruno, G.; Erismann, M.; Gambicorti, L.; Gerber, T.; Ghose, K.; et al. The colour and stereo surface imaging system (CaSSIS) for the ExoMars trace gas orbiter. Space Sci. Rev. 2017, 212, 1897–1944. [Google Scholar] [CrossRef] [Green Version]
- Meng, Q.; Wang, D.; Wang, X.; Li, W.; Yang, X.; Yan, D.; Li, Y.; Cao, Z.; Ji, Q.; Sun, T.; et al. High Resolution Imaging Camera (HiRIC) on China’s First Mars Exploration Tianwen-1 Mission. Space Sci. Rev. 2021, 217, 1–29. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Smith, D.E.; Zuber, M.T.; Frey, H.V.; Garvin, J.B.; Head, J.W.; Muhleman, D.O.; Pettengill, G.H.; Phillips, R.J.; Solomon, S.C.; Zwally, H.J.; et al. Mars Orbiter Laser Altimeter—Experiment summary after the first year of global mapping of Mars. J. Geophys. Res. 2001, 106, 23689–23722. [Google Scholar] [CrossRef]
- Quantin-Nataf, C.; Carter, J.; Mandon, L.; Thollot, P.; Balme, M.; Volat, M.; Pan, L.; Loizeau, D.; Millot, C.; Breton, S.; et al. Oxia Planum: The Landing Site for the ExoMars “Rosalind Franklin” Rover Mission: Geological Context and Prelanding Interpretation. Astrobiology 2021. [Google Scholar] [CrossRef]
- Bhoi, A. Monocular depth estimation: A survey. arXiv 2019, arXiv:1901.09402. [Google Scholar]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normal and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Shelhamer, E.; Barron, J.T.; Darrell, T. Scene intrinsics and depth from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 37–44. [Google Scholar]
- Ma, X.; Geng, Z.; Bie, Z. Depth Estimation from Single Image Using CNN-Residual Network. SemanticScholar. 2017. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/203.pdf (accessed on 21 July 2021).
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Facil, J.M.; Ummenhofer, B.; Zhou, H.; Montesano, L.; Brox, T.; Civera, J. CAM-Convs: Camera-aware multi-scale convolutions for single-view depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11826–11835. [Google Scholar]
- Wofk, D.; Ma, F.; Yang, T.J.; Karaman, S.; Sze, V. Fastdepth: Fast monocular depth estimation on embedded systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6101–6108. [Google Scholar]
- Li, B.; Shen, C.; Dai, Y.; Van Den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint semantic segmentation and depth estimation with deep convolutional networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar]
- Aleotti, F.; Tosi, F.; Poggi, M.; Mattoccia, S. Generative adversarial networks for unsupervised monocular depth prediction. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Pilzer, A.; Xu, D.; Puscas, M.; Ricci, E.; Sebe, N. Unsupervised adversarial depth estimation using cycled generative networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 587–595. [Google Scholar]
- Feng, T.; Gu, D. Sganvo: Unsupervised deep visual odometry and depth estimation with stacked generative adversarial networks. IEEE Robot. Autom. Lett. 2019, 4, 4431–4437. [Google Scholar] [CrossRef] [Green Version]
- Pnvr, K.; Zhou, H.; Jacobs, D. SharinGAN: Combining Synthetic and Real Data for Unsupervised Geometry Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13974–13983. [Google Scholar]
- Jung, H.; Kim, Y.; Min, D.; Oh, C.; Sohn, K. Depth prediction from a single image with conditional adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1717–1721. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Lore, K.G.; Reddy, K.; Giering, M.; Bernal, E.A. Generative adversarial networks for depth map estimation from RGB video. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1258–12588. [Google Scholar]
- Chen, Z.; Wu, B.; Liu, W.C. Mars3DNet: CNN-Based High-Resolution 3D Reconstruction of the Martian Surface from Single Images. Remote Sens. 2021, 13, 839. [Google Scholar] [CrossRef]
- Tao, Y.; Conway, S.J.; Muller, J.-P.; Putri, A.R.D.; Thomas, N.; Cremonese, G. Single Image Super-Resolution Restoration of TGO CaSSIS Colour Images: Demonstration with Perseverance Rover Landing Site and Mars Science Targets. Remote Sens. 2021, 13, 1777. [Google Scholar] [CrossRef]
- Wang, C.; Li, Z.; Shi, J. Lightweight image super-resolution with adaptive weighted learning network. arXiv 2019, arXiv:1904.02358. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Zwald, L.; Lambert-Lacroix, S. The berhu penalty and the grouped effect. arXiv 2012, arXiv:1207.6868. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tao, Y.; Michael, G.; Muller, J.-P.; Conway, S.J.; Putri, A.R.D. Seamless 3D Image Mapping and Mosaicing of Valles Marineris on Mars Using Orbital HRSC Stereo and Panchromatic Images. Remote Sens. 2021, 13, 1385. [Google Scholar] [CrossRef]
- Tao, Y.; Muller, J.-P.; Poole, W.D. Automated localisation of Mars rovers using co-registered HiRISE-CTX-HRSC orthorectified images and DTMs. Icarus 2016, 280, 139–157. [Google Scholar] [CrossRef] [Green Version]
- Beyer, R.; Alexandrov, O.; McMichael, S. The Ames Stereo Pipeline: NASA’s Opensource Software for Deriving and Processing Terrain Data. Earth Space Sci. 2018, 5, 537–548. [Google Scholar] [CrossRef]
- Marra, W.A.; Hauber, E.; de Jong, S.M.; Kleinhans, M.G. Pressurized groundwater systems in Lunae and Ophir Plana (Mars): Insights from small-scale morphology and experiments. GeoResJ 2015, 8, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Irwin, R.P., III; Watters, T.R.; Howard, A.D.; Zimbelman, J.R. Sedimentary resurfacing and fretted terrain development along the crustal dichotomy boundary, Aeolis Mensae, Mars. J. Geophys. Res. Planets 2004, 109. [Google Scholar] [CrossRef] [Green Version]
- Kite, E.S.; Howard, A.D.; Lucas, A.S.; Armstrong, J.C.; Aharonson, O.; Lamb, M.P. Stratigraphy of Aeolis Dorsa, Mars: Stratigraphic context of the great river deposits. Icarus 2015, 253, 223–242. [Google Scholar] [CrossRef]
- Mackwell, S.J.; Stansbery, E.K. Lunar and Planetary Science XXXVI: Papers Presented at the Thirty-Sixth Lunar and Planetary Science Conference, Houston, TX, USA, 14–18 March 2005; Lunar and Planetary Institute: Houston, TX, USA, 2005. [Google Scholar]
- Conway, S.J.; Butcher, F.E.; de Haas, T.; Deijns, A.A.; Grindrod, P.M.; Davis, J.M. Glacial and gully erosion on Mars: A terrestrial perspective. Geomorphology 2018, 318, 26–57. [Google Scholar] [CrossRef] [Green Version]
- Guimpier, A.; Conway, S.J.; Mangeney, A.; Mangold, N. Geologically Recent Landslides on Mars. In Proceedings of the 51st Lunar and Planetary Science Conference, The Woodlands, TX, USA, 16–20 March 2020; Volume 51. [Google Scholar]
- Sefton-Nash, E.; Catling, D.C.; Wood, S.E.; Grindrod, P.M.; Teanby, N.A. Topographic, spectral and thermal inertia analysis of interior layered deposits in Iani Chaos, Mars. Icarus 2012, 221, 20–42. [Google Scholar] [CrossRef] [Green Version]
- Douté, S.; Jiang, C. Small-Scale Topographical Characterization of the Martian Surface with In-Orbit Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 447–460. [Google Scholar] [CrossRef]
- Tao, Y.; Muller, J.-P.; Sidiropoulos, P.; Xiong, S.-T.; Putri, A.R.D.; Walter, S.H.G.; Veitch-Michaelis, J.; Yershov, V. Massive Stereo-based DTM Production for Mars on Cloud Computers. Planet. Space Sci. 2018, 154, 30–58. [Google Scholar] [CrossRef]
- Tao, Y.; Douté, S.; Muller, J.-P.; Conway, S.J.; Thomas, N.; Cremonese, G. Ultra-high-resolution 1m/pixel CaSSIS DTM using Super-Resolution Restoration and Shape-from-Shading: Demonstration over Oxia Planum on Mars. Remote. Sens. 2021, 13, 2185. [Google Scholar] [CrossRef]
- Sengupta, S.; Kanazawa, A.; Castillo, C.D.; Jacobs, D.W. SfSNet: Learning Shape, Reflectance and Illuminance of Facesin the Wild’. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6296–6305. [Google Scholar]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, Y.; Xiong, S.; Conway, S.J.; Muller, J.-P.; Guimpier, A.; Fawdon, P.; Thomas, N.; Cremonese, G. Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets. Remote Sens. 2021, 13, 2877. https://doi.org/10.3390/rs13152877
Tao Y, Xiong S, Conway SJ, Muller J-P, Guimpier A, Fawdon P, Thomas N, Cremonese G. Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets. Remote Sensing. 2021; 13(15):2877. https://doi.org/10.3390/rs13152877
Chicago/Turabian StyleTao, Yu, Siting Xiong, Susan J. Conway, Jan-Peter Muller, Anthony Guimpier, Peter Fawdon, Nicolas Thomas, and Gabriele Cremonese. 2021. "Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets" Remote Sensing 13, no. 15: 2877. https://doi.org/10.3390/rs13152877