1. Introduction
Given the beneficial effects of physical activity for health [
1], an accurate assessment of physical activity is important. Therefore, small-body worn high-resolution accelerometers are now routinely used in large-scale surveys such as UK Biobank to objectively assess physical activity [
2]. Methods used to explore these data are still relatively simple, relying on summary data rather than harnessing the full potential of high resolution (up to 100 Hz) data. This is unfortunate as a more refined approach to accelerometer analytics could facilitate the development of personalised interventions tailored to how types of physical activity are clustered. For example, the automatic detection or classification of broad types of physical activity from accelerometer data could provide valuable information about optimal lifestyle and exercise patterns for the prevention of chronic disease, assist with emerging precision medicine development, and the refinement of programmes for specific health needs (e.g., maintaining cardio-metabolic health) [
3,
4,
5,
6].
Supervised machine learning models are frequently used to train an automatic classifier to identify activity type from accelerometer data. Studies to date have either focused on the intensity of the activity [
7] or activity type with combined categories of running/walking and standing/moving [
8]. The models do not always transfer well to new datasets and experience great variability of performance [
9], with performance further reduced when models are applied to free-living datasets [
10,
11]. Therefore, robust cross-validation of models is essential. However, relatively few studies have used more than one dataset to develop and validate these models. Leave-one-out cross-validation [
10] is frequently used with only a few studies using an independent dataset for cross-validation [
7,
8] to confirm generalisability.
In Kerr et al. [
8], a random forest model classified all free-living behaviours with 80% accuracy based on hip accelerometer data. The model was applied to three diverse datasets: these consisted of two female researchers aged under 30, the second of 40 cyclists with a mean age of 36 of which 70% were male, and finally, the third dataset consisted of 36 overweight women with a mean age of 56. Within each dataset, accuracy was evaluated based on leave-one-participant out cross-validation; across datasets, the accuracy was evaluated based on training on an entire dataset and applying that model on each participant from another dataset. Leave-one-out cross-validation and use of an independent dataset for cross-validation were directly compared by Montoye et al. [
7] using two wrist accelerometer datasets collected during simulated free-living conditions. There were inconsistencies between the leave-one-subject out cross-validation and independent dataset cross-validation when evaluating the performance of the machine learning models for the prediction of activity intensity. This implies that the leave-one-out method is insufficient for testing how a model will work with a new population [
7]. This highlights the importance of including free-living data and using an independent dataset for cross-validation when developing and evaluating machine learning models. Furthermore, the Kerr model also relies on time-smoothing (i.e., using information from neighbouring minutes to improve predictions using a Hidden Markov Model in conjunction with random forests), which requires additional computational time.
Whilst results from the cross validation in independent datasets from the random forest model in Montoye [
7] were encouraging (77.3–78.5%) in classifying activities by intensity (sedentary, light, moderate, or vigorous), the study was limited to two datasets consisting of a total of 63 participants with the second dataset showing little variability in age and was based on data collected in a simulated free-living setting within a research laboratory rather than actual free-living data.
Supervised machine learning models are reliant on labelled data being available (i.e., where it is known what a person is doing), which can be both time-consuming and costly to acquire, particularly for free-living data [
10]. An alternative approach is to use unsupervised machine learning models, which infer patterns from an accelerometer dataset without reference to labelled classes. Unsupervised machine learning can provide insights into the underlying structure of data, automatically separate the dataset into clusters of behaviours exhibiting similar movement patterns and facilitate greater understanding of why certain activities are grouped together through cluster analysis [
12]. As with supervised learning, ideally, models should be tested on independent datasets to determine whether the cluster structure is generalisable. However, as there is no need for labelled data to train a model, unsupervised machine learning models can be developed on free-living data meaning that they do not require expensive and time-consuming calibration studies [
9].
Recently, van Kuppevelt et al. [
9] applied an unsupervised approach to classify physical activity intensity from wrist-worn accelerometer data from free-living children. As their aim was to classify activity intensity, not activity type, the input metrics were restricted to five-second averages of resultant acceleration, which was correlated with activity energy expenditure [
13], and accelerometer orientation. Their results were reproducible when trained on a sub-sample from the same dataset and showed face validity in terms of the duration and intensity of states identified in their Markov model and relative to the cut-point approach. However, as the authors acknowledged, due to the lack of a gold standard for the intensity of physical activity that is feasible for large free-living studies, criterion validity could not be tested.
Application of unsupervised approaches to the features from the high-resolution acceleration signal has potential for the classification of activity types. However, in order to understand this approach, it is first necessary to determine whether it works to differentiate known labelled activities and to describe the activity types contained in the clusters generated.
Our overall aim was to evaluate whether it is possible to use an unsupervised machine learning approach to create a portable (i.e., generalisable and reusable) clusters model that can distinguish between broad categories of physical activity that encompass waking hours and can be easily reapplied across different datasets using stored settings. If successful, this method of approach could be used to develop a general model for the analysis of free-living datasets created with accelerometer devices with similar characteristics and worn at the same body-site.
Specifically, we aimed to:
Fit an unsupervised machine learning model based on two combined labelled accelerometer datasets;
Test the fitted model on three independent labelled datasets, one of which is a free-living dataset; and
Assess which activity types were clustered together using the ‘ground truth’ information for these datasets
2. Materials and Methods
Our data were gathered from five studies where accelerometer data were acquired at a sampling frequency of between 80–100 Hz for three axes using the GENEA
TM or GENEActiv
TM devices [
14,
15,
16,
17] (see
Table 1 for details of each sample). Participants in all studies gave their written informed consent. Ethics approval was obtained from the Ethics Committees of the School of Sport and Health Sciences, University of Exeter (Development sample 1 and Independent sample 1) and Loughborough University (Development sample 2 and Independent samples 2 and 3). The GENEA is an acceleration sensor developed by Unilever Discover (Colworth, United Kingdom), while GENEActiv is the commercially available version manufactured and distributed by ActivInsights Ltd. (Kimbolton, Cambridgeshire, UK). Both are triaxial MEMS (micro-electro-mechanical system) acceleration sensors housed in a small lightweight casing; the dynamic range of the GENEA is ±6
g and that of the GENEActiv is ±8
g. The sampling frequency of the GENEA ranges from 10 to 160 Hz and that of the GENEActiv from 10 to 100 Hz. Our goal was to develop a model that was generalisable to monitors worn on either wrist, therefore data from both wrists were combined for testing.
Figure 1 shows the orientation of the axes when worn on the non-dominant wrist with the hand (a) level and (b) hanging vertically.
The orientation angles of the acceleration axes were relative to the horizontal plane and were calculated as described by van Kuppevelt et al. [
9]:
2.1. Development Sample 1 (Laboratory Adult 1)
Each participant completed an ordered series of 10–12 semi-structured activities, see Esliger et al. [
15] for full details. In brief, the activities included lying, standing still, seated computer work, treadmill walking (4 km/h, 5 km/h, 6 km/h), outdoor brisk walk (6 km/h), walking up and downstairs, two household activities (randomly selected for each participant from window washing, shelf stacking and sweeping), one treadmill run (8 km/h, 10 km/h, or 12 km/h), and an optional outdoor run (10 km/h). The lying activity was performed for 10 min, whereas all other activities were performed for around 4.5 min.
2.2. Development Sample 2 (Laboratory Adult 2)
Each participant completed a series of activities, as detailed previously [
14]. Activities included lying (in various positions including flat on back, flat with legs bent, or to the side with legs either bent or straight), sitting (with different foot or leg positions) with and without upper body movement (computer, and mobile phone games), household activities (washing up, cleaning/dusting, or sweeping), and finally, a self-paced corridor walk. All activities/postures were five minutes in duration.
2.3. Independent Sample 1 (Laboratory Child)
Children carried out five activities including lying, seated DVD watching, treadmill walking (4 km/h and 6 km/h) and treadmill running. Lying was performed for ten minutes, with three minutes for the other activities. See Phillips et al. [
16] for details.
2.4. Independent Sample 2 (Laboratory Adult 3)
The activities of the participants included sitting (engaged in various activities including eating, talking, reading the newspaper, and computer activities whilst seated), standing still, light walking, and household (consisting of dusting, sweeping, and washing up) each of five to ten minutes’ duration. See Rowlands et al. [
17] for the full details.
2.5. Independent Sample 3 (Free-Living Adult)
These data were taken from a larger dataset investigating the equivalency of physical activity outputs from a range of accelerometers during free-living [
12]. For the current analysis, data were taken from the GENEActiv worn on the non-dominant wrist and the activPAL (PAL Technologies Ltd., Glasgow, UK) worn concurrently on the thigh for two days of free-living. The activPAL activity types of sedentary, standing, and stepping were used as a criterion to label the GENEActiv data. The data were analysed in two ways: (a) using labelled data to identify the proportion of each activity type within each cluster of the model as per the laboratory samples, but for the activPAL activity types of sedentary, standing, and stepping only (
N = 6); and (b) comparing the total daily time identified in the clusters by the model to the activPAL criterion (
N = 8). For (a), three hours of matched data were selected from the free-living data (between 08:00–11:00 for three participants and between 15:00–18:00 for three others), making a total of 18 h. Three hours was selected to include a range of activities (e.g., self-care, eating, transport, ambulation, work), but also keep files at a manageable size for the labour-intensive job of manually detecting all transitions from the activPAL event file to label each corresponding GENEActiv file. For (b), twenty-four hours of matched data were selected from the free-living data (between 00:00–24:00 for eight participants), making a total of 192 h. This was to give context to the results as it reflects the way the model would likely be applied with free-living data.
2.6. Activity Labels
Across the laboratory datasets, ground truth information was available for nine types of physical activity (lying, seated, standing, household, indoor walking, outdoor brisk walking, treadmill walking, stairs, running). For the free-living dataset, ground truth information for sedentary, standing, and stepping was estimated from the activPAL as detailed above. As described, we applied our model to both a labelled sample of 3 h data for six participants and 24 h data for eight participants.
2.7. Pre-Processing of the Accelerometer Signal
To fit the unsupervised machine learning model to the data and evaluate the purity of the clusters relative to the ground truth, we began by annotating our four laboratory time series data with activity labels and discarded thirty seconds of data from the beginning and before the end of each labelled activity to eliminate the transitional data. For the free-living data, the activPAL event file was used to identify transitions between sedentary, standing, and stepping. We utilised those time ranges within Python (Python Software Foundation,
https://www.python.org/), [
18] using a purpose-built script, to select a 24 h time-range and generate frequency and time domain features. These initial features were based on popular choices from other studies (see
Supplementary Tables S1 and S2). Acceleration features were extracted from all five datasets using ten second sliding windows, with no overlap. Two frequency domain features were extracted. These were the dominant frequency and power of dominant frequency based on a single-dimensional signal magnitude vector (
) also referred to as the resultant, or ENMO (Euclidean Norm Minus One) which is
[
11]. Negative ENMO values were flattened to zero. Further time domain features were extracted including the max, min, mean, median, 10th percentile, 75th percentile, 90th percentile, standard deviation, and variance for each axis. In addition, mean, max, and median for ENMO and the min, max, mean, and median for the orientation angles for each of the three acceleration sensors relative to the horizontal plane were extracted. When inactive (i.e., the only acceleration measured is due to gravity), these angles are an estimate of wrist orientation. We used the absolute value of the correlation coefficient between the feature and the class vector (i.e., type of physical activity) to select the most relevant features and considered coefficients less than 0.12 as weak. This approach selected 24 features (r = 0.12–0.53), presented in
Table 2.
Our purpose was an exploratory analysis and we aimed to ascertain which features met the threshold for clustering in the development dataset, which, by definition, was comprised of activity types across the intensity range and representative of daily living [
14,
15]. Pre-processing also included the MinMax normalisation.
2.8. Unsupervised Machine Learning Using k-Means
K-means [
19] has been a popular clustering method for more than sixty years, remaining one of the key machine learning models that is included in all major statistical packages (e.g., WEKA, R, SPSS, STATA). In each instance, the number of clusters (K) is either known, presumed or indicated beforehand (a number of techniques exist including the Elbow Method [
20], Silhouette Score [
21], and Calinski-Harabasz [
22] to assess an optimal number for K) [
23]. Here, we used the Nguyen et al. [
24] approach of over-clustering where the number of clusters (ten) was greater than the number of actual or expected classes (nine, i.e., the number of activity types in the development dataset). The centroids of each cluster were initialised randomly, or as here with K++ [
25].
K-means alternates two steps until convergence. The first step is the association of each data point
with the closest centroid
. Let us denote the set of points in cluster
as
:
The second step recalculates the centroids of each cluster to minimise the sum of squared Euclidean distances from the data points of this cluster to the cluster centroid
where
is the number of points in the cluster. This two-step algorithm minimises the sum of squared Euclidean distances from each data point to the nearest centroid.
The two development datasets were used to fit the model. Ground truth information was available for nine types of physical activity. The trained clustering model (including K, the hyper-parameter settings, and the centroids for each cluster) was stored using the Python pickle module and reapplied blind on the two independent laboratory datasets and the free-living accelerometer dataset. Use of the same model is essential. If the same k-means algorithm is applied to successive datasets, it will calculate different clusters for each database. Such clusters can better describe each individual database but are useless for generalisation purposes. All machine learning algorithms were carried out using the sklearn library [
18] in Python.
2.9. Evaluation of the Model
The clustering results from the development datasets were examined to determine how the nine activities were spread across the ten clusters. Based on the clustering observed, to evaluate the models, we collapsed the ten clusters into broad activity type categories with similar properties. These activity type categories were subsequently used to evaluate the clusters relative to the ground truth activity labels and by measuring the combined average cluster purity and average event purity (
ACEP). The performance of the clustering model was evaluated using a purity matrix to show the proportion of the total instances of each physical activity class within each cluster. This approach has been used in other accelerometer clustering papers [
26]. Performance was assessed for the two development datasets combined with each of the independent datasets. We also evaluated cluster purity (
ACP), a measure of the extent to which the categories contain a single dominant class [
27]; average event purity (
AEP), the proportion of a class found within a cluster relative to that found in other clusters; and combined average cluster purity (
ACEP). Let us denote
as the number of events
in cluster
(number of points of class
in cluster
),
is the total number of different events (classes),
is the number of clusters,
is the number of elements in cluster
,
is the number of instances of event (class)
, and
is the total number of instances (points in database).
It should be noted that purity has some limitations when working with imbalanced data where the relative sizes of the classes are different, whereas here, there were multiple classes (e.g., lying down and seated work) both included in a category (e.g., sedentary). However, ACP and AEP still provide a useful rough guide to the extent to which a given category of PA constitutes the bulk of the cluster. Purity was not calculated for the free-living dataset as the standing and stepping ground truth categories could not be aligned with mutually exclusive clusters (i.e., the clusters did not distinguish between standing and slow stepping) and the ground truth did not distinguish between slow and vigorous stepping.
4. Discussion
The aim of the unsupervised approach is not to identify pre-determined categories (e.g., of activity types or intensity), but to identify patterns in the data that clustered together [
9]. To facilitate interpretation, we identified which types of activities our model tended to discriminate between. A particular strength of k-means as an unsupervised machine learning model is its portability (i.e., the centroid of each cluster can be stored and reapplied to multiple accelerometer datasets). Theoretically, this enables analogous clusters to be fitted from multiple datasets facilitating comparisons between studies and/or populations.
Application of the unsupervised machine learning model to the relatively simple labelled wrist accelerometer development dataset facilitated discrimination between clusters that reflected activity types. When the stored model was applied to diverse laboratory independent datasets that were also relatively simple, the consistency of activity types within clusters dropped, but remained above 70% for sedentary clusters and above 85% for both the running (children) and ambulatory clusters. Perhaps most notably, while standing mainly fell into the mixed cluster in the development datasets, it tended to bleed into the slow ambulatory clusters in independent dataset 2. Household activities also tended to bleed across clusters. When applied to a small free-living dataset labelled only as sedentary/standing/stepping, the consistency of activity types was similar for sedentary clusters and all ambulatory clusters, although the standing activity again bled across clusters. Total daily time spent in sedentary clusters was lower and time spent brisk walking/running was higher relative to the sedentary and stepping time from the thigh-worn ActivPAL, both with relatively wide limits of agreement. The purpose of these comparisons is to give some context as to the content of the clusters identified by the model; the discrepancies are not surprising given the differences in monitor wear-site and analytical approach and is consistent with other comparisons of methods (e.g., [
28]). Notably, the characteristics of the features of the acceleration signal used in the model were similar within each cluster across laboratory-based samples and free-living participants, across diverse populations (e.g., children and adults), and irrespective of whether activity typical of a cluster (e.g., running in the independent adult laboratory sample), were missing. This suggests that application of a stored model can identify clusters that represent similar activities and/or movement patterns, at least in terms of the features used within the model, in children and adults and in laboratory and free-living data. It is important to determine if these clusters are associated with, or predictive of, health outcomes.
The acceleration features that were selected were largely related to accelerometer orientation and the standard deviation of accelerations. This may have helped the suitability of the model across diverse datasets as these features are likely less impacted by body size than the resultant acceleration, which can differ for a given activity by size (e.g., between children and adults) [
29]). The heaviest loading was on features related to the
Z-axis and on the standard deviation of the accelerometer orientation, likely reflecting the inclusion of data from both wrists in the development of our wrist agnostic model. Inclusion of data from both wrists will have confounded magnitudes of acceleration and, to a lesser extent, the orientation of the vertical axis of acceleration (Y) and the anterior–posterior acceleration (X, e.g., arm swing), but not the
Z-axis (going into the wrist). This is a limitation in the features available for model development, but it also extends the generalisability of the model and thus external validity. The model should be robust to differences in wear including not only on either wrist, but potentially irrespective of the positioning on the wrist (e.g., wear with the face of the monitor on the inside or outside of the arm).
The model was created somewhat artificially using a laboratory dataset. This is a limitation as behaviours performed in a laboratory setting differ from those performed in a free-living setting [
13]). This was deliberate as a ‘first step’ to establish whether an unsupervised approach provides meaningful clusters when applied to accelerometer data. As the clusters produced in this controlled scenario appear meaningful, this provides a strong foundation for applying the approach developed to free-living data. By using laboratory datasets, we were able to (a) start with a simpler clustering task, and (b) assess the robustness of the model on multiple datasets that differed in the population considered, protocol, activities undertaken, laboratory where the study was undertaken, and version of the accelerometer used. Very few studies have undertaken cross-validation using multiple datasets [
7,
8,
16]. That the types of activities contained in the sedentary clusters and the ambulatory clusters in the laboratory datasets broadly agreed with the stepping and standing assessed by the activPAL in the pilot free-living dataset is encouraging. This suggests that meaningful clusters that are comparable between datasets could be obtained from applying this type of approach to free-living accelerometer data.
The magnitude of acceleration alone is a useful metric for classifying moderate and vigorous activity, either through the cut-point [
29] or other more data-driven approaches [
30]. However, it is not useful for differentiating between types of sedentary and lighter activities, which comprise the majority of the day [
28]. The identification of multiple sedentary clusters, in both this study and in van Kuppevelt’s [
9] earlier study, that differ predominantly in the acceleration orientation features suggest that the primary advantages of this approach may be the classification of types of sedentary and light behaviour. The results of this study build on our previous research showing how, when a person is inactive, the acceleration orientation metrics from wrist-worn accelerometers can be exploited to determine wrist position, estimate posture, and visualise different types of sedentary behaviours [
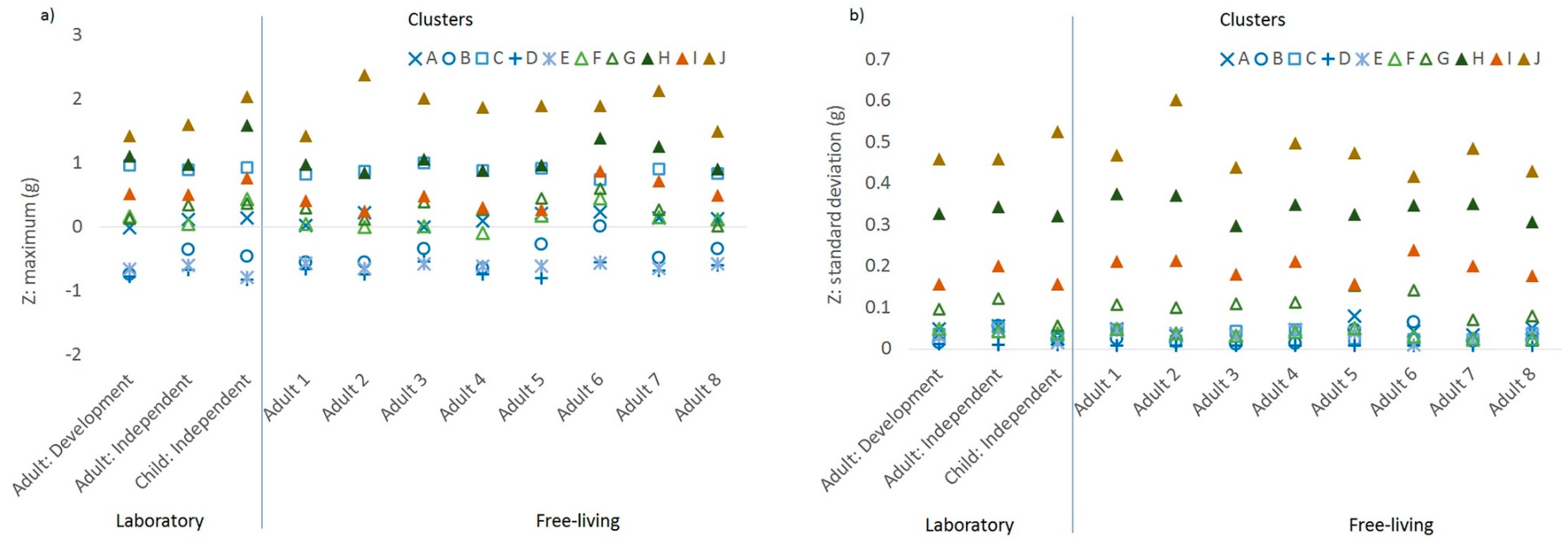
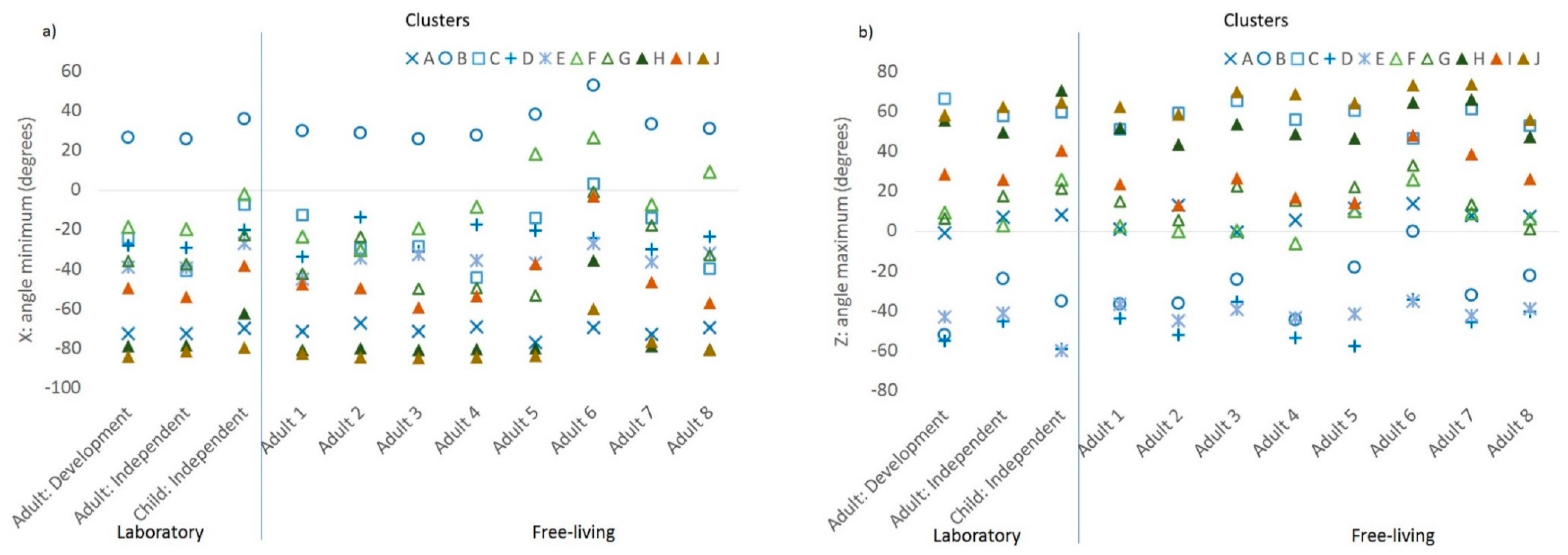
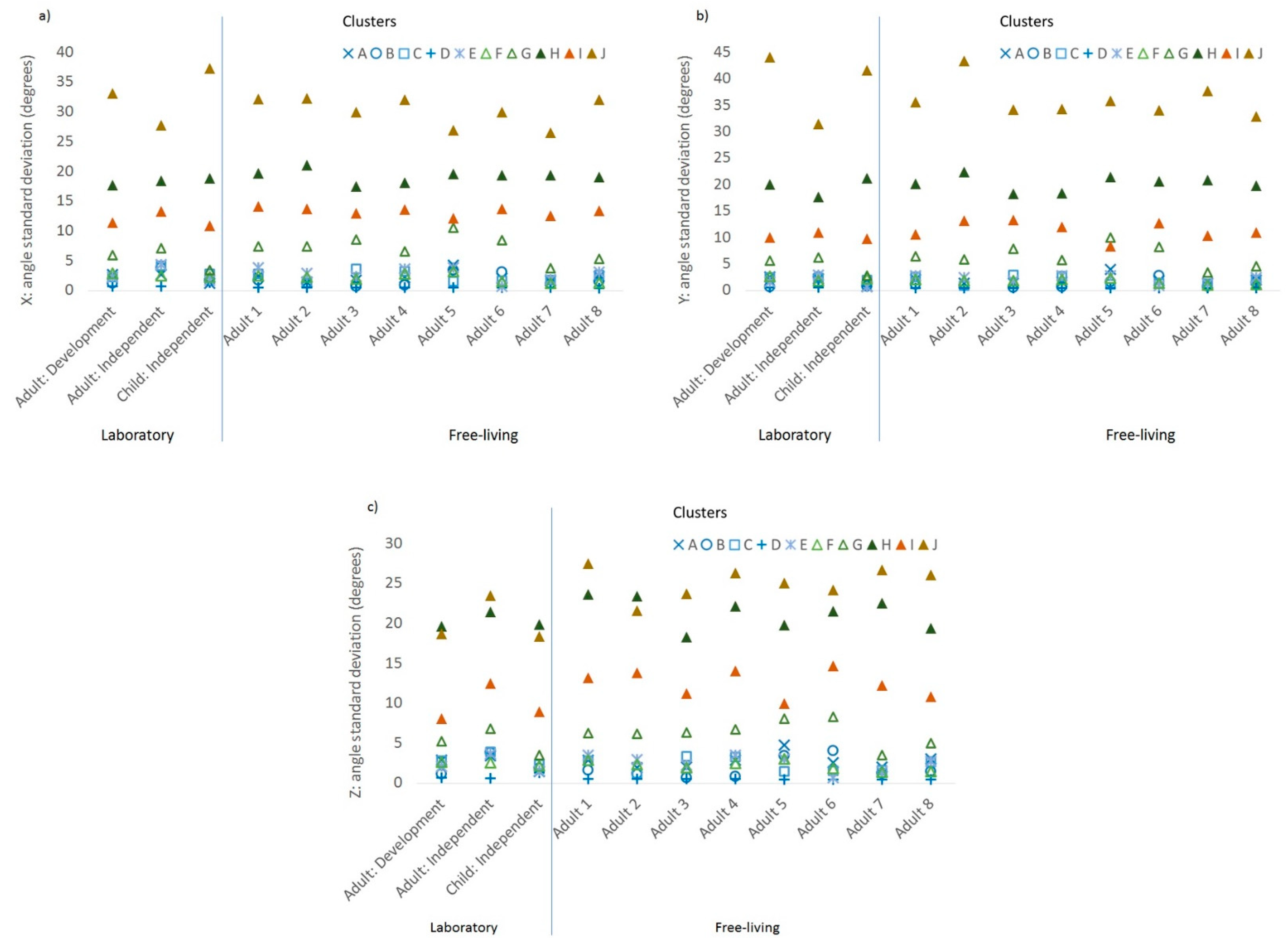
28]. For example, cluster C was characterised by the palm tending to face up (as shown by positive maximum Z acceleration), cluster A with the palm neither up or down (0 maximum Z acceleration), and the remaining clusters with the palm facing more downwards (negative maximum Z acceleration). The elevation of the wrist when the palm was vertical was consistently positive in cluster B, while the elevation of the wrist when the palm was facing down was consistently positive in cluster C, negative in clusters D–E, and zero in cluster A. Obtaining ground truth information from the detailed type of sedentary behaviour would allow this to be further explored. Meanwhile, the standard deviations of the accelerometer orientation metrics were important features for discriminating between activity and inactivity, particularly between ambulatory activities and sedentary behaviour. These features reflect variability in the elevation of the wrist and are agonistic to the wrist of wear.
This is an exploratory study and there are weaknesses and areas for improvement. For example, it is desirable to minimise the bleeding of non-ambulatory activities such as standing and household activities into the ambulatory clusters. K-means has a bias towards forming spherically shaped clusters and necessitates a choice of K amongst other drawbacks [
31]. Given comparatively poor internal measure cluster validation scores (Silhouette Score 0.22–25), which indicate a lower level of cohesiveness and separation between clusters, there is potential for further work on feature selection and engineering to maximise the separation between accelerometer physical activity clusters, perhaps experimenting with additional frequency domain features (e.g., zero-crossings, second dominant frequency, or the ratio between dominant frequencies for current and previous windows) to try to increase cluster separation and cohesiveness. Furthermore, our features were generated on non-overlapping windows; another approach could be to incorporate the stage before and the stage after (i.e., overlapping windows) into feature engineering to see if this facilitated better discrimination of activity types that cluster together. Finally, while the results herein suggest portability, all datasets used the GENEA or the GENEActiv with a sampling frequency of 80–100 Hz. Thus, we have only considered portability between datasets using the same device and not between devices. It is possible that the model may not be portable to datasets using the same device with a lower sampling frequency and/or using a different device. There is evidence for equivalence in outputs between research-grade accelerometer brands [
12,
17], particularly for frequency domain and orientation features [
32,
33,
34], which suggest that the model may be portable between research-grade devices, but this needs to be confirmed in future research.

 ,
, 




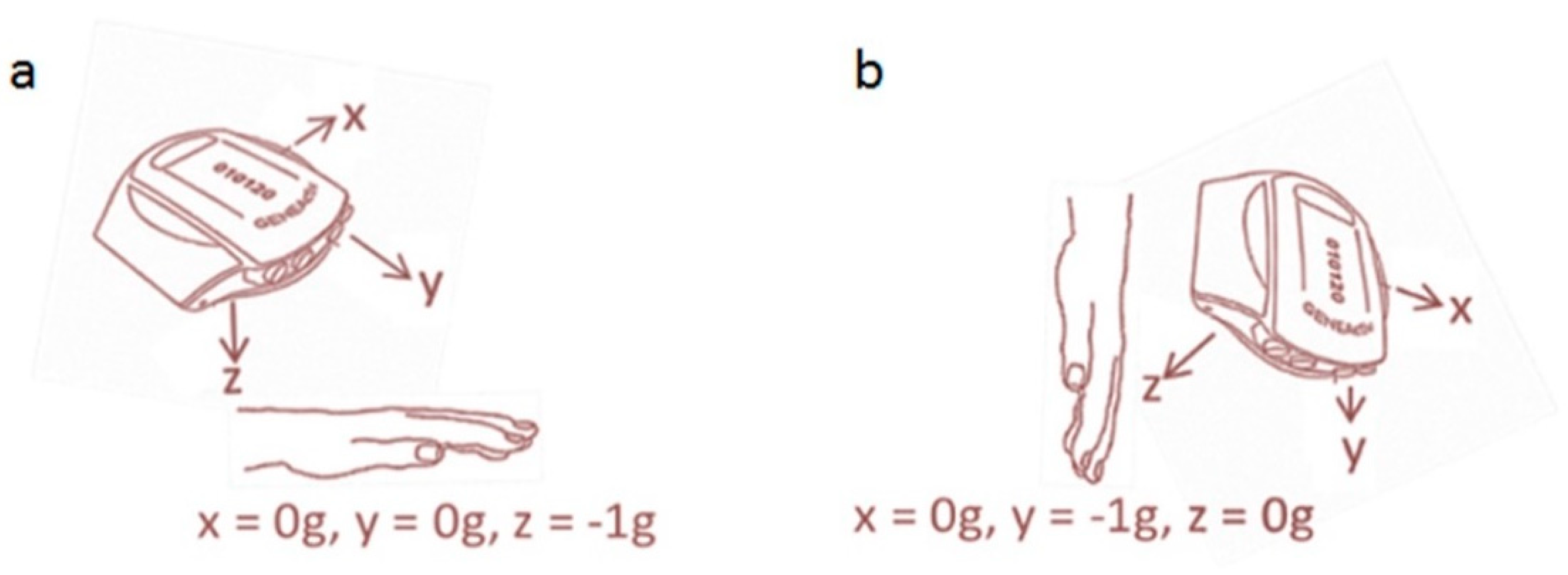{kind=link}
{kind=link}
{kind=link}
{kind=link}