An Iterative Nonlinear Filter Using Variational Bayesian Optimization


1
School of Automation, Northwestern Polytechnical University, Xi’an 710072, China
2
Key Laboratory of Information Fusion Technology, Ministry of Education, Xi’an 710072, China
3
School of Engineering, RMIT University, Melbourne 3000, Australia
4
Department of Electrical and Electronic Engineering, University of Melbourne, Melbourne, VIC 3010, Australia
*
Author to whom correspondence should be addressed.
Sensors 2018, 18(12), 4222; https://doi.org/10.3390/s18124222
Submission received: 11 October 2018
/
Revised: 23 November 2018
/
Accepted: 28 November 2018
/
Published: 1 December 2018
(This article belongs to the Section Physical Sensors)
Abstract
:We propose an iterative nonlinear estimator based on the technique of variational Bayesian optimization. The posterior distribution of the underlying system state is approximated by a solvable variational distribution approached iteratively using evidence lower bound optimization subject to a minimal weighted Kullback-Leibler divergence, where a penalty factor is considered to adjust the step size of the iteration. Based on linearization, the iterative nonlinear filter is derived in a closed-form. The performance of the proposed algorithm is compared with several nonlinear filters in the literature using simulated target tracking examples.
1. Introduction
Bayesian estimation is widely applied across many areas of engineering such as target tracking, aerial surveillance, intelligent vehicles, and machine learning [1]. In linear Gaussian systems, the state estimation can be optimally achieved using a Kalman filter as a closed form solution. However, many real-world estimation problems are nonlinear, resulting in analytically intractable posterior probability density function (PDF) for the state. In consequence, suboptimal approximation methods are sought to solve the nonlinear estimation problems [2].
Many suboptimal techniques have been developed to solve nonlinear estimation problems. These techniques may be divided into the following three categories. The first category, includes the extended Kalman filter (EKF) [3], the iterated extended Kalman filter (IEKF) [4,5], and their variants [6,7], solves the state estimation problem through replacing the nonlinear functions by their linear approximations via the Taylor expansion. The second category involves stochastic sampling methods. In the filtering process, a set of randomly sampled points with weights are adopted to approximate the PDF of the underlying state. For example, the particle filter (PF) [8,9,10] is a sequential Monte Carlo (SMC) stochastic sampling method, which approximates the PDF by the sampled particles from a proposal distribution. PF can be applied to nonlinear non-Gaussian systems. Markov Chain Monte Carlo (MCMC) is another popular stochastic method since it is able to achieve arbitrarily high accuracy using a large number of particles, sometimes resulting in prohibitive computational expenditure. The techniques in the third category use deterministic sampling methods. Nonlinear state PDFs are approximated by a set of fixed points and weights that represent the location and spread of the distribution. This category includes the unscented Kalman filter (UKF) [9,11,12], the cubature Kalman filter (CKF) [13,14], and the central difference Kalman filter (CDKF) [15]. The UKF and the CDKF approximate the nonlinear state transition function and the measurement function by the unscented transform (UT) and the Stirling interpolation, respectively. The state and the corresponding error covariance are then calculated based on the sampling points and the weights. The CKF uses the third order spherical-radial cubature rule to approximate integrals numerically.
Where nonlinear filters involve optimisation, quasi-Newton approximations are used, along with Kullback-Leibler (KL) divergence and -divergence as objective functions. For example, the EKF update step may use a Hessian correction term, resulting in improved performance [7,16]. Another approach for estimation, in some ways can be regarded as the fourth category, uses the variational Bayes (VB) technique. VB has a unified and principled architecture and can be used, as with other methods mentioned earlier, for problems where analytic solutions cannot be found. The objective of the VB approximation is to find the variational distribution best able, in the sense of the KL divergence, to approximate the true PDF [17,18,19]. Various variational inference methods for parametric distributions are discussed in [20], where the true PDF of hidden variables is assumed to be given by a parametric model. Since VB usually runs faster than MCMC [20,21,22], it is widely applied in areas such as statistics, finite element analysis, machine learning, etc. An important concern with the VB inference is the accuracy of the approximation [23]. Paul [24] and Stephane et al. [25] introduced a proximal point algorithm in the framework of the expectation-maximization (EM) and studied its convergence. Khan et al. [18,26] adopted KL divergence as a measure of divergence to improve the accuracy of VB inference by considering the geometry of the true posterior PDF. They applied their algorithm to parameter estimation, data set classification and regression.
In this paper, we adopt KL divergence as a metric of posterior PDF approximation, and derive an alternative nonlinear estimation algorithm based on the VB technique. The posterior PDF of the underlying system state is approximated by a parameterized variational distribution and the difference between the two distributions is minimized iteratively using a weighted KL divergence criterion. This is carried out through optimization of the evidence lower bound (ELBO); the intractable integration of the posterior PDF is converted to a solvable optimization problem. A penalty factor is applied to ensure that the filter algorithm obtains a good trade-off between accuracy and computational overhead. Numerical simulations of two typical target tracking scenarios and a benchmark nonlinear filtering problem are presented. The simulation results show that the approximation of nonlinear stochastic system state by the proposed algorithm is tighter than EKF and UKF. The computational cost and the effect of different penalty factors on estimation accuracy are analyzed.
The rest of the paper is organized as follows. In Section 2, we introduce the general nonlinear Bayesian filtering problem. The formulation of the ELBO is described in Section 3. In Section 4, we propose the proximal iterative nonlinear filter. In Section 5, we present simulations of two target tracking scenarios, where the performance of the proposed algorithm is compared with those of EKF and UKF in terms of estimation accuracy and computational overhead. Lastly, conclusions are drawn in Section 6.
2. Problem Formulation
Consider a general dynamic system with measurement as follows.
where denotes the state transition function, and denotes the mapping from the system state to the measurement; and are the process noise and the measurement noise, respectively. We assume that and are Gaussian and mutually independent, and .
Assuming that the posterior PDF at time is available, the PDF of the predicted state is obtained by the Chapman-Kolmogorov equation.
Then, at time k, the posterior PDF is obtained using the measurement by an application of the Bayes rule:
For linear Gaussian systems, it is well known that the optimal state estimation and the corresponding error covariance under the criterion of minimum variance estimation are obtained by:
For nonlinear systems, the integral in Equation (4) is often intractable. Suboptimal approximations for the posterior PDF are needed. Most existing suboptimal algorithms adopt linearization or sampling techniques to approximate the posterior PDF . We consider an iterative VB approach, in which the true PDF is approximated by a variational distribution and is approached by iterative optimization of the ELBO. The proposed algorithm converts the nontrivial integration to a closed-form optimization and therefore improves estimation accuracy.
3. Evidence Lower Bound Maximization
The above nonlinear estimation problem can be solved using a VB framework. Express the marginal PDF using a variational distribution as follows:
where is the KL divergence between the true posterior PDF and the variational distribution ; that is,
is the variational ELBO:
The variational distribution is assumed Gaussian with unknown parameter (to be estimated), where is the mean and is the covariance.
Please note that the poterior PDF needs to be closely approximated by a known distribution in nonlinear filtering. From Equation (7), evidently, the variational distribution would be equal to the true posterior PDF if the KL divergence were zero. Minimizing the KL divergence, and thereby approximating the posterior PDF by a variational distribution, is equivalent to maximizing the ELBO, i.e.,
4. Proximal Iterative Nonlinear Filter
In this section, we derive an iterative procedure in a closed-form to iteratively maximize the ELBO so as to minimize the KL divergence between the true posterior PDF and the variational distribution .
4.1. Penalty Function Based on KL Divergence
Notice that the KL divergence is nonnegative for all . Following [24], we adopt the proximal point algorithm to generate a sequence via the following iterative scheme,
where i denotes the iteration index and the penalty factor is used to adjust the optimization step length. Roughly speaking, the ELBO is maximized when the KL divergence between the two variational distributions and approaches zero. Equation (11) can be rewritten as
Please note that one iteration of this proximal method is equivalent to moving a step in the direction of the natural gradient [18]. The influence of the KL divergence on can be adjusted by . The larger the , the weaker the influence of the KL divergence on , and vice versa. In [18], it is assumed that .
4.2. The Proximal Iterative Nonlinear Filter
The proximal iterative method is implemented via an iterative minimization of the KL divergence, where the initial state is assigned with an estimation from a core-filter, e.g., Bayesian filter. Here, EKF is adopted as the core-filter to predict and update the system state before the iterative optimization process. We propose a proximal iterative nonlinear filter combined with VB, called PEKF-VB, which is described and derived in the following.
Firstly, by substituting Equation (10) into Equation (12), we can rewrite the iterative optimization as
Under the Gaussian assumptions for the process noise and the measurement noise, the variational distribution is of the form . Given the prior of the state at time , we can assume . Accordingly, the is
For the first term in Equation (14), the expectation related to and can be approximated linearly using the gradients with respect to (w. r. t.) and . Defining , the gradients of g w. r. t. and are
The expectation at time k is then maximized by gradient ascent in the variables and ; that is,
where and at iteration i are given by
and is the Jacobian matrix:
In other words, the coefficients and are updated by with in each iterative step. The detailed calculations of and are given in Appendix A.
For Gaussian distributions and with the same dimension d, the KL divergence is
where operators and denote the trace and the determinant of a matrix, respectively. By Equations (17)–(21), Equation (13) can be rewritten as,
Then is maximized at a point which can be explicitly calculated. To find them, set the partial derivatives of w.r.t. to be zero, i.e.,
Accordingly, and are seen to be
where . Equations (24) and (25) show that the state estimate and the associated covariance in the iteration are updated by and , respectively. As shown in Figure 1, the complete iteration procedure consists of Equations (18), (19), (24) and (25).
We note that, in principle, the computational cost in Equations (24) and (25) can be slightly reduced by using the Matrix Inversion Lemma [27]. As a result, Equations (24) and (25) are derived as Equations (26) and (27), respectively.
where .
The flow diagram of the proposed PEKF-VB algorithm is shown in Figure 1 and the detailed implementation of PEKF-VB is given in Algorithm 1.
| Algorithm 1 The implementation of the PEKF-VB algorithm |
|
4.3. Remarks
- The VB method approximates the true posterior PDF by choosing from a parameterized variational distribution. In each iteration of the PEKF-VB, the ELBO (9) increases. It follows that the ELBO is a proper criterion for measuring the performance of variational optimization. The ELBO of the proposed nonlinear filter iswhere and denote the dimension of the state and the dimension of the measurement, respectively. The derivation of the ELBO is given in Appendix B.
- Apart from the KL divergence, we can use Calvo and Oller’s distance (COD) as the penalty function in Equation (13); the corresponding filter is denoted by CODEKF. The COD of two distributions and is [28],where n is the dimension of , , are the eigenvalues of with , which is diagonal, and , . We replace the KLD in Equation (13) with Equation (31) as follows.
- Since both PEKF-VB and CODEKF involve iterations within the VB framework to minimize the divergence between the posterior PDF and variational distribution, their complexity is increased by the calculation of the Jacobian in each iteration.
- In PEKF-VB, we use KL divergence to measure the similarity between two distributions. Under Gaussian assumptions for the distributions, a closed-form solution of the variational distribution has been derived. However, the VB framework with the KL divergence can also apply to non-Gaussian distributions. If no closed-form exists, a Monte Carlo method can be used to approximate the divergence. Other measures of dissimilarity between probability distributions, such as the alpha-divergence, the Rényi-divergence and the alpha-beta divergence, can also be used in the VB framework. See [29] and references therein. Unfortunately, in general, no computationally tractable form of the variational distribution can be derived and a Monte Carlo method has to be employed.
5. Numerical Simulations
In this section, we present two nonlinear estimation examples of 2D target tracking and a benchmark nonlinear filtering problem to illustrate the performance of PEKF-VB and CODEKF. We compare them with EKF and UKF. The performance is measured by root-mean-squared error (RMSE) of the estimates and the computational overhead.
Example 1: Range-bearing tracking. In this scenario, the underlying target motion is described by a constant turn (CT) model, with the state vector consists of 2D position and velocity components. As shown in Figure 2a, the target moves with initial state along a circular trajectory, and is observed by a range-bearing sensor. The state transition matrix in Equation (1) and the measurement function in Equation (2) are:
where the turn rate , the covariances of the zero mean Gaussian white noises and are and , respectively, where , and , , and . At each run, the track is initialised using the two-point method [1] with initial error covariance . We let , and . The target moves for 80 scans (periods). 1000 Monte Carlo runs are carried out.
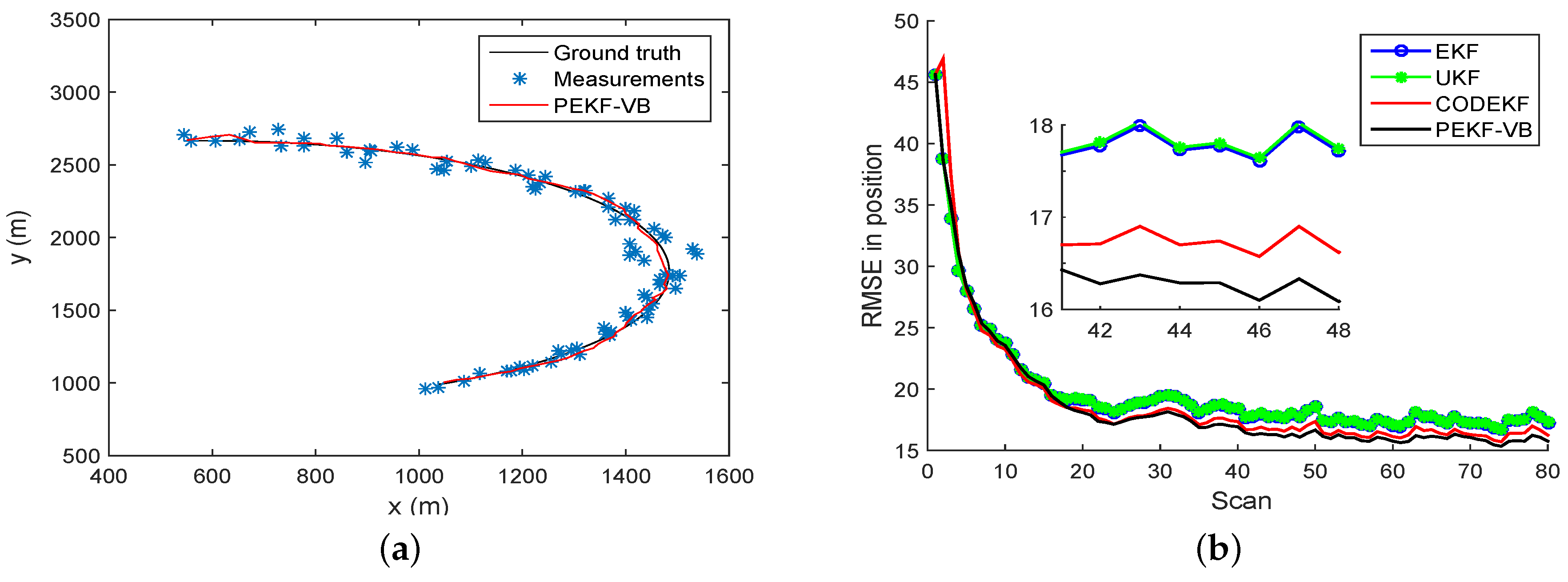
The RMSE plots of EKF, UKF, CODEKF and PEKF-VB are showed in Figure 2b. The black, red, green and blue curves are obtained by the PEKF-VB CODEKF, UKF and EKF, respectively. It is seen that in terms of RMSE performance, PEKF-VB is slightly better than CODEF; both PEKF-VB and CODEF are better than EKF and UKF. Table 1 provides the quantitative comparison of RMSE and execution time of EKE, UKF and CODEKF, PEKF-VB. Figure 3b gives the relationship between iteration index and the running time of PEKF-VB.
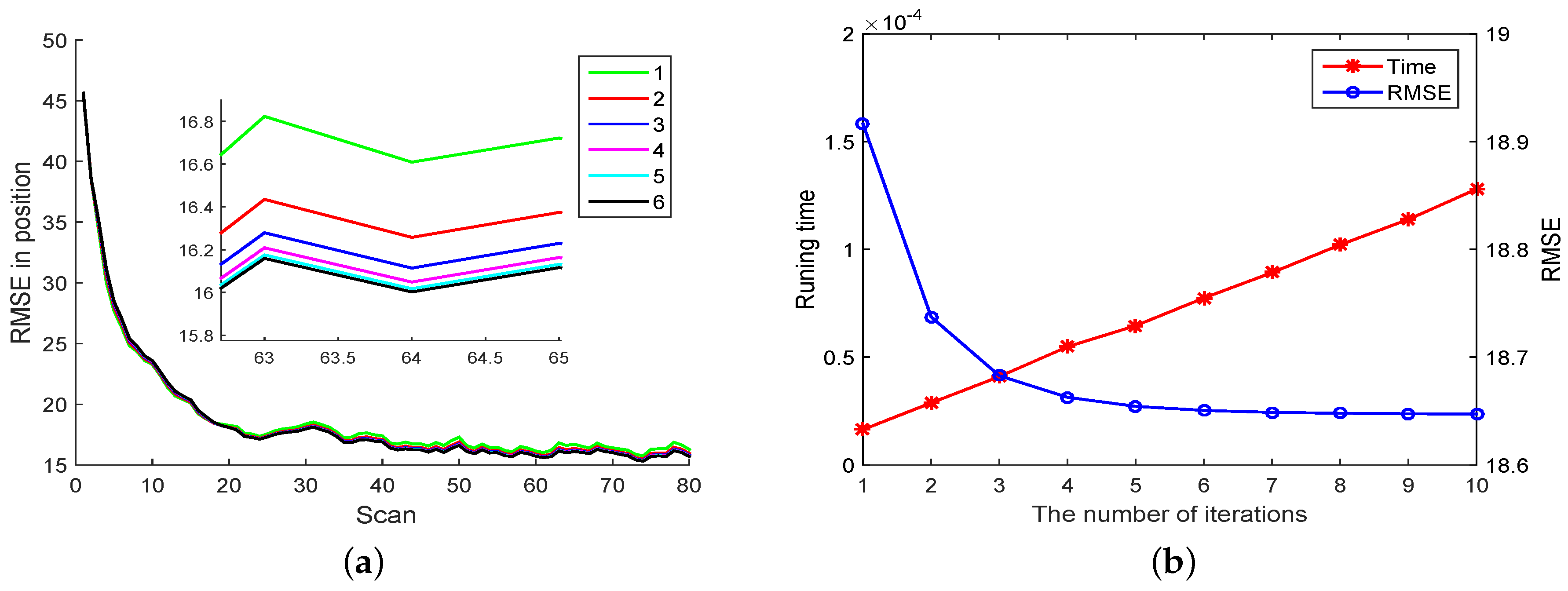
In Figure 3a we compare the RMSE performance of PEKF-VB by varying the numbers of iterations. Notice that the RMSE decreases with the increasing of the number of iterations. Figure 3b gives the computational overhead of PEKF-VB w.r.t the number of iterations. Both results agree with our intuition.
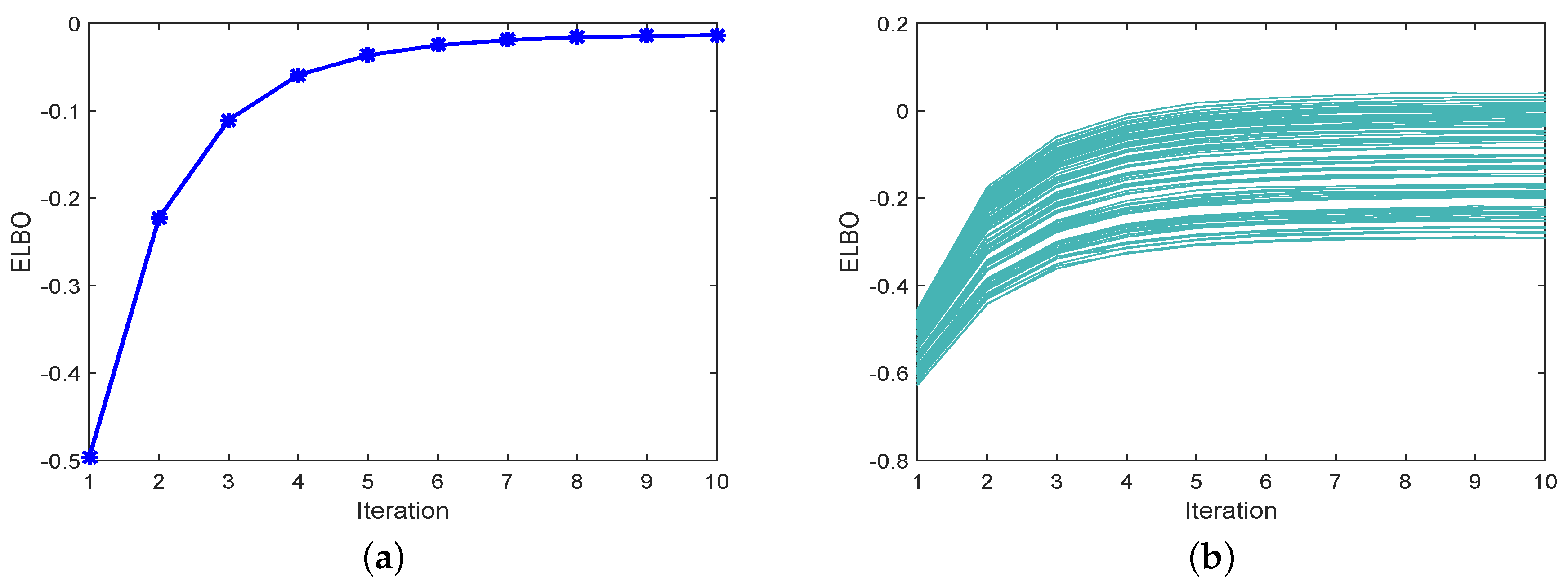
To illustrate the convergence of PEKF-VB, we present the ELBO for different numbers of iterations in Figure 4. Figure 4a illustrates the ELBO at the second scan, and Figure 4b shows the ELBO for all scans. Clearly, the ELBO increases with the number of iterations increases, showing that the iteration procedure in PEKF-VB converges.
Example 2: Bearing-only tracking. In this scenario, a single target tracking using measurements from a single bearing-only sensor is considered. While the sensor (ownership) measurement model is nonlinear to the target state, the sensor has to maneuver relative to the target in order to observe it [30,31]. Let be the state of the target at time k, where and are the position and velocity, respectively. The target, with an initial range of 5 km (relative to the sensor) and initial course of 220° in a clockwise direction (Set the positive axis of y is 0°), is modeled by a constant velocity model in Equation (35).
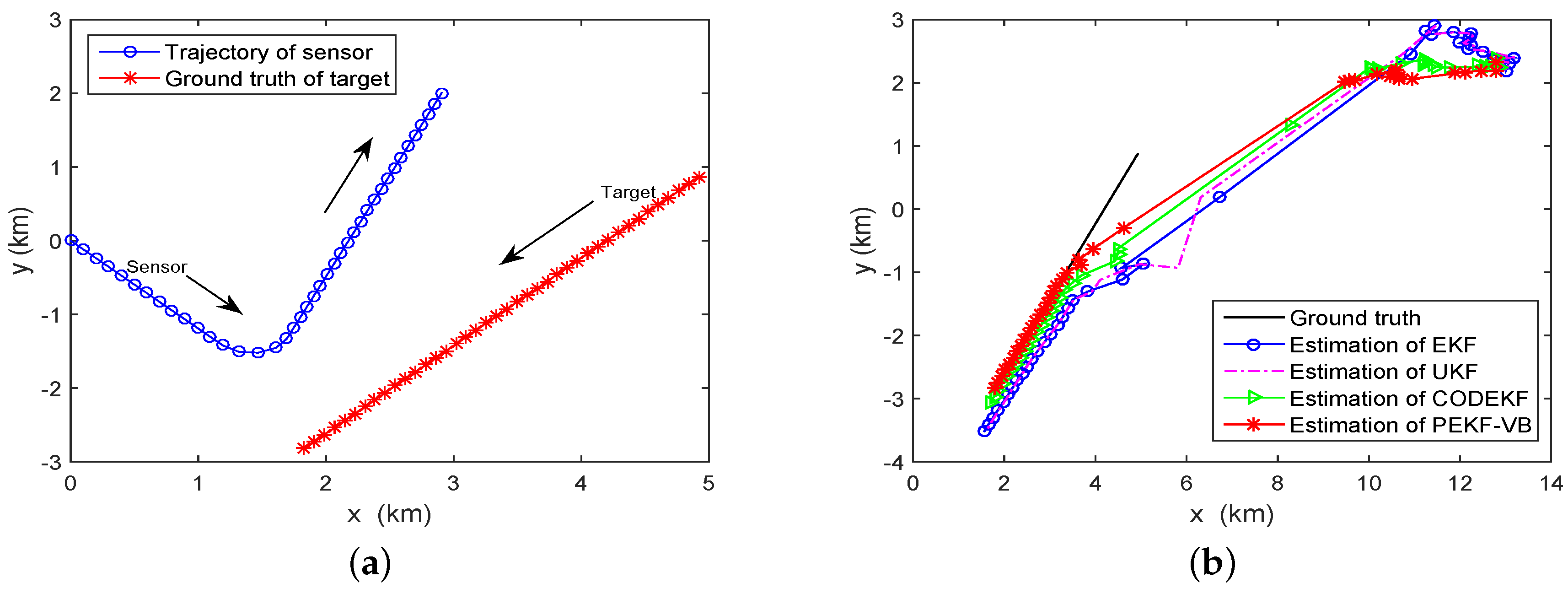
where . The speed of the target is km/min. The sensor starts moving with a fixed speed of km/min and an initial course of 140° in a clockwise direction (Set the positive axis of y is 0°). Please note that for the bearing-only tracking problem, to be able to estimate the range of the target, the sensor has to maneuver. Here we assume the sensor maneuvers from scan 14 to scan 17, and then moves with constant velocity from scan 18 to scan 40. The motion model of the sensor is given by Equation (36), where the turn rate . Both the target and the sensor move for 40 scans and their trajectories are shown in Figure 5a.
The measurement function of the bearing-only sensor is,
where and are the position of the target in Cartesian coordinate system, and are the position of the sensor. The standard deviation of measurement noise is 1°. The initial position of the target is randomly sampled at range with covariance
where
where , and . We let . Figure 5b shows the estimated target trajectories obtained by the EKF, UKF, CODEKF and PEKF-VB for a single run.
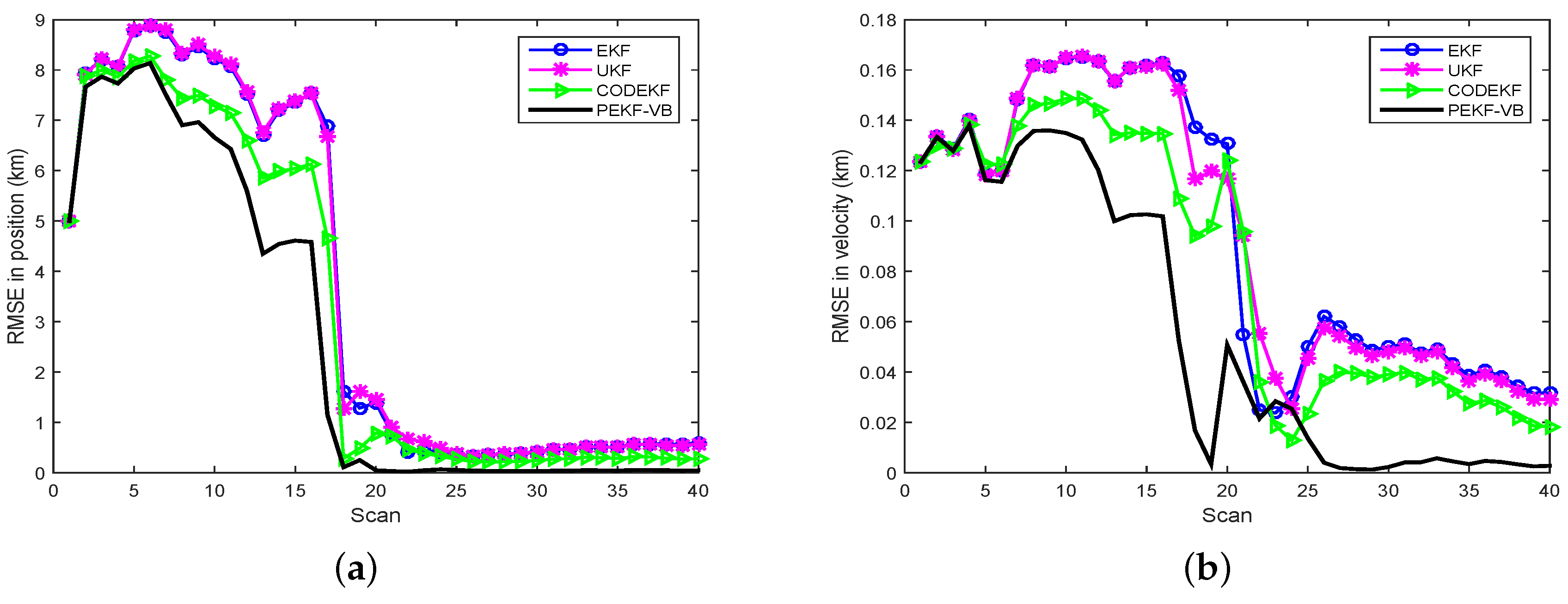
Based on 1000 Monte Carlo simulations, the RMSE comparison of EKF, UKF, CODEKF and PEKF-VB is illustrated in Figure 6, where the number of iterations for PEKF-VB is 5.
- As we expected, with a fixed sensor trajectory, PEKF-VB has the best target observability from sensor measurements and leads to a better RMSE performance than EKF and UKF. Under the VB framework, the variational distribution approaches the real posterior PDF through the iteration of the proximal filter.
- The RMSE performance of CODEKF is also better than those of EKF and UKF because, for CODEKF, the Jacobian matrix of Equation (37) in each iteration is updated to minimize the COD. However, the RMSE performance of CODEKF is slightly worse than that of PEKF-VB.
- In the first few scans, the performance of the four filters are comparable. This is because, in this bearing-only tracking problem, the accumulative measurements in these scans do not provide enough information to the four filters. The performance of CODEKF and of PEKF-VB suffers when measurement data is very limited. As more measurements accumulate both CODEKF and PEFK-VB extract more information via the iteration process, resulting in superior performance.
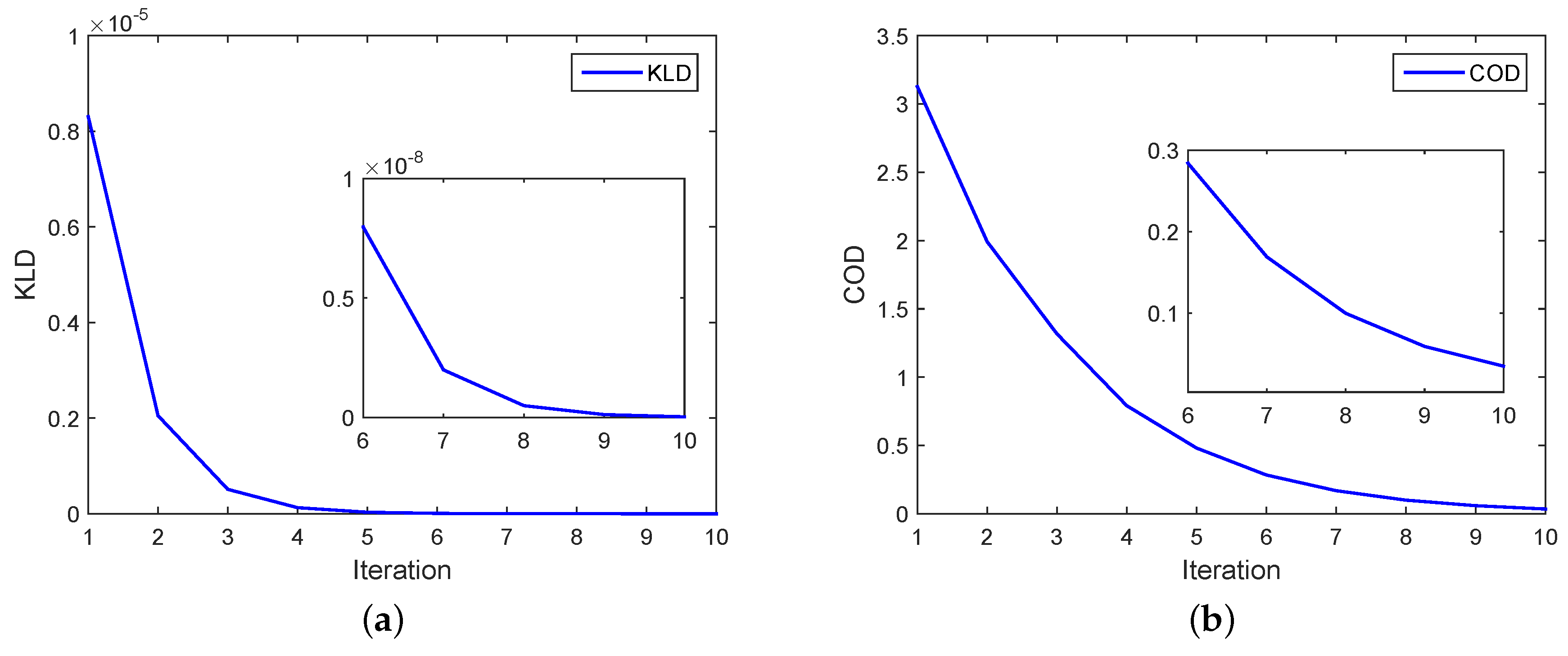
Figure 7 shows the metric values versus the number of iterations for PEKF-VB and CODEKF. The KLD curve is close to zero after the fifth iteration. The enlarged plots marked from the sixth to the tenth iteration shows that PEKF-VB converge faster than CODEKF.
Example 3: A Strongly nonlinear filtering problem. For further verifying our proposed method, we run EKF, UKF, CODEDK and PEKF-VB on the benchmark nonlinear problem in [32,33,34]
where and are zero mean Gaussian noise with variances and , respectively. We let , and scan period . The simulation results are given in Figure 8, from which we can see that CODEKF and PEKF-VB have very similar results and outperform EKF and UKF. This is because that local linearization adopted by EKF-based filter are not a sufficient description of the nonlinear nature of this example [34], while the VB iteration can make use of measurement information as much as possible.
6. Conclusions
We have developed a proximal iterative nonlinear filter, in which the expectation of the posterior PDF is approximated by a parameterised variational distribution that is iteratively optimized in the VB framework. A weighted KL divergence is adopted as a proximal term in the iteration to ensure the convergence can be achieved with a tight bound. The simulation results show that the proposed algorithm is better than several existing algorithms in terms of estimation accuracy at the cost of increased computational burden.
Author Contributions
Y.H. performed this research and Q.P. is the advisor. Conceptualization, H.L.; methodology, Y.M., X.W., H.L.; software, Y.H. and X.W.; writing-original draft preparation, Y.H.; writing-review and editing, Z.W., B.M.; supervision, H.L., Z.W., Q.P.; funding acquisition, Q.P.
Funding
This work was supported by Excellent Chinese and Foreign Youth Exchange Programme of China Association for Science and Technology (No. 2017CASTQNJL046) and National Natural Science Foundation of China (No. 61790552, 61501378, 61503305, 61873211).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivations of and
Since the system is Gaussian, the likelihood function is
The parameters in Equation (18) and in Equation (19) are derived according to Equation (A2) and Equation (A3), respectively.
By Bonnet’s theorem [35], the gradient of the expectation of under a Gaussian distribution w.r.t. the mean is the expectation of the gradient of
It follows that can be written
where the Jacobian matrix .
According to Price’s theorem [36], the gradient of the expectation of under a Gaussian distribution w.r.t. the covariance C is the expectation of the Hessian of :
Similarly,
Appendix B. Derivation of ELBO
Since both system noise and measurement noise are Gaussian, the likelihood function , the PDF and the PDF below are Gaussian
Assume that the state transition matrix and the measurement matrix are obtained by linearization, and can be written as,
where and .
Assume that the state estimation is unbiased; that is, , Equation (A10) can be written approximately as
Since estimation is unbiased, the ground truth at time k can be expressed as,
where . The first term in Equation (A8) becomes
The second term in Equation (A8) becomes
The third term in Equation (A8) is
References
- Barshalom, Y.; Li, X.R. Estimation and Tracking: Principles, Techniques, and Software; Artech House: Norhood, MA, USA, 1996. [Google Scholar]
- Van Trees, H.L. Detection, Estimation, and Modulation Theory Part 1; John Wiley & Sons, Inc.: New York City, NY, USA, 2003. [Google Scholar]
- Farina, A.; Ristic, B.; Benvenuti, D. Tracking a ballistic target: Comparison of several nonlinear filters. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 854–867. [Google Scholar] [CrossRef]
- Hu, J.; Wang, Z.; Gao, H.; Stergioulas, L.K. Extended Kalman filtering with stochastic nonlinearities and multiple missing measurements. Automatica 2012, 48, 2007–2015. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Bao, M.; Zhang, X.; Guan, L.; Hu, Y. Generalized iterated Kalman filter and its performance evaluation. IEEE Trans. Signal Process. 2015, 63, 3204–3217. [Google Scholar] [CrossRef]
- García-Fernández, Á.F.; Svensson, L.; Morelande, M.R.; Särkkä, S. Posterior linearization filter: Principles and implementation using sigma points. IEEE Trans. Signal Process. 2015, 63, 5561–5573. [Google Scholar]
- Tronarp, F.; Garcia-Fernandez, F.; Särkkä, S. Iterative filtering and smoothing in non-linear and non-Gaussian systems using conditional moments. IEEE Signal Process. Lett. 2018, 25, 408–412. [Google Scholar] [CrossRef]
- Khan, Z.; Balch, T.; Dellaert, F. MCMC-based particle filtering for tracking a variable number of interacting targets. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1805–1819. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Merwe, R.V.D.; Doucet, A.; Freitas, N.D.; Wan, E. The unscented particle filter. In Proceedings of the International Conference on Neural Information Processing Systems, Denver, CO, USA, 4–6 December 2000; pp. 563–569. [Google Scholar]
- Cappe, O.; Godsill, S.J.; Moulines, E. An overview of existing methods and recent advances in sequential Monte Carlo. Proc. IEEE 2007, 95, 899–924. [Google Scholar] [CrossRef]
- Julier, S.; Uhlmann, J.; Durrantwhyte, H.F. A new method for nonlinear transformation of means and covariances in filters and estimates. IEEE Trans. Autom. Control 2000, 45, 477–482. [Google Scholar] [CrossRef]
- Gustafsson, F.; Hendeby, G. Some relations between extended and unscented Kalman filters. IEEE Trans. Signal Process. 2012, 60, 545–555. [Google Scholar] [CrossRef]
- Arasaratnam, I.; Haykin, S. Cubature Kalman filters. IEEE Trans. Autom. Control 2009, 54, 1254–1269. [Google Scholar] [CrossRef]
- Arasaratnam, I.; Haykin, S.; Hurd, T.R. Cubature Kalman filtering for continuous-discrete systems: Theory and simulations. IEEE Trans. Signal Process. 2010, 58, 4977–4993. [Google Scholar] [CrossRef]
- Merwe, R.V.D.; Wan, E.A. Sigma-point Kalman filters for integrated navigation. In Proceedings of the 60th Annual Meeting of the Institute of Navigation, Dayton, OH, USA, 7–9 June 2004; pp. 641–654. [Google Scholar]
- Gultekin, S.; Paisley, J. Nonlinear Kalman filtering with divergence minimization. IEEE Trans. Signal Process. 2017, 65, 6319–6331. [Google Scholar] [CrossRef]
- Beal, M.J. Variational Algorithms for Approximate Bayesian Inference. Ph.D. Thesis, Cambridge University, Cambridge, UK, 2003. [Google Scholar]
- Khan, M.E.; Baqué, P.; Fleuret, F.; Fua, P. Kullback-Leibler proximal variational inference. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 3402–3410. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 1–32. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Pecognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Salimans, T.; Kingma, D.; Welling, M. Markov chain Monte Carlo and variational inference: Bridging the gap. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1218–1226. [Google Scholar]
- Mnih, A.; Rezende, D. Variational inference for Monte Carlo objectives. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 2188–2196. [Google Scholar]
- Sain, R.; Mittal, V.; Gupta, V. A comprehensive review on recent advances in variational Bayesian inference. In Proceedings of the International Conference on Advances in Computer Engineering and Applications, Ghaziabad, India, 19–20 March 2015; pp. 488–492. [Google Scholar]
- Tseng, P. An analysis of the EM algorithm and entropy-like proximal point methods. Math. Oper. Res. 2004, 29, 27–44. [Google Scholar] [CrossRef]
- Chrétien, S.; Hero, A.O. Kullback proximal algorithms for maximum-likelihood estimation. IEEE Trans. Inf. Theory 2000, 46, 1800–1810. [Google Scholar] [CrossRef]
- Khan, M.E.; Babanezhad, R.; Lin, W.; Schmidt, M.; Sugiyama, M. Convergence of proximal-gradient stochastic variational inference under non-decreasing step-size sequence. J. Comp. Neurol. 2015, 319, 359–386. [Google Scholar]
- Petersen, K.B.; Pedersen, M.S. The Matrix Cookbook; Technical University of Denmark: Denmark, Copenhagen, 2012. [Google Scholar]
- Calvo, M.; Oller, J.M. A distance between multivariate normal distributions based in an embedding into the Siegel group. J. Multivar. Anal. 1990, 35, 223–242. [Google Scholar] [CrossRef]
- Regli, J.B.; Silva, R. Alpha-Beta Divergence For Variational Inference. arXiv, 2018; arXiv:1805.01045. [Google Scholar]
- Arulampalam, M.S.; Ristic, B.; Gordon, N.; Mansell, T. Bearings-only tracking of manoeuvring targets using particle filters. EURASIP J. Adv. Signal Process. 2004, 2004, 1–15. [Google Scholar] [CrossRef]
- Wang, X.; Morelande, M.; Moran, B. Target motion analysis using single sensor bearings-only measurements. In Proceedings of the International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 2094–2099. [Google Scholar]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proc. F-Radar Signal Process. 1993, 140, 107–113. [Google Scholar] [CrossRef]
- Gustafsson, F. Particle filter theory and practice with positioning applications. IEEE Trans. Aerosp. Electron. Syst. Mag. 2010, 25, 53–82. [Google Scholar] [CrossRef] [Green Version]
- Arulampalam, S.; Maskell, S.; Gordon, N.; Tim, C. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the Machine Learning Research, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Price, R. A useful theorem for nonlinear devices having Gaussian inputs. IEEE Trans. Inf. Theory 1958, 4, 69–72. [Google Scholar] [CrossRef]
Figure 1.
The flow diagram of the proposed PEKF-VB algorithm.

Figure 2.
Tracking with a CT model (a) Trajectory, measurements and estimation (b) RMSE obtained by EKF, UKF, CODEKF and PEKF-VB.
Figure 2.
Tracking with a CT model (a) Trajectory, measurements and estimation (b) RMSE obtained by EKF, UKF, CODEKF and PEKF-VB.

Figure 3.
RMSE and running time of PEKF-VB (a) RMSE with different number of iterations (b) The relationship between iteration and mean RMSE, running time.
Figure 3.
RMSE and running time of PEKF-VB (a) RMSE with different number of iterations (b) The relationship between iteration and mean RMSE, running time.

Figure 4.
The curve in (a) is the ELBO of the second scan. The curves in (b) are the ELBO of all scans.
Figure 4.
The curve in (a) is the ELBO of the second scan. The curves in (b) are the ELBO of all scans.

Figure 5.
Bearing-only tracking. (a) Tracking scenario (b) Estimation obtained by EKF, UKF, CODEKF and PEKF-VB.
Figure 5.
Bearing-only tracking. (a) Tracking scenario (b) Estimation obtained by EKF, UKF, CODEKF and PEKF-VB.

Figure 6.
RMSE comparison of EKF, UKF, CODEKF and PEKF-VB in bearing-only tracking. (a) RMSE in position (b) RMSE in velocity.
Figure 6.
RMSE comparison of EKF, UKF, CODEKF and PEKF-VB in bearing-only tracking. (a) RMSE in position (b) RMSE in velocity.

Figure 7.
Value of metrics versus the number of iterations for PEKF-VB and CODEKF. (a) KL divergence in PEKF-VB, (b) COD in CODEKF.
Figure 7.
Value of metrics versus the number of iterations for PEKF-VB and CODEKF. (a) KL divergence in PEKF-VB, (b) COD in CODEKF.

Figure 8.
Comparison of EKF, UKF, CODEKF and PEKF-VB (a) Filtering results (b) RMSE.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The quantitative comparison of the mean RMSE (from 20 to 80 scan) and the running time.
| Algorithm | EKF | UKF | CODEKF | PEKF-VB |
|---|---|---|---|---|
| Time ratio | 1 | 3.64 | 3.96 | 6.76 |
| Mean RMSE | 17.8129 | 17.8455 | 16.7758 | 16.3958 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hu, Y.; Wang, X.; Lan, H.; Wang, Z.; Moran, B.; Pan, Q. An Iterative Nonlinear Filter Using Variational Bayesian Optimization. Sensors 2018, 18, 4222. https://doi.org/10.3390/s18124222
AMA Style
Hu Y, Wang X, Lan H, Wang Z, Moran B, Pan Q. An Iterative Nonlinear Filter Using Variational Bayesian Optimization. Sensors. 2018; 18(12):4222. https://doi.org/10.3390/s18124222
Chicago/Turabian StyleHu, Yumei, Xuezhi Wang, Hua Lan, Zengfu Wang, Bill Moran, and Quan Pan. 2018. "An Iterative Nonlinear Filter Using Variational Bayesian Optimization" Sensors 18, no. 12: 4222. https://doi.org/10.3390/s18124222
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.