1. Introduction
Many benefits of forests are strongly influenced by forest structure and density. For example, forest regeneration after timber harvesting or wildfire affects forest structure and density, which can have dramatic effects on forest hydrology, forest growth rates, carbon stores and wildlife habitat. Advancements in Light Detection and Ranging (LiDAR) sensors are providing opportunity for detailed analysis of forest structure and density at unprecedented spatial scales. At landscape spatial scales, LiDAR data are being collected from forests across the world with fine scale information on individual trees and stand structure. New algorithms for analysing these large datasets are being developed and applied to produce information useful for forest management, particularly in the boreal forests of the northern hemisphere [
1].
In south-eastern Australia, wildfires have burnt approximately 3 million hectares of forested land since 2003, and in addition, intensive forest harvesting in recent decades has stimulated large-scale changes in forest age. In tall eucalypt forests, replacing old forest with young healthy regenerating forest leads to an overall decline in catchment water yields over the forest regeneration period [
2,
3,
4,
5]. Understanding and managing water security in Australia depends critically on the availability of efficient methods for quantifying the relationship between forest water use and changes in forest structure and density over the post-disturbance regeneration period.
Characterising forests with LiDAR data is commonly done on two spatial scales: (i) area based, where the biophysical variables are averaged over an area encompassing several trees; and (ii) tree based, where individual tree dimensions are estimated using individual tree detection (ITD) algorithms. In ecohydrology research, forest transpiration (T) is commonly derived from tree-scale measurements of sapwood area (SA1.3) at 1.3 m, and therefore using ITD algorithms to characterise biophysical properties of forests at the individual tree-scale may prove useful for scaling T from a tree-to-landscape level.
Compared to LiDAR research in boreal forests (see [
1] for review), relatively few studies have published LiDAR based estimates of forest biophysical properties in eucalypt forests of Australia. Haywood and Sutton [
6] estimated plot-level basal area per hectare (
BAHa) in
Eucalyptus regnans forests of south eastern Australia using simple predictor variables such as height percentiles and summary statistics of the vertical vegetation profile (
r2 = 0.56; RMSE = 14.7 m
2). Jaskierniak
et al. [
7] characterised a multilayered
E. regnans forest structure using mixture distribution functions to predict plot-level
BAHa with
r2 ranging from 0.6 to 0.89 in 18, 37 and 70 year old stands. In mixed species eucalyptus forests (
MSEF), [
8] derived plot level LiDAR indices using a Weibull distribution function, height percentiles, and summary statistics to predict stand
BAHa and sapwood area per hectare (
SAHa) with
r2 of 0.88 and 0.7 respectively.
Kaartinen
et al. [
9,
10] provide a comprehensive review of ITD methods, all of which have been applied in the northern hemisphere. Kaartinen and Hyyppa [
11] evaluated the quality, accuracy and feasibility of ITD methods in boreal forests and reported large variation in the quality of published methods with varying laser point densities. It has been shown that ITD performs best with laser scanning density of 5–10 pulses·m
−2, which is higher than the 0.9 and 4 pulses·m
−2 available over our study sites. Several studies undertaken in Scandinavian and European forests have demonstrated that it is possible to detect 40%–70% of all trees using an ITD approach [
12,
13]. In deciduous forests, the complex crown shape and structure results in generally lower success rates [
14,
15]. In North American forests, success rates have been largely dependent on canopy density [
16]. Persson
et al. [
12,
17] used the same ITD algorithm and managed detection rates of 71% for Scandinavian forest dominated by spruce and pine, 51% for coniferous forests, 45% for Bavarian Forest National Park, and 40% for deciduous forests. These studies suggest that ITD rates are highly dependent on forest structure. To our knowledge, we demonstrate for the first time the potential use of ITD methods in native eucalypt forests, which represent a forest structure substantially different to those of previous studies.
Most ITD algorithms generate canopy height models (CHM) to locate local height maxima in LiDAR data, which are then considered representative of the stem positions within the forest [
18,
19,
20]. Using this approach, point clouds are typically segmented into crown diameters using watershed algorithms [
21], slope-based segmentation methods [
12], or gridded methods smoothed with Gaussian filters [
20]. More advanced ITD methods recognise that heterogeneous multilayered forests, such as
E. regnans forests in our study, require a 3D approach to address the segmentation problem [
22,
23,
24]. In
E. regnans forest, an ITD algorithm needs to be robust enough to differentiate different vegetation strata down the vertical profile, whilst accurately handling different sized overstorey crowns across a heterogeneous forest landscape.
The overarching aim of our project is to acquire an accurate and robust measure of spatial variability in
T per hectare across Melbourne’s forested water catchments. This required us to develop a methodology that uses LiDAR indices to estimate
SAHa, a well-established proxy for
T. Our research was conducted in forested catchments supplying approximately 90% of the water used by the city of Melbourne. Considering Melbourne’s water catchments consist of approximately 155,000 ha of forested land, predicting tree-specific
SA1.3 across the landscape is not strictly required by the water management agency—a relationship between plot-level LiDAR indices and
SAHa is sufficient for water yield assessment purposes. We argue that a more robust and accurate relationship between plot-level LiDAR indices and field measured
SAHa will eventuate if an ITD algorithm removes within-plot LiDAR points that represent trees outside the plot, and includes LiDAR points outside of plots if they represent measured trees within-plots. To confirm this, we compare our ITD derived
BAHa estimates to those of [
7] who characterised the forest structure across five of the same permanent plot catchments using an area-based mixture distribution function method.
To the authors’ knowledge, [
8] is the only study that has used LiDAR to capture within catchment variation in
SAHa and demonstrated that forest heterogeneity across an elevation gradient was associated with a threefold change in annual
T. They applied a
SA1.3/
BA1.3 relationship (
R1.3) to predict plot-level
SAHa from plot-level
BA1.3 measurements
, and regressed the
SAHa estimate against explanatory variables derived from
LiDAR data to spatially extrapolate
SAHa across two catchments (136 ha and 87 ha).
Adopting this approach requires the assumption that
R1.3 is constant across Melbourne’s water catchments. Recently, [
25] have shown high spatial variability in
R1.3 and the
SAHa/BAHa relationship (
RHa) across the landscape, and provide a more consistent species-specific relationship observed between
SAHa and an index of total sapwood perimeter per hectare, defined as
, where
SDen is stocking density of overstorey trees per hectare. In order to determine how well LIDAR may estimate
we evaluate our ability to predict
BAHa and
SDen across all sites. We also measured
SA1.3 across an intensively studied 5 ha site in order to determine how well the perimeter index may be used to scale tree-level
SA1.3 to a stand- and landscape-level using LiDAR data. The following questions are addressed in the present study:
Can LiDAR data with less than 1 pulse per m2 identify individual trees within a dense E. regnans forest, and if so what is the ITD rate?
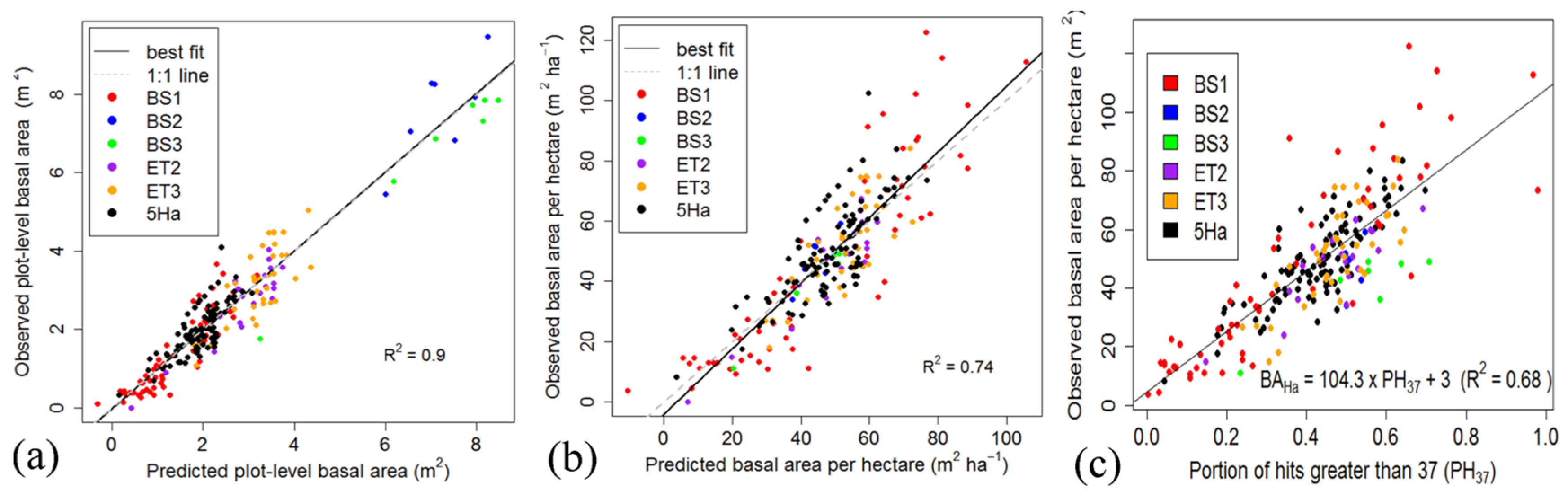
Can ITD methods improve predictions of stand BAHa in E. regnans forests compared to previous area based methods applied to the same sites?
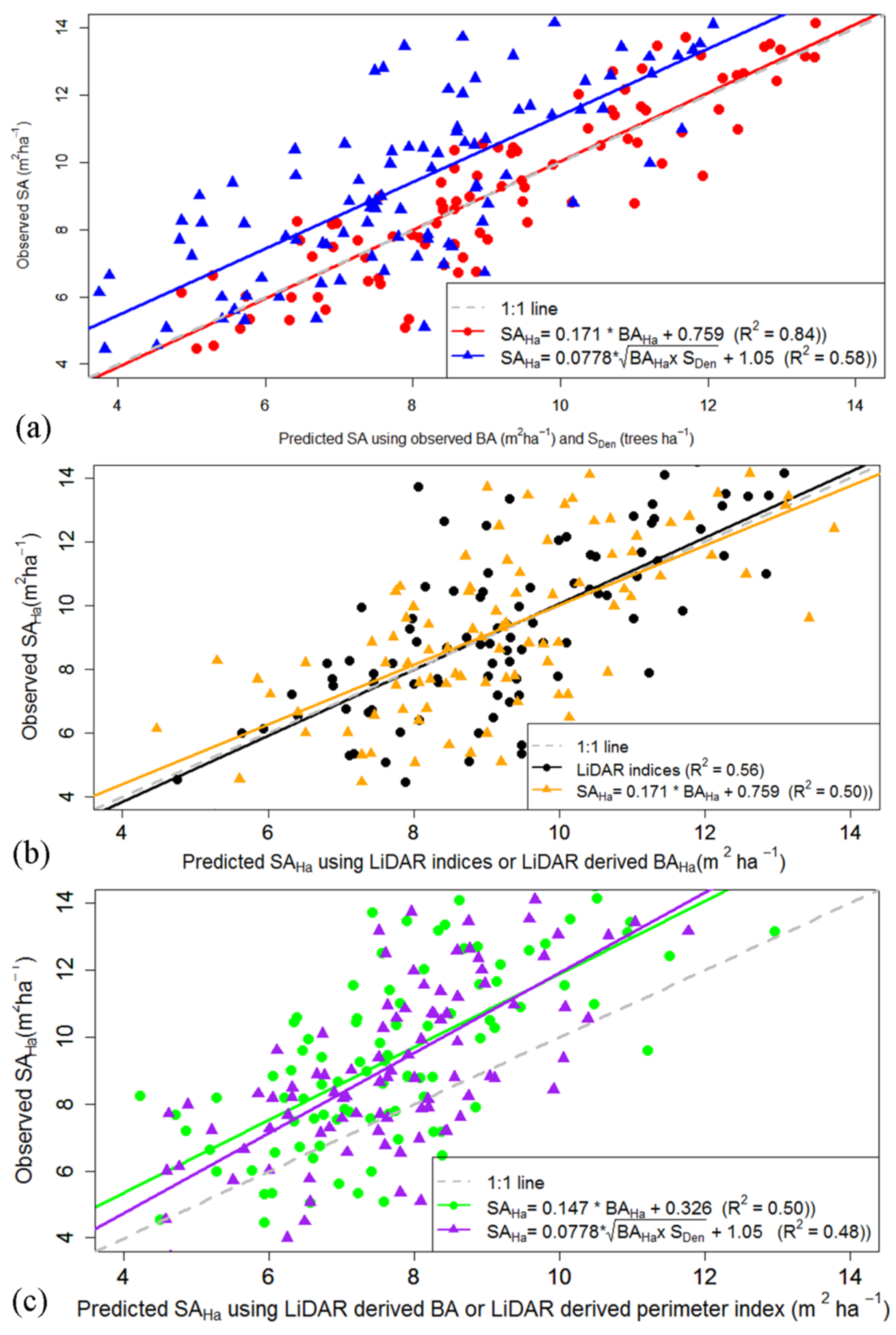
Is it more accurate to predict stand SAHa with: (i) a RHa relationship and BAHa estimates derived from LiDAR; (ii) a stand perimeter index that relies on accurate SDen and BAHa estimates; or (iii) LiDAR indices directly related to stand SAHa?
4. Discussion
In recent decades, the increased frequency of wildfires and timber harvesting in forests of southeastern Australia has meant that managers of forested catchments need a better understanding of how such disturbances will affect streamflow. There is a growing body of evidence that spatial variation in
T across the landscape is largely due to the spatial pattern in stand SA [
8,
25,
42,
43], whereas decadal variation in mean annual T is largely due to temporal changes in stand SA [
4,
44,
45]. Recent LiDAR data acquisition flights across more than 500,000 ha of southeastern Australian forests provide a rich source of information on forest structure, which may be used to scale
T from a tree- or stand-level to a landscape-level with an improved understanding of how forest structure relates to SA.
To the authors’ knowledge, the present study is the first attempt to use an ITD algorithm in native eucalypt forests, and in doing so we predicted
SDen with the LMF method and
SDen,
BAHa and
SAHa with the NCut method. We found the ITD algorithms performed well in
E. regnans forests as our ITD rates of 72% and 68%, using only 0.9 LiDAR pulses·m
−2, were similar to studies in Scandinavian and European forests that used LiDAR with 3–10 pulses·m
−2 [
15,
20,
46]. Our LiDAR data resolution was more comparable to [
47], who used 1 pulse·m
−2 in forests with Scots pine (
Pinus sylvestris), Norway spruce (
Picea abies) and birch (
Betula sp.) to detect 52% of trees with a minimum curvature-based regional detector applied to a smoothed CHM.
4.1. Improving the NCut Algorithm
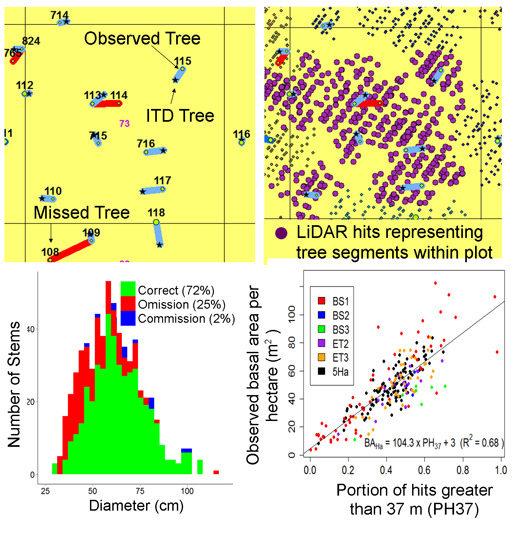
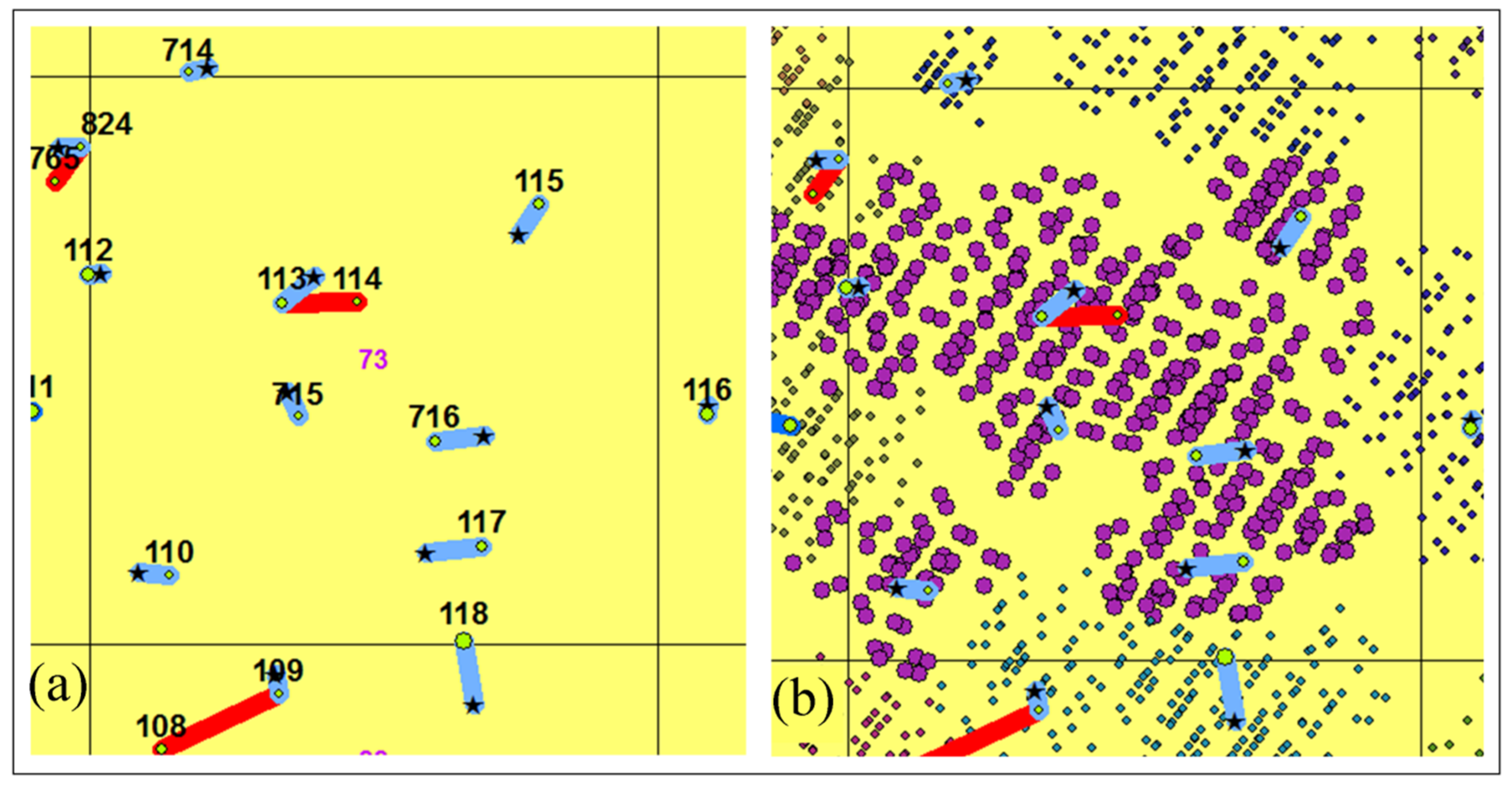
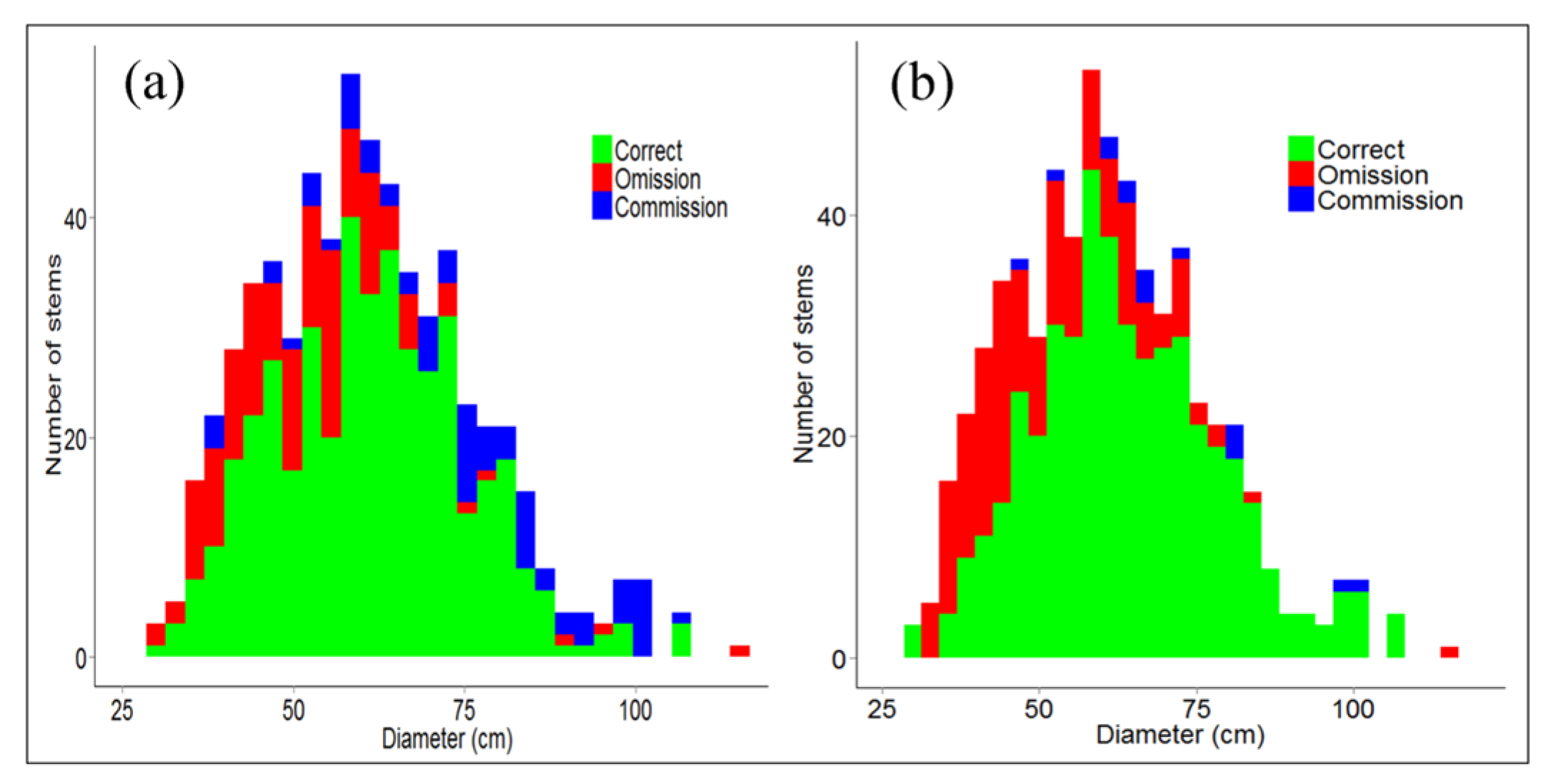
In this study, we have calibrated the NCut algorithm with one set of parameter values across a 5 ha 69 year old E. regnans forest. In order to apply the NCut algorithm across a broad range of existing age classes, age-specific calibration of the NCut algorithm will be required due to changes in forest structure with age. Even within one age class, substantial variation in canopy crown size was evident due to the spatial distribution of SDen and BA1.3, resulting in higher omission and commission rates within respectively high and low stocking density stands. Improved ITD rates may be achieved with a procedure that spatially varies the NCut parameter values with prior knowledge of the distribution of tree-crown forms across the landscape.
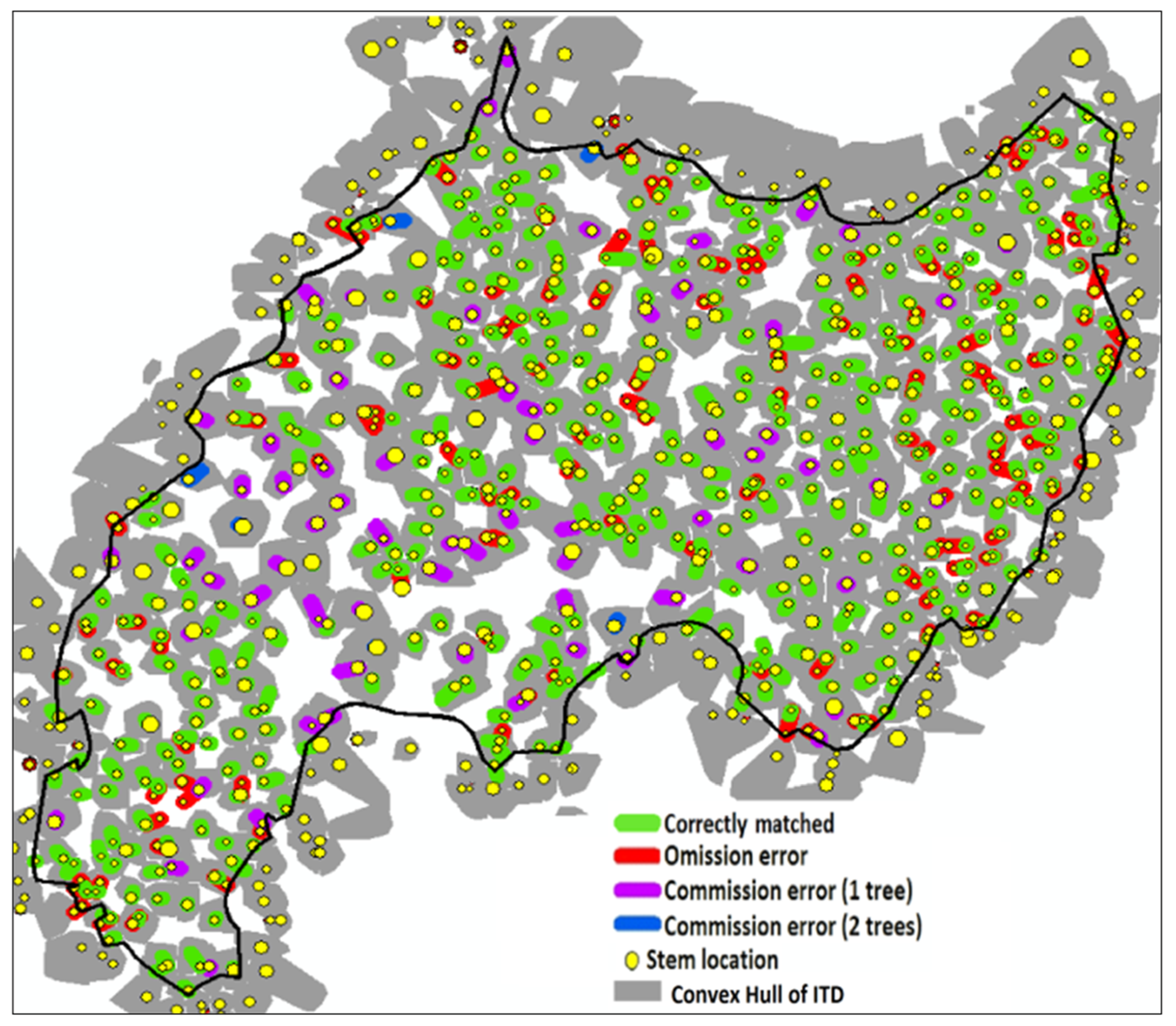
Figure 7 shows that this may be achieved with an efficient preliminary screening procedure capable of capturing the heterogeneity of canopy gaps across the landscape. Using each stem’s LiDAR points greater than 37 m, a 2D convex hull is provided in
Figure 7 to show how well the heterogeneity in tree-crown form explains the distribution of stem commission and omission errors. Commission errors were more frequent in stands with large canopy gaps, as over-segmentation occurred for large tree canopies that extended towards large adjacent gaps.
To correct for this systematic
SDen bias, it would be necessary to segment the forested landscape into homogenous units characterised with canopy gap features and then apply varying sets of NCut parameter values calibrated to best segment forests with specific canopy gap features (see [
48]). St-Onge
et al. [
49] have reviewed LiDAR based techniques that may be applied to automatically detect and characterise canopy gaps. The accuracy and resolution output of existing techniques is adequate for our purposes, considering [
50] used an automated object-based technique to delineate canopy gaps with an accuracy of 96%, whereas [
51] used multi-temporal LiDAR to identify newly opened gaps less than 1 m
2 in size.
Figure 7.
A convex hull of each LiDAR segment, used to represent the crown canopy of each stem, showing that stems with commission error were adjacent to larger canopy gaps than stems with omission error.
Figure 7.
A convex hull of each LiDAR segment, used to represent the crown canopy of each stem, showing that stems with commission error were adjacent to larger canopy gaps than stems with omission error.
5. Conclusions
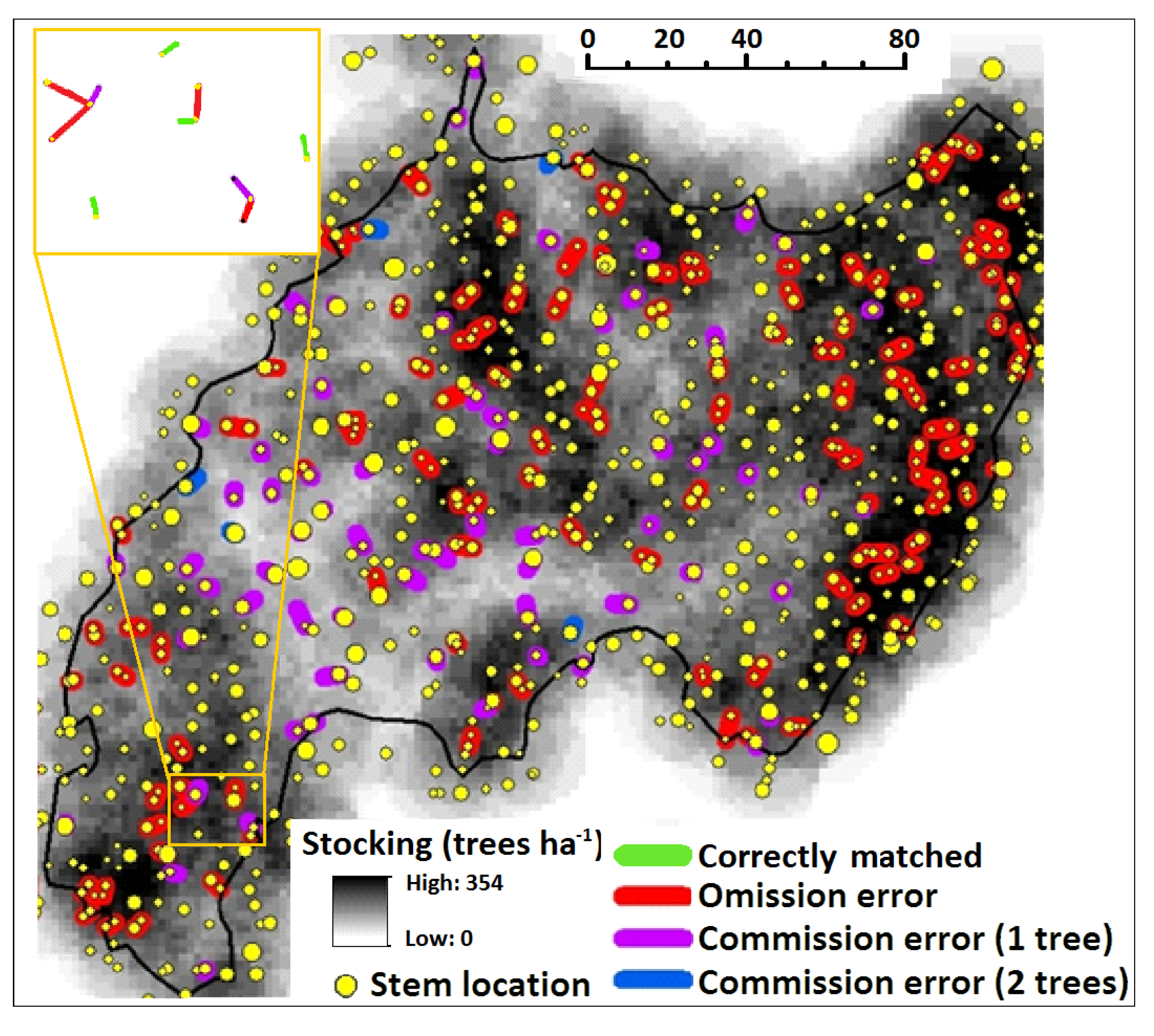
For even-aged forests, LiDAR data with as few as 0.9 pulses·m−2 was able to be used with the LMF and NCut methods to determine SDen and BAHa with moderate to high accuracy over large areas. Among 619 trees in a 69 year old E. regnans forest, the respective ITD rates were 72% and 68% using the LMF and NCut methods, with 25% and 20% of stems missed, and 2% and 12% of stems over-segmented. Given these similar ITD rates, we conclude that significantly lower computational requirements make the bias-corrected LMF method more suitable for predicting SDen across large forest areas.
For estimating BAHa with plot resolution of the order of 0.04 ha, the NCut algorithm was a significant improvement over an area based method with mixture distribution functions, explaining 7% to 30% (median: 9%) more variation in BAHa for individual catchments. When applied to all catchments, we were able to produce a model that explained 68% of BAHa using only the PH37 index that applies the NCut ITD segments. We demonstrate that this model may be extrapolated for one ha resolution estimates without the need to compute ITD segments. The two-step procedure involves calculating BAHa estimates by averaging PH37 values calculated for each 20 m × 20 m grid cell over 100 m × 100 m grid cells.
Although the relationship between observed and predicted SAHa was most accurate when directly relating SAHa to LiDAR indices (R2 = 0.56), a two-step procedure that used the stem perimeter index to predict SAHa (R2 = 0.48) was computationally more efficient. We conclude that a pragmatic approach for extrapolating SAHa across large water catchments involves using a one ha resolution grid to estimate: (i) SDen with the bias-corrected LMF method; (ii) BAHa with a parsimonious model consisting of one explanatory variable, PH37; and (iii) SAHa with the perimeter index using the BAHa and SDen estimates.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







