
A Learning Analytics Framework to Analyze Corporal Postures in Students Presentations

 , ,
, ,  ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Related Work
3. Conceptual Framework Proposal
3.1. Data Collection (Block A)
3.2. Statistical Analysis (Block B)
3.3. Clustering (Block C)
3.4. Sequential Pattern Mining (Block D)
4. Experimental Design
4.1. Learning Environment for Presentations
4.2. Lelikëlen Tool
5. Results
5.1. Data Collection
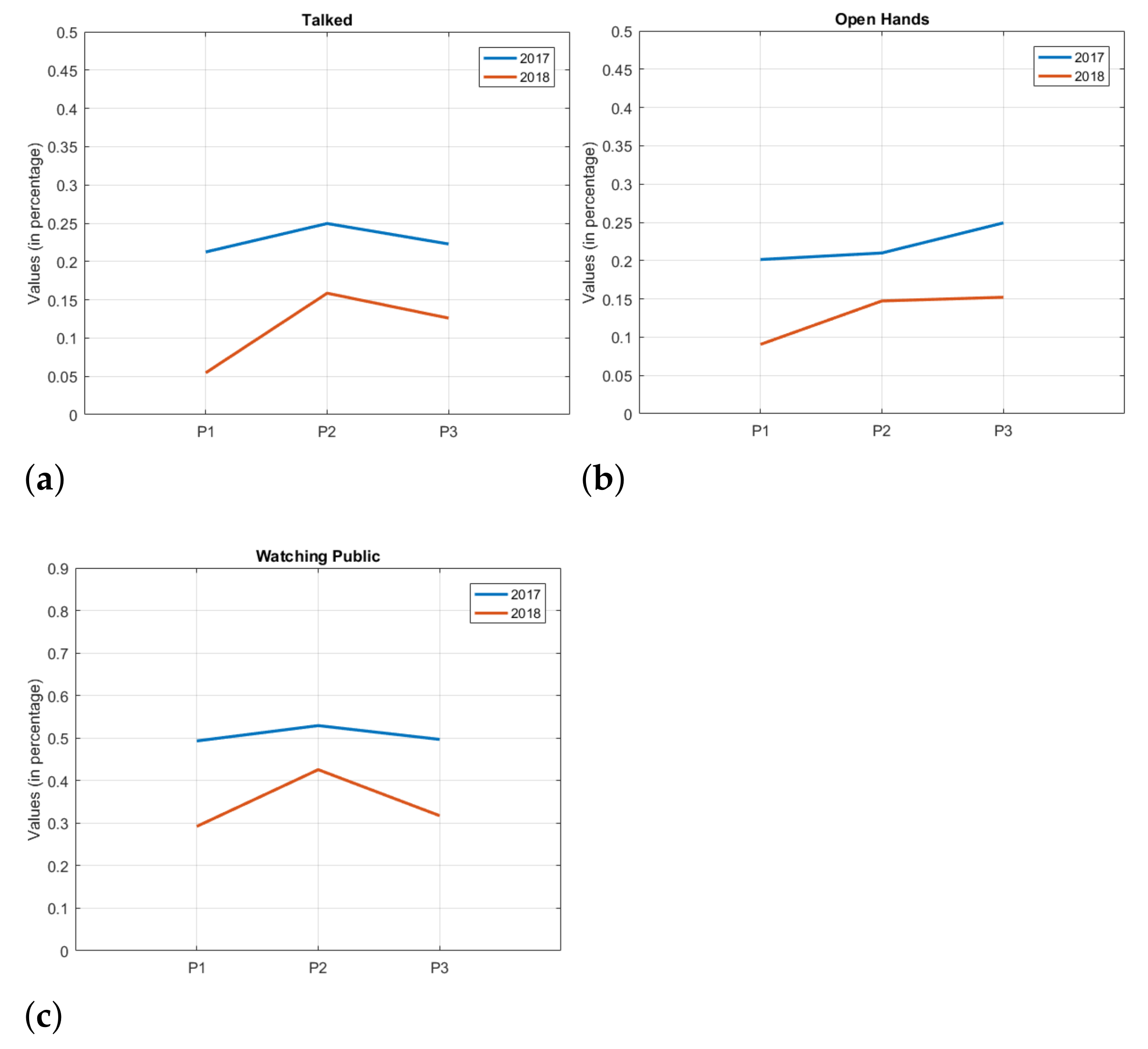
5.2. Statistical Analysis (Extraction)
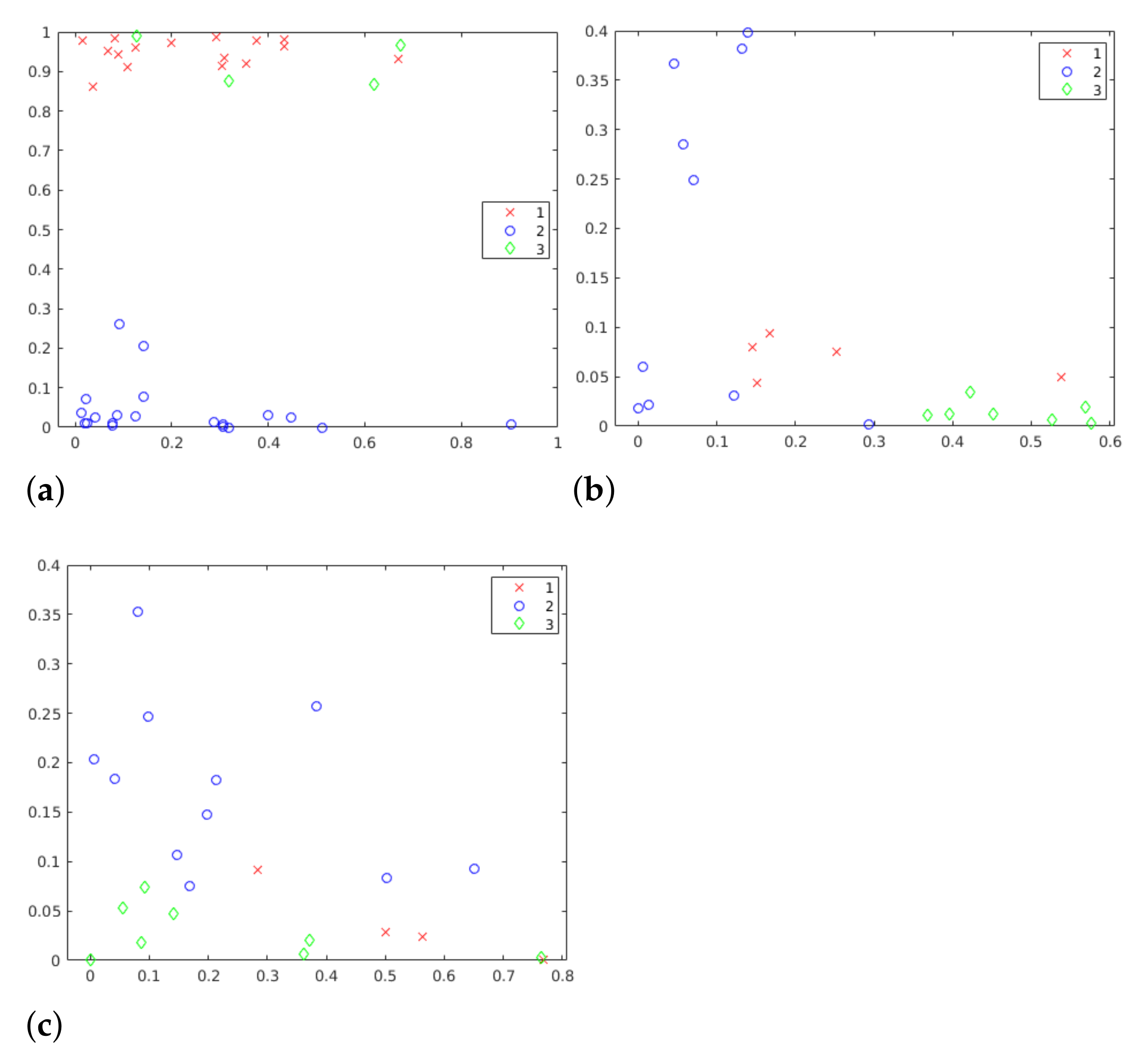
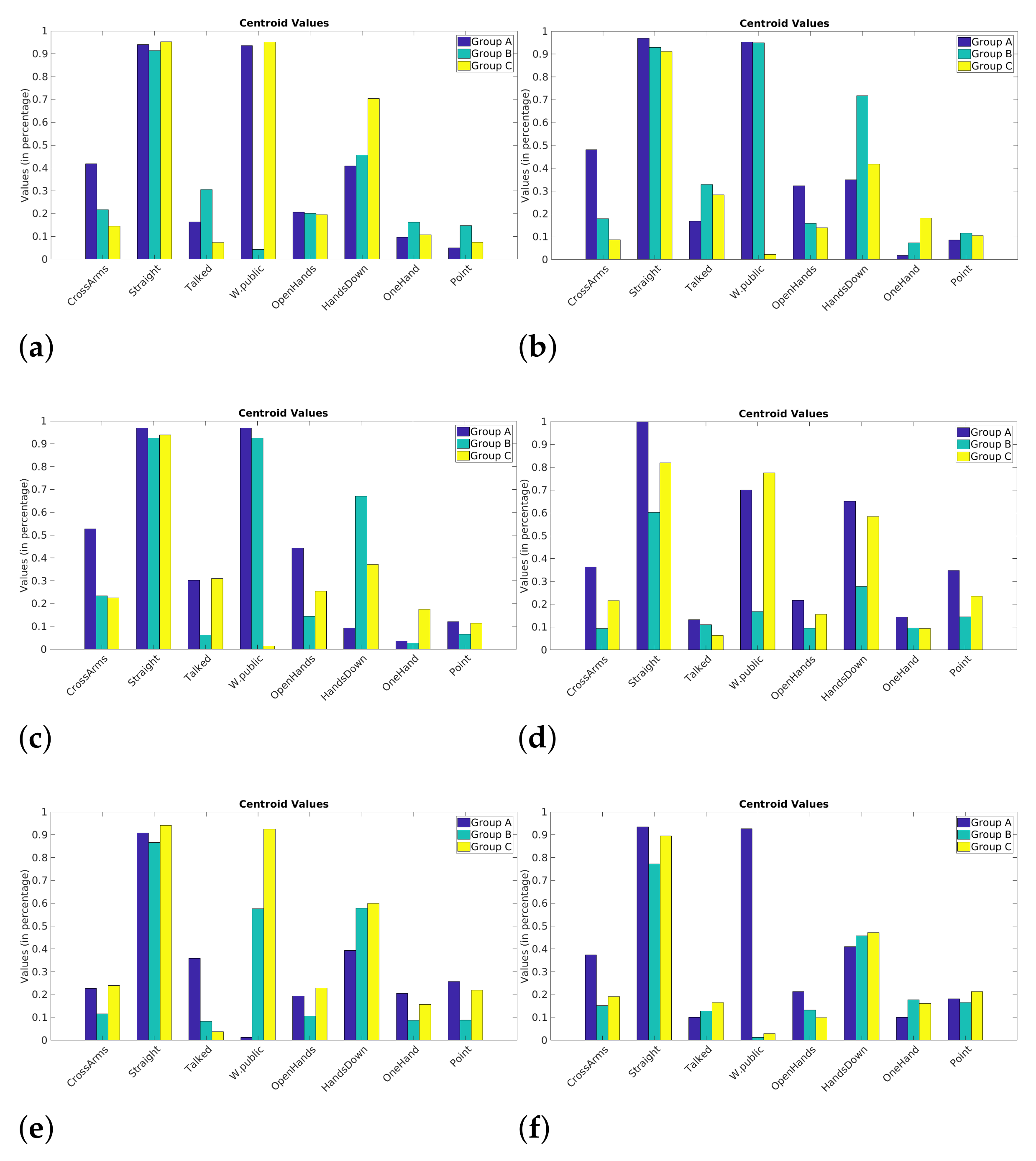
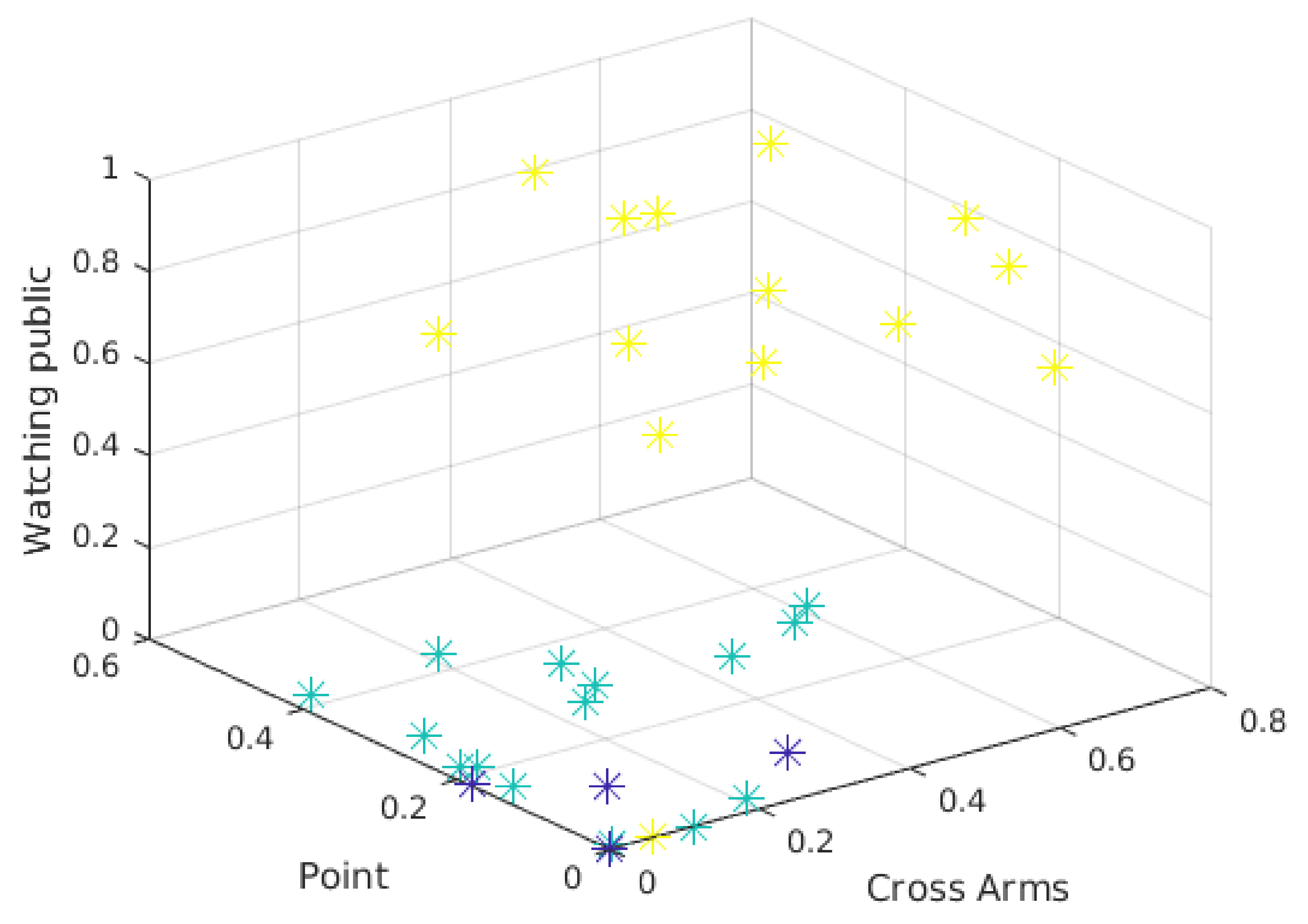
5.3. Clustering
5.3.1. k-Means Clustering
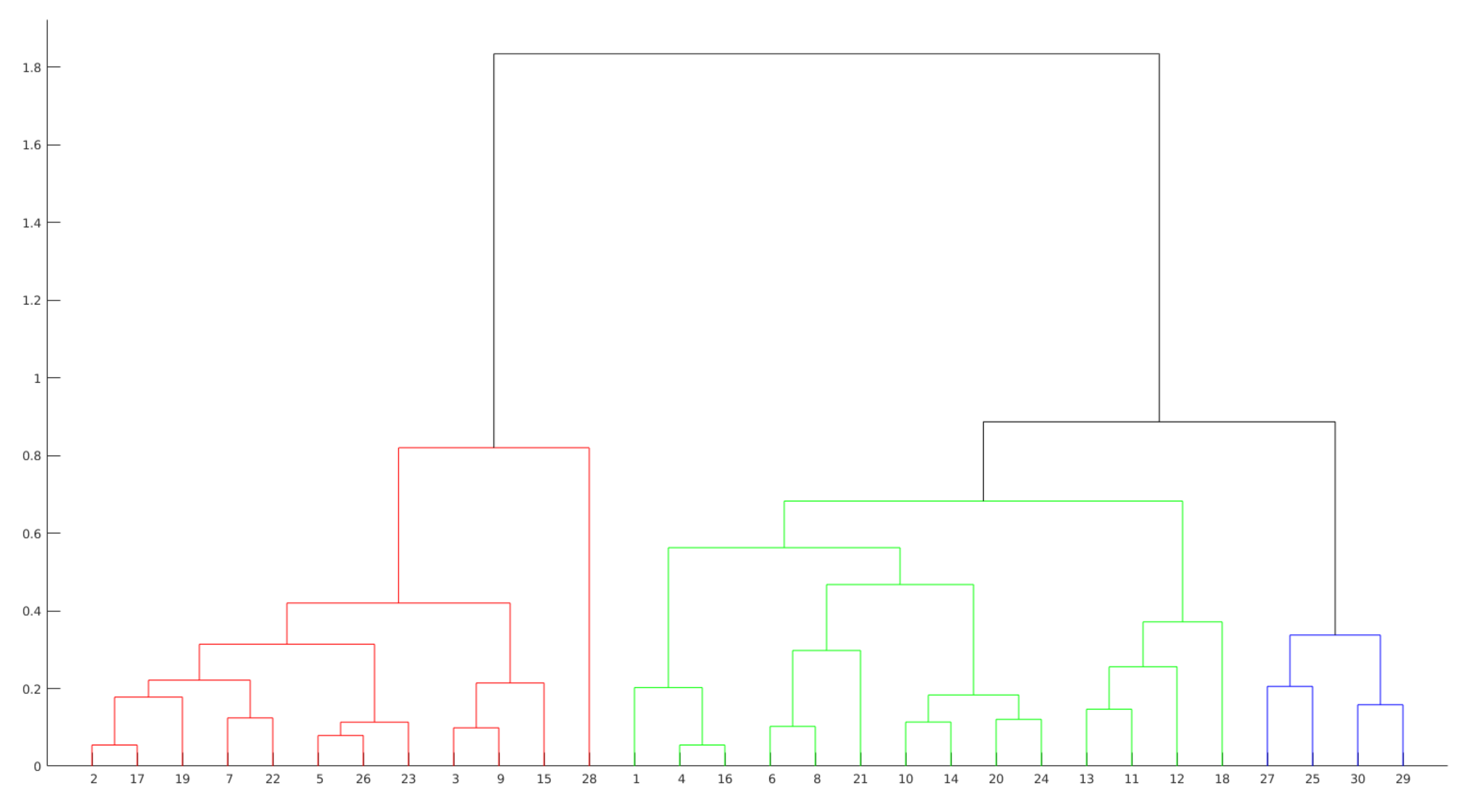
5.3.2. Hierarchical Clustering
- Assign each item to a different cluster, so for X items there will be X clusters;
- Discover the closest pair of clusters and merge them into a single cluster;
- Measure the distances between the new cluster and each of the old ones;
- Repeat steps 2 and 3 until each item is grouped into a single X-size cluster.
5.4. Sequential Patterning Mining
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rickheit, G.; Strohner, H. Handbook of Communication Competence; Walter de Gruyter: Berlin, Germany, 2008. [Google Scholar]
- Burgoon, J.K.; Hoobler, G.D. Nonverbal signals. Handb. Interpers. Commun. 1994, 2, 229–285. [Google Scholar]
- Hymes, D. On communicative competence. Sociolinguistics 1972, 269293, 269–293. [Google Scholar]
- Wörtwein, T.; Chollet, M.; Schauerte, B.; Morency, L.P.; Stiefelhagen, R.; Scherer, S. Multimodal public speaking performance assessment. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 43–50. [Google Scholar]
- Rasipuram, S.; Jayagopi, D.B. Automatic multimodal assessment of soft skills in social interactions: A review. Multimed. Tools Appl. 2020, 79, 13037–13060. [Google Scholar] [CrossRef]
- Chen, L.; Feng, G.; Joe, J.; Leong, C.W.; Kitchen, C.; Lee, C.M. Towards automated assessment of public speaking skills using multimodal cues. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 200–203. [Google Scholar]
- Hart, J.; Gratch, J.; Marsella, S. How virtual reality training can win friends and influence people. Hum. Factors Def. Ashgate 2013, 21, 235–249. [Google Scholar]
- Blikstein, P.; Worsley, M. Multimodal Learning Analytics and Education Data Mining: Using computational technologies to measure complex learning tasks. J. Learn. Anal. 2016, 3, 220–238. [Google Scholar] [CrossRef] [Green Version]
- Beyan, C.; Carissimi, N.; Capozzi, F.; Vascon, S.; Bustreo, M.; Pierro, A.; Becchio, C.; Murino, V. Detecting emergent leader in a meeting environment using nonverbal visual features only. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 317–324. [Google Scholar]
- Schneider, B.; Blikstein, P. Unraveling students’ interaction around a tangible interface using multimodal learning analytics. J. Educ. Data Min. 2015, 7, 89–116. [Google Scholar]
- Mory, E.H. Feedback Research Revisited. In Handbook of Research on Educational Communications and Technology; Routledge: Abingdon-on-Thames, UK, 2013; pp. 738–776. [Google Scholar]
- Cechinel, C.; Ochoa, X.; Lemos dos Santos, H.; Carvalho Nunes, J.B.; Rodés, V.; Marques Queiroga, E. Mapping Learning Analytics initiatives in Latin America. Br. J. Educ. Technol. 2020, 51, 892–914. [Google Scholar] [CrossRef]
- Imenda, S. Is there a conceptual difference between theoretical and conceptual frameworks? J. Soc. Sci. 2014, 38, 185–195. [Google Scholar] [CrossRef]
- Liehr, P.; Smith, M.J. Middle range theory: Spinning research and practice to create knowledge for the new millennium. Adv. Nurs. Sci. 1999, 21, 81–91. [Google Scholar] [CrossRef] [PubMed]
- Worsley, M. Multimodal Learning Analytics’ Past, Present, and Potential Futures. In Proceedings of the Companion Proceedings 8th International Conference on Learning Analytics & Knowledge (LAK18) Creative Commons, CrossMMLA@ LAK, Sydney, Australia, 5–9 March 2018. [Google Scholar]
- Munoz, R.; Villarroel, R.; Barcelos, T.S.; Souza, A.; Merino, E.; Guiñez, R.; Silva, L.A. Development of a Software that Supports Multimodal Learning Analytics: A Case Study on Oral Presentations. J. Univers. Comput. Sci. 2018, 24, 149–170. [Google Scholar]
- Reilly, J.; Ravenell, M.; Schneider, B. Exploring Collaboration Using Motion Sensors and Multi-Modal Learning Analytics. In Proceedings of the 11th International Conference on Educational Data Mining, Buffalo, NY, USA, 15–18 July 2018. [Google Scholar]
- Chan, M.C.E.; Ochoa, X.; Clarke, D. Multimodal learning analytics in a laboratory classroom. In Machine Learning Paradigms; Springer: Berlin/Heidelberg, Germany, 2020; pp. 131–156. [Google Scholar]
- Van Ginkel, S.; Gulikers, J.; Biemans, H.; Noroozi, O.; Roozen, M.; Bos, T.; van Tilborg, R.; van Halteren, M.; Mulder, M. Fostering oral presentation competence through a virtual reality-based task for delivering feedback. Comput. Educ. 2019, 134, 78–97. [Google Scholar] [CrossRef]
- Roque, F.; Cechinel, C.; Weber, T.O.; Lemos, R.; Villarroel, R.; Miranda, D.; Munoz, R. Using Depth Cameras to Detect Patterns in Oral Presentations: A Case Study Comparing Two Generations of Computer Engineering Students. Sensors 2019, 19, 3493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cukurova, M.; Luckin, R.; Millán, E.; Mavrikis, M. The NISPI framework: Analysing collaborative problem-solving from students’ physical interactions. Comput. Educ. 2018, 116, 93–109. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, S.; Zhang, Z.; Xiao, W.; Yu, S. A framework for learning analytics using commodity wearable devices. Sensors 2017, 17, 1382. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prieto, L.P.; Rodríguez-Triana, M.J.; Martínez-Maldonado, R.; Dimitriadis, Y.; Gašević, D. Orchestrating learning analytics (OrLA): Supporting inter-stakeholder communication about adoption of learning analytics at the classroom level. Australas. J. Educ. Technol. 2019, 35. [Google Scholar] [CrossRef]
- Echeverria, V.; Martinez-Maldonado, R.; Granda, R.; Chiluiza, K.; Conati, C.; Shum, S.B. Driving data storytelling from learning design. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge, Sydney, Australia, 5–9 March 2018; pp. 131–140. [Google Scholar]
- Martinez-Maldonado, R.; Echeverria, V.; Santos, O.C.; Santos, A.D.P.D.; Yacef, K. Physical learning analytics: A multimodal perspective. In Proceedings of the 8th International Conference on Learning Analytics and Knowledge, Sydney, Australia, 5–9 March 2018; pp. 375–379. [Google Scholar]
- De Koning, B.B.; Tabbers, H.K.; Rikers, R.M.; Paas, F. Attention guidance in learning from a complex animation: Seeing is understanding? Learn. Instr. 2010, 20, 111–122. [Google Scholar] [CrossRef]
- Zhu, G.; Xing, W.; Popov, V. Uncovering the sequential patterns in transformative and non-transformative discourse during collaborative inquiry learning. Internet High. Educ. 2019, 41, 51–61. [Google Scholar] [CrossRef]
- Cornide-Reyes, H.; Noël, R.; Riquelme, F.; Gajardo, M.; Cechinel, C.; Mac Lean, R.; Becerra, C.; Villarroel, R.; Munoz, R. Introducing Low-Cost Sensors into the Classroom Settings: Improving the Assessment in Agile Practices with Multimodal Learning Analytics. Sensors 2019, 19, 3291. [Google Scholar] [CrossRef] [Green Version]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Leong, C.W.; Feng, G.; Lee, C.M.; Somasundaran, S. Utilizing multimodal cues to automatically evaluate public speaking performance. In Proceedings of the International Conference on IEEE Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–25 September 2015; pp. 394–400. [Google Scholar]
- Echeverria, V.; Avendaño, A.; Chiluiza, K.; Vásquez, A.; Ochoa, X. Presentation skills estimation based on video and kinect data analysis. In Proceedings of the 2014 ACM workshop on Multimodal Learning Analytics Workshop and Grand Challenge, Istanbul, Turkey, 12–16 November 2014; pp. 53–60. [Google Scholar]
- Barmaki, R.; Hughes, C.E. Providing Real-Time Feedback for Student Teachers in a Virtual Rehearsal Environment. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, ICMI ’15, Seattle, WA, USA, 9–13 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 531–537. [Google Scholar] [CrossRef] [Green Version]
- Gibbons, J.D.; Chakraborti, S. Nonparametric statistical inference. In International encyclopedia of statistical science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 977–979. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Cavanagh, M.; Bower, M.; Moloney, R.; Sweller, N. The effect over time of a video-based reflection system on preservice teachers’ oral presentations. Aust. J. Teach. Educ. 2014, 39, 1. [Google Scholar] [CrossRef] [Green Version]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB ’94, Santiago, Chile, 12–15 September 1994; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 487–499. [Google Scholar]
- Agrawal, R.; Srikant, R. Mining sequential patterns. In Proceedings of the Eleventh International Conference on Data Engineering, Taipei, Taiwan, 6–10 March 1995; pp. 3–14. [Google Scholar] [CrossRef]
- Saraf, P.; Sedamkar, R.; Rathi, S. PrefixSpan Algorithm for Finding Sequential Pattern with Various Constraints. Int. J. Appl. Inf. Syst. (IJAIS) 2015, 9. [Google Scholar] [CrossRef]
- Nie, L.; Liu, M.; Song, X. Multimodal Learning toward Micro-Video Understanding; Morgan & Claypool: San Rafael, CA, USA, 2019; Volume 9, p. 186. [Google Scholar] [CrossRef]
- Nie, L.; Zhang, L.; Yang, Y.; Wang, M.; Hong, R.; Chua, T.S. Beyond Doctors: Future Health Prediction from Multimedia and Multimodal Observations. In Proceedings of the 23rd ACM International Conference on Multimedia, MM ’15, Brisbane, Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 591–600. [Google Scholar] [CrossRef]
- Fournier-Viger, P.; Lin, J.C.W.; Gomariz, A.; Gueniche, T.; Soltani, A.; Deng, Z.; Lam, H.T. The SPMF open-source data mining library version 2. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; pp. 36–40. [Google Scholar]
- Fournier-Viger, P.; Lin, J.C.W.; Kiran, R.U.; Koh, Y.S.; Thomas, R. A survey of sequential pattern mining. Data Sci. Pattern Recognit. 2017, 1, 54–77. [Google Scholar]
- Barros, F.; Conde, Â.; Soares, S.C.; Neves, A.J.; Silva, S. Understanding Public Speakers’ Performance: First Contributions to Support a Computational Approach. In Proceedings of the International Conference on Image Analysis and Recognition, Póvoa de Varzim, Portugal, 24–26 June 2020; pp. 343–355. [Google Scholar]
- Spikol, D.; Cukurova, M. Multimodal Learning Analytics. In Encyclopedia of Education and Information Technologies; Tatnall, A., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Ochoa, X.; Dominguez, F. Controlled evaluation of a multimodal system to improve oral presentation skills in a real learning setting. Br. J. Educ. Technol. 2020, 51, 1615–1630. [Google Scholar] [CrossRef]
- Cabezas, P.; Spinuzzi, C.; Sabaj, O.; Varas, G. Editing the Pitch: Patterns of Editing Strategies of Written Pitches in a Chilean Accelerator Program. IEEE Trans. Prof. Commun. 2020, 63, 296–310. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Process |
|---|---|
| A | Input: Student presentations. Activity: (1) Collect data from oral presentations; (2) Classify data in body/voice/action; (3) Tabulate the data; (4) Generate the database containing the observations with their times added to each attribute. Output: Database containing the students’ time intervals with respective body posture/voice. |
| B | Input: Database containing the students’ time intervals. Activity: (1) Visualize data comparing the databases; (2) Average the values of each attribute; (3) Inferential test comparing the two or more databases. Output: Information graphics; table comparing the most present attributes; Inferential comparison between databases and evaluated presentations. |
| C | Input: Database with observations. Activity: (1) Perform clustering techniques; (2) Save all clustering results for later evaluation, that is, index, centroids and so forth; (3) For each cluster value, run a cluster evaluation algorithm; (4) Visually evaluate the results if possible; (5) Create/use analytics methods to choose the best value of clusters to the problem; (6) Critical inspection on data results to find patterns. Output: Decision of the best cluster value for the problem; patterns that clustering method allows to find; plots showing the patterns and characterization of clusters. |
| D | Input: Database containing the students’ time intervals. Activity: (1) Transform the initial database into a sequential database (database formed by the sequence of the attributes for each student in each presentation; (2) Transform the data to the (default) format for the sequential pattern mining tool; (3) Test minimum support values to see what best fits the problem; (4) Create visual methods to discover the patterns; (5) Correlate the sequences results with the other data results. Output: More frequent sequences given a minimum support value; relation between the other results. |
| Attribute | Description |
|---|---|
| Cross Arms | The presenter crossed both arms. |
| Downside | The presenter’s tilt is greater than 0.333, with −1 tilted back and 1 tilted forward. |
| Straight | The presenter’s tilt is between −0.333 and 0.333, with −1 tilted back and 1 tilted forward. |
| Watching Public | The presenter is looking at the audience. |
| Hand on Face | The presenter has one hand on the chin. |
| Open Hands | The presenter is explaining with both hands. |
| Hands Down | The presenter has his hands down. |
| One Hand | The presenter is explaining with one hand to down and the other doubled in an explanatory position. |
| Hand on Hip | The presenter has his hands on hip. |
| Hand on Head | The presenter has one hand on his head. |
| Point | The presenter is pointing with one hand. |
| Talked | The presenter’s voice is detected. |
| Year | Presentation Period | Number of Students |
|---|---|---|
| Year 1 | P1 | 40 |
| P2 | 22 | |
| P3 | 22 | |
| Year 2 | P1 | 59 |
| P2 | 45 | |
| P3 | 34 |
| Years | Presentations | Statistically Different Attributes |
|---|---|---|
| P1XP2 | 1 | |
| 1 | P1XP3 | 0 |
| P2XP3 | 2 | |
| P1XP2 | 3 | |
| Year 2 | P1XP3 | 1 |
| P2XP3 | 0 | |
| P1XP1 | 6 | |
| Year 1 × Year 2 | P2XP2 | 3 |
| P3XP3 | 1 |
| Id | Pattern | Sup |
|---|---|---|
| 10 | Cross Arms, Hands Down, Open Hands, Cross Arms, Straight | 40 |
| 20 | Cross Arms, Hands Down, Talked, Straight | 39 |
| 30 | Cross Arms, One Hand, Open Hands, Straight | 39 |
| 40 | Cross Arms, Talked, Straight | 39 |
| 50 | Hands Down, One Hand, Talked, Straight | 39 |
| 60 | Talked, Cross Arms, Hands Down | 39 |
| 70 | Cross Arms, Talked, One Hand, Straight | 38 |
| 80 | Hands Down, Talked, Cross Arms, Open Hands, Cross Arms, Hands Down | 38 |
| 90 | Talked, One Hand, Open Hands, Hands Down, Straight | 38 |
| Id | Pattern | Sup |
|---|---|---|
| 10 | Cross Arms, One Hand, Open Hands, Straight | 21 |
| 20 | Hand on Face, Hands Down, Open Hands, Hands Down, One Hand, Open Hands, Straight | 21 |
| 30 | Hands on Hip, Open Hands, Straight | 21 |
| 40 | One Hand, Open Hands, Talked, Open Hands, Talked, Straight | 21 |
| 50 | One Hand, Point, One Hand, Straight | 21 |
| 60 | Open Hands, One Hand, Point, Open Hands, Straight | 21 |
| Id | Pattern | Sup |
|---|---|---|
| 10 | Cross Arms, Hands Down, Open Hands, Straight | 23 |
| 20 | Cross Arms, Hands Down, Open Hands, Watching Public | 23 |
| 30 | Hands Down, One Hand, Straight | 23 |
| 40 | Hands Down, One Hand, Watching Public | 23 |
| 50 | One Hand, Point, Open Hands, Straight | 23 |
| 60 | Hands Down, Open Hands, Point, Hands Down, Straight | 22 |
| 70 | Hands Down, One Hand, Open Hands, Watching Public | 22 |
| 80 | Point, Open Hands, One Hand, Straight | 22 |
| Id | Pattern | Sup |
|---|---|---|
| 10 | Cross Arms, Hands Down | 25 |
| 20 | Hand on Face, Hands Down | 25 |
| 30 | Open Hands, One Hand | 25 |
| 40 | Open Hands, Open Hands, Hands Down | 25 |
| 50 | Hand on Face, Hand on Face, Hands Down | 24 |
| 60 | Cross Arms, Point | 23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vieira, F.; Cechinel, C.; Ramos, V.; Riquelme, F.; Noel, R.; Villarroel, R.; Cornide-Reyes, H.; Munoz, R. A Learning Analytics Framework to Analyze Corporal Postures in Students Presentations. Sensors 2021, 21, 1525. https://doi.org/10.3390/s21041525
Vieira F, Cechinel C, Ramos V, Riquelme F, Noel R, Villarroel R, Cornide-Reyes H, Munoz R. A Learning Analytics Framework to Analyze Corporal Postures in Students Presentations. Sensors. 2021; 21(4):1525. https://doi.org/10.3390/s21041525
Chicago/Turabian StyleVieira, Felipe, Cristian Cechinel, Vinicius Ramos, Fabián Riquelme, Rene Noel, Rodolfo Villarroel, Hector Cornide-Reyes, and Roberto Munoz. 2021. "A Learning Analytics Framework to Analyze Corporal Postures in Students Presentations" Sensors 21, no. 4: 1525. https://doi.org/10.3390/s21041525