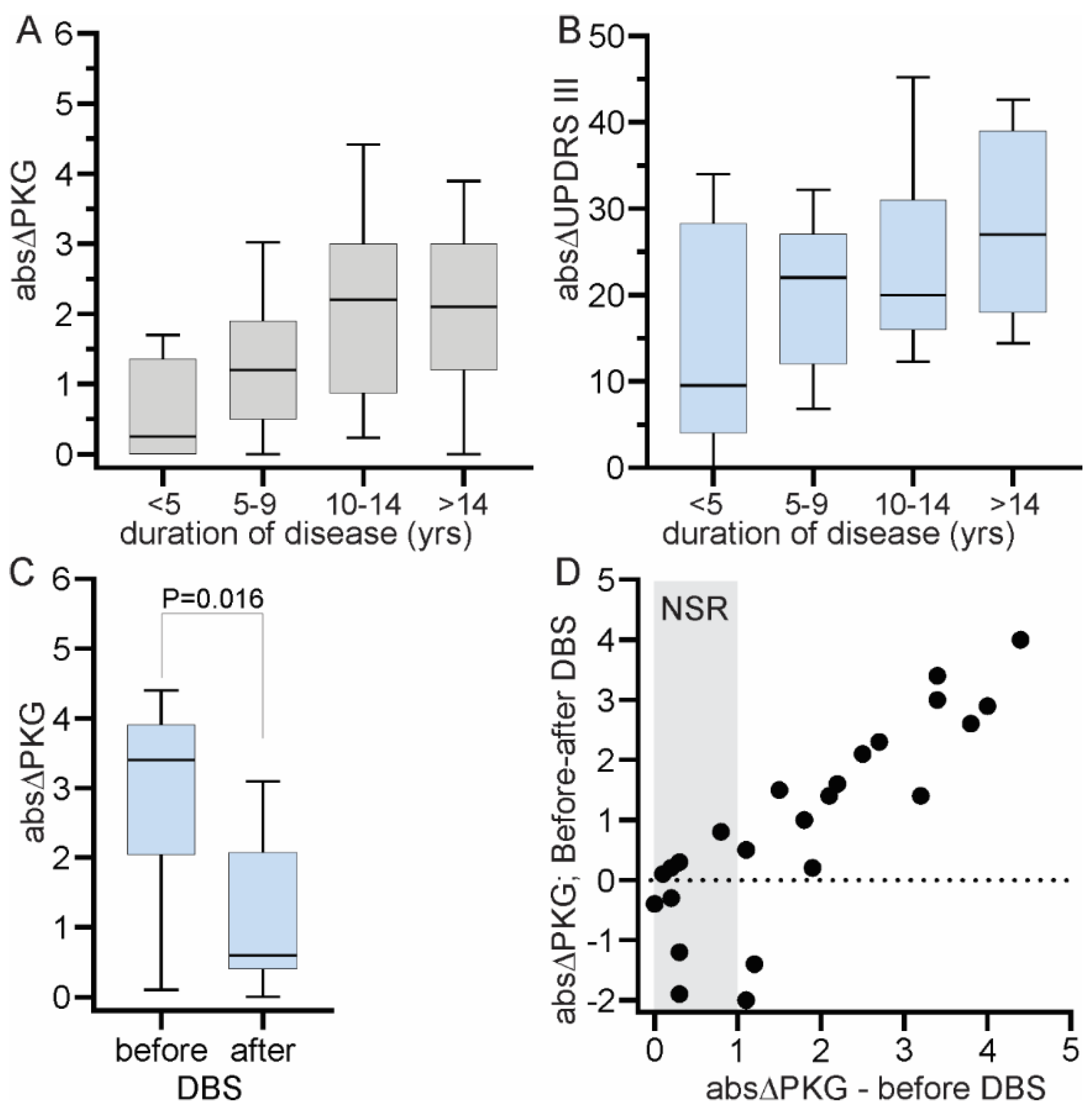
The data used in this study was collected from 199 people with PD (PwP) who attended one of the three clinics (St George’s, Leiden University Medical Center/Haga Teaching Hospital or the University of Kansas Medical Center) for an LDCT as part of routine clinical care. In the case of St George’s and Leiden/The Hague, the data was collected and collated as part of other studies approved by institutional ethics with approval to use the deidentified data in related studies. In Kansas, the data was collected and collated as part of routine clinical care with institutional approval to use the deidentified data. As well, data from 191 people without PD and aged >60 was used under approval provided by St Vincent’s Hospital Melbourne Human Research & Ethics Committee. PKGs were also available from 24 subjects who underwent deep brain stimulation (DBS). PKGs were performed prior to DBS and months after DBS. This study was carried out in accordance with the guidelines issued by the National Health and Medical Research Council of Australia for Ethical Conduct in Human Research (2007, and updated May 2015). Clinical characteristics of participating subjects and inclusion criteria into the analyses are discussed below.
2.1. Patient Cohort
Data from the 199 PwP who underwent a LDCT as part of routine clinical care at these 3 clinics were reviewed. Subjects were excluded if; (a) a PKG logger had not been worn at or near the time of the LDCT (median 6 days and 75th percentile 22 days); (b) it was documented that PD medications were consumed prior to the first PKG medication reminder; (c) PD medications were used at the time of the first dose whose pharmacological profile would mask or confound the usual response to levodopa (apomorphine, levodopa in intestinal gel formulation, levodopa in extended release capsules (Rytary) but not D2 agonists or entacapone); (d) there was no reminder set on the PKG at or around the time of awakening; (e) the first dose occurred before 5:00 am. Of the original 199, 48 were excluded for one or more of the above reasons. The clinical features of the remaining 151 PwP are shown in
Table 1.
Controls were 191 subjects aged 60 years and over, without a known neurological disorder and who had worn a PKG logger. Subjects whose bradykinesia scores (as measured by the PKG) were >90th percentile for controls were removed. Thus, there were 174 control subjects. The reason control subjects were included was to provide a large cohort of people who would not be bradykinetic in the early morning and whose bradykinesia score would not change after a nominal “dose time” (DT). DT was 07:00 for building the model: this was chosen to ensure that levels of sleep and inactivity would be similar to the first dose in the morning of PwP. For estimating the delta of the LDCT, DT was 10:00 and chosen explicitly to avoid sleep and inactivity. The UPDRS III was deemed to be “0” at DT.
2.2. The PKG System
The PKG system consists of a wrist-worn data logger (the PKG logger), a series of algorithms that produce data points every two minutes and a series of graphs and scores that synthesize this data into a clinically useful format known as the PKG. The PKG system [
10] was the first system to receive clearance from the United States Food and Drug Administration to measure bradykinesia, and also has indications for measuring dyskinesia, tremor, and sleep.
The logger is a smart watch that is worn on the most affected wrist (see
http://www.globalkineticscorporation.com.au/ for details). It weighs 35 g and contains a rechargeable battery and a 3-axis accelerometer set to record 11-bit digital measurement of acceleration with a range of ± 4 g and a sampling rate of 50 samples per second using a digital micro-controller and data storage on flash memory. The device is water resistant. The logger has been designed and approved for easy cleaning and reuse and after 6 days of recording, data are uploaded to the cloud for application of the algorithms. The algorithms were built using an expert system approach to model neurologists’ recognition of bradykinesia and dyskinesia on accelerometry data. Inputs to the expert system included Mean Spectral Power (MSP) within bands of acceleration between 0.2 and 4 Hz, peak acceleration, and the amount of time within these epochs that there was no movement. These inputs were weighted to model neurologists’ rating of bradykinesia and dyskinesia and to produce a bradykinesia score (BKS) and dyskinesia score (DKS) every 2 min.
The PKG is the graphical representation of the output of the algorithms from data collected every 2 min over an extended period, typically 6 days. The PKG plotted the BKS and DKS against the time of day. The time that medications were due and consumed were also shown, making it possible to assess whether there were dose related variations in BKS or DKS and how the median value at any time of day compared with a normal subject. Other scores are also provided, including compliance with the reminders, tremor scores [
13], and times when the logger was not worn. The system also provides scores of day sleep and inactivity [
14]. The numerical output relevant to this study is summarized further in the Glossary that follows. The reader is referred to the company’s web site for further details (
http://www.globalkineticscorporation.com.au/) and to other publications [
10,
11,
13,
14,
15,
16,
17,
18,
19,
20]. Specific scores used in this paper are described in further details below.
2.3. Glossary of PKG Terms
- •
Bradykinesia Score (BKS). The score for bradykinesia produced by the PKG algorithm for a 2 min epoch. These inputs were weighted to model neurologists’ rating of bradykinesia. BKS are produced every 2 min while the logger is being worn.
- •
Epoch. In this paper, “epoch” will refer to a 2-min period in which PKG scores are calculated.
- •
Tremor Amplitude (PA): This is the 75th percentile of the magnitude of the tremulous peak identified from the spectrogram from each epoch. Epochs without tremor are scored zero.
- •
OFF Wrist: The logger has a capacitive sensor to detect whether it was being worn. An epoch marked as “OFF wrist” was unavailable for analysis.
- •
Dose reminder: The logger can be programmed to vibrate for 10 s at the time when levodopa should be taken as a reminder to the wearer to take medications.
Dose acknowledgement. Following a reminder, the smart screen on the logger can be “swiped” by moving the finger slowly across the screen to indicate when the medication was consumed.
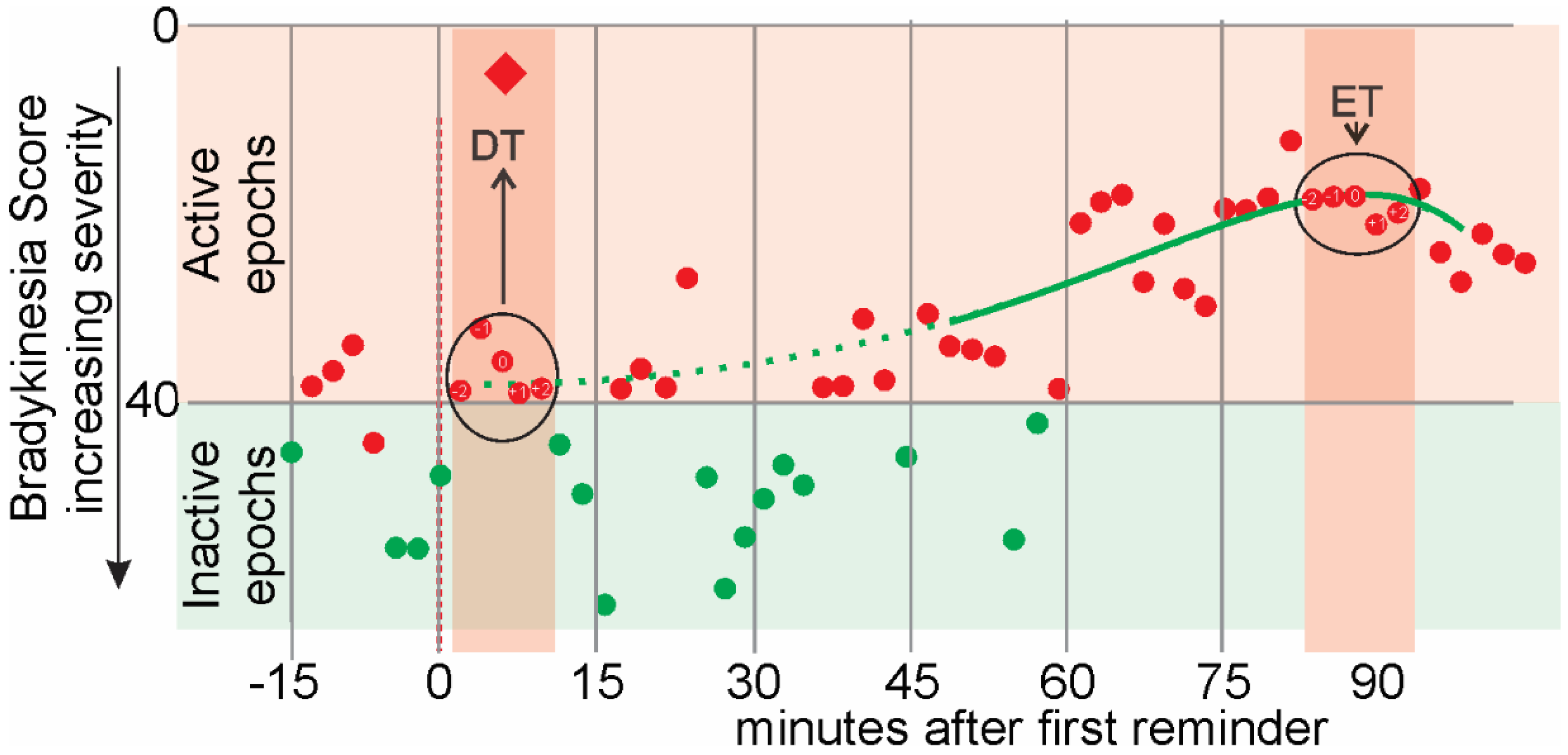
There are some terms that specifically apply to the first dose of the day (
Figure 1) and relate to the presumption in this study, that the level of motor function at the time of this first dose would be similar to the UPDRSIII
OFF and the response to this first dose would be similar to the UPDRSIII
ON.
- •
Dose Time (DT). This is the 5 epochs (10 min), centered on the acknowledgement to the first reminder of the day and shown as a red diamond in
Figure 1. It may be a few minutes after the reminder was delivered (as in
Figure 1).
- •
Effect Time (ET): This is the time when levodopa had its peak effect. It is calculated for the PKG as the peak of Smoothed Weekly BKS Time series from 46 min to 90 min after the acknowledgement of the dose reminder.
- •
Active epochs: Epochs whose linearly weighted moving median of BKS ≤ 0.
- •
Inactive epochs: Epochs whose linearly weighted moving median of BKS > 40 were attributed to inactivity or sleep and excluded [
14].
- •
Reminder Time: The PKG logger is programmed to vibrate at specific times to remind subjects to take their medications. Subjects can acknowledge when they actually consume the medications by “swiping” the smart screen on the watch. The first acknowledgement of the reminder is shown as a red diamond in
Figure 1.
The 5 epochs (10 min) centered on DT and ET were used to calculate further features of motor function from the PKG (see
Section 2.7. Feature Engineering and Selection for more detailed discussion). These features are:
- •
Weekly Aggregate Mean: Epochs from each Dose time (or Effect time) are aggregated: 5 from each dose and potentially, 6 dose times from the 6 days (week) of recording. Thus potentially, 30 epochs in total are aggregated and these are averaged to produce the weekly aggregate mean.
- •
Weekly Aggregate Standard Deviation: Epochs from each Dose time (or Effect time) are aggregated: 5 from each dose and potential 6 dose times from the 6 days (week) of recording. Thus potentially, 30 epochs in total are aggregated and the standard deviation of the aggregate is calculated to produce the weekly aggregate standard deviation.
- •
Thirty-minute window moving percentiles of BKS. The 10th, 25th, 50th, 75th and 90th percentile of the BKS value of the 15 epochs in the window around the first epoch within the DT (or ET) was estimated. The window was then slid for the five epochs within the DT (or ET) to calculate the 30-min moving percentiles of BKS. The 30-min moving percentiles approximate the shape of the distribution of a window of 30 min around each epoch. They will be referred to as, for instance, BKS_M75P for the 30 min window moving 75th percentile of BKS.
- •
Thirty-minute window weighted moving percentiles of BKS. Similarly, a 30-min weighted moving percentile of the BKS were also calculated. The weighting was linear, being maximal at the center of the window and declining linearly and symmetrically on each side to zero and provides some indication of the influence of shorter window sizes. They will be referred to as, for instance, BKS_WM75P for the 30 min window weighted moving 75th percentile of BKS.
- •
Thirty-minute window moving 50th percentile of Tremor Amplitude. This is calculated in a similar manner to the 30-min moving percentiles of BKS and will be referred to as TA_M50P.
- •
Thirty-minute window weighted moving 50th percentile of Tremor Amplitude. This was calculated in a similar manner to the 30-min window weighted moving percentiles of BKS and will be referred to as TA_WM55P.
- •
Logarithm of 1 + 30 min window weighted moving 50th percentile of Tremor Amplitude: While the BKS is linearly correlated with UPDRS III [
10] and scales logarithmically with respect to the acceleration of movement, the Tremor Score requires translating into the same scaling by defining Log (1 + Tremor Score). The “1” is added to obtain a finite non-negative feature. For example, the Log10(1 + 30 min window weighted moving 50th percentile of Tremor Amplitude) will be referred to as TA_WM50P_Log.
2.4. The Unified Parkinson’s Disease Rating Scale Part III
The UPDRS Part III is a formalized version of the clinical examination with scores (usually 0–4) for various severities of motor function. The score of each of the items is summed to give a total score. There are two versions of the UPDRS III: the older is known simply as the UPDRS III and the newer version, which is owned by The Movement Disorder Society is termed the MDS-UPDRS III. Six items were added to the scale in the MDS-UPDRS III, so that the maximum possible total score increased from 108 to 132 points. Unfortunately, both versions are frequently used in practice. Formulae for allowing the older and newer total scores to be used have been proposed [
21] but we have used a method that requires the addition of 7 points to the older scale to produce a robust correction [
22].
In this study, no subjects had missing values in the UPDRS III. Two clinics used the older UPDRS III scale and one used the MDS-UPDRS III scale. As only the total scores were used, the older scales were adjusted by the addition of 7 points and UDPRS III is used from here to refer to the adjusted score. It is important to note that in the UPDRS III, scores for tremor and bradykinesia contribute ~30% and ~40% (respectively) whereas the BKS of the PKG only relates to bradykinesia with a separate score for tremor.
2.7. Model Design for Response Estimation
The first step in designing the computational model that estimates the response to a dose of levodopa was to divide the UPDRS III into a range of motor function severity levels (MFSL
UPDRS). This was to allow severity of motor function to be categorically classified instead of requiring regressions. This allows a more robust employment of the dataset with the non-identically distributed noise and variations in UPDRS III scoring, which introduces complexity for regression models. MFSL
UPDRS “0” was set as a UPDRS III score <10 and levels above that were separated by increments of 12.5 UPDRS III units, with all scores ≥60 in level 5 (See
Table 3). Unfortunately, the literature is relatively silent on the UPDRS III of normal subjects, and while a score of UPDRS III < 10 for MFSL
UPDRS “0” is somewhat arbitrary, it is designed to be conservatively low, based on the range of scores in newly diagnosed subjects [
23] and on the clinical experience of the authors. The size of the increments in UPDRS III between higher MFSL
UPDR relate to the upper limits of inter/intra rater variability [
21,
24] and clinical important differences [
25], although we accept that there is little literature to guide this choice.
Table 3 shows the number of UPDRS
OFF and UPDRS
ON (or support sets) in each MFSL
UPDRS. The various PKG features (
Table 4 and glossary (
Section 2.3) used to measure motor function were assigned to one of the 6 MFSL class labels (
Table 3) using the corresponding UPDRS III score.
We decompose this multi-class classification problem into 5 binary classification problems, where samples are separated according to whether they fell below or above the threshold for each class. For instance, Classifier 3 will be a binary classifier separating UPDRS III < 35 and UPDRS III ≥ 35. The next section explains the design of these classifiers.
2.8. Feature Engineering and Selection
A set of candidate features (enumerated in
Table 4 and in the glossary,
Section 2.3) for performing the classification task were extracted from the PKG data and statistically matched to the class labels in
Table 3. When dealing with a relatively small dataset, having many structurally dependent features can degrade the performance of the statistical model and risks overfitting due to noise induced variance. What follows is a reduction in the size of feature space by elimination and selection to enhance the model generalizability and interpretability in a supervised manner. The first phase of feature selection was to identify features of same nature and select the most relevant. For example, the two features BKS_M50P and BKS_WM50P in
Table 3 are of the same nature in that they are both moving medians of BK Score and would thus contain similar information.
The mutual information (MI) test was performed to assess the relevance of these features to the target classes. This approach is neutral with respect to models and identifies any statistical relationship, linear or nonlinear, between the features and the class labels [
26].
Table 4 shows the MI of each feature with the 6 target classes, estimated using 6 nearest neighbors for these continuously valued features, with the 6 class labels.
Based on the above discussion, the feature set was refined to BKS_M10P, BKS_M25P, BKS_M50P, BKS_WM75P, BKS_M90P and TA_WM50P_Log. Although these scores each have considerable relevance, some carry redundant information with respect to one or a combination of the others. Joint Mutual Information Maximization (JMIM) [
27] was used to maximize relevancy while minimizing redundancy. This method first picks the feature with maximal MI with target classes and adds it to the set of selected features. It then iteratively adds the feature for which the minimum joint mutual information together with any of the already selected features is maximum among other candidates for selection. This heuristically ensures that a newly selected feature has greater relevancy and less redundancy.
Table 5 shows the ranking of iterative selection of the refined feature set applying JMIM. Also shown are the mutual information of Weekly Aggregate Mean of each feature, i.e., the average of values of the features over a 10 min interval of entire week, with target classes. This shows the relevance of a feature when aggregated at DT and ET. Evidently, BKS_M90P and BKS_WM75P were relatively less relevant. Furthermore, BKS_M50P was relatively redundant and was also less relevant after weekly aggregation. Although there was the high level of collinearity expected between BKS_M10P BKS_M25P, both features were deployed as they represent different nonparametric measures of the temporal distribution of BKS. In summary, we selected the set of features namely BKS_M10P, BKS_M25P and TA_WM50P.
2.9. Model Selection, Training and Validation
Several discriminative statistical models were examined for the purpose of designing the five binary classifications algorithms. Although the selected features are monotonically and linearly correlated with the UPDRS III, linear and nonlinear models were considered: namely Logistic Regression [
28], Support Vector Classifier [
29,
30] with Radial Basis Function (RBF) kernel and Gradient Boosting Decision Trees [
31]. These discriminative models represent categories of linear, kernel nonlinear and ensemble of arbitrarily nonlinear approaches which have proved to be effective in a variety of problem types. The three features (BKS_M10P, BKS_M25P and TA_WM50P_Log) used are defined above.
When comparing the performance of the learning models described above, it was noted that Logistic Regression assumes that the observations in the dataset are independent and that multicollinearity is not present. We previously noted the structural collinearity between BKS_M10P and BKS_M25P. To investigate the effect of the violation of this assumption on Logistic Regression, we introduce a fourth model, where unsupervised reduction of the dimension of these two features into one is achieved using the first component of Principal Component Analyses (PCA) of BKS_M10P and BKS_M25P together with TA_WM50P_Log, followed by a Logistic Regression classifier. Furthermore, as the employed features are moving statistics, neighboring epochs (observations of the same subject) are not independent when 5 epochs in a row are sampled. Two strategies were used to address assumptions regarding independence of observations: (i) using other candidate models whose requirements around this assumption are relaxed (SVM and Gradient Boosting Trees), (ii) assessing the performance of the models both in terms of model selection and out of sample predictions on Weekly Aggregate predictions, where two observations from one subject (weekly aggregate of dose time and effect time) are spaced more than 30 min apart and are thus reasonably independent. Therefore, the use of Logistic Regression as one of the candidate classifiers is possible and the performance comparisons would be meaningful.
A train set and a test set were defined for each of the classification problems (i.e., into one of the levels defined in
Table 3). For each binary classification problem, we allocate 30% samples from each class around Dose and Effect Time of the entire set to test set and use the remaining in train set. As binary classes for each classifier are different, train and test set will randomly vary across them. We ensure that if samples from a subject are used in test set, samples from that subject are not used in train set. These imply that we retain the original distribution balance in test set and ensure the complete separation of train and test sets for each classification problem.
We report two performance measures: (i) area under curve of Receiver Operating Characteristics (ROC AUC) which provides an average Sensitivity at different Specificities; (ii) area under curve of Precision (ratio of true positives to all positive declarations including false positives) vs. Recall (=Sensitivity) (PR AUC) which provides an average Precision at different Recalls averaged over the two classes. The performance metric (ii) is reported to account for the class imbalance that varies over the five Classifiers.
To tune the critical hyperparameters of each model, and assess their generalisability, a 10-fold hold-out cross validation (CV) on Train set was performed (
Table 6). First it is evident that reducing the dimensionality of the structurally collinear features with PCA did not improve the performance of the Logistic Regression. This will support the employment of BKS_M10P and BKS_M25P together as separate features in Logistic Regression model that allows to capture the distribution of BK score reflected by these two features. Second, the RBF kernel SVC and Gradient Boosting Decision Trees model do not perform as well as Logistic Regression on Classifiers 4 and 5 while not offering any advantage at Classifiers in lower levels.
Table 6 shows the performance of these models of various complexities on train set. Although Gradient Boosting Decision Trees model offers a lower bias than Logistic Regression for all classifiers, the cross-validation performance shows that the variance was not convincingly resolvable through parameter tuning.
The Logistic Regression model performs as well, if not better than the other models and is simpler in that it enhances the likelihood of generalizability and interpretability of the algorithm. Thus, the Logistic Regression model was further analyzed for validation and bias-variance assessment using the five classifier models and Logistic Regression was used in the following sections of this study.
The generalizability of the classifier models was examined by applying them to an unseen test set. Train and test sets for each classifier model were selected according to the description in the previous section. We decomposed this multi-class classification into 5 binary classification problems, where samples were separated according to whether they fell below or above the threshold for each class.
Table 7 shows the performance of each classifier model on train and test sets.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}