
Parametric and Non-Parametric Analyses for Pedestrian Crash Severity Prediction in Great Britain

 , , ,
, , ,  , and
, and
Abstract
:1. Introduction
2. Prior Research
3. Crash Data
4. Method
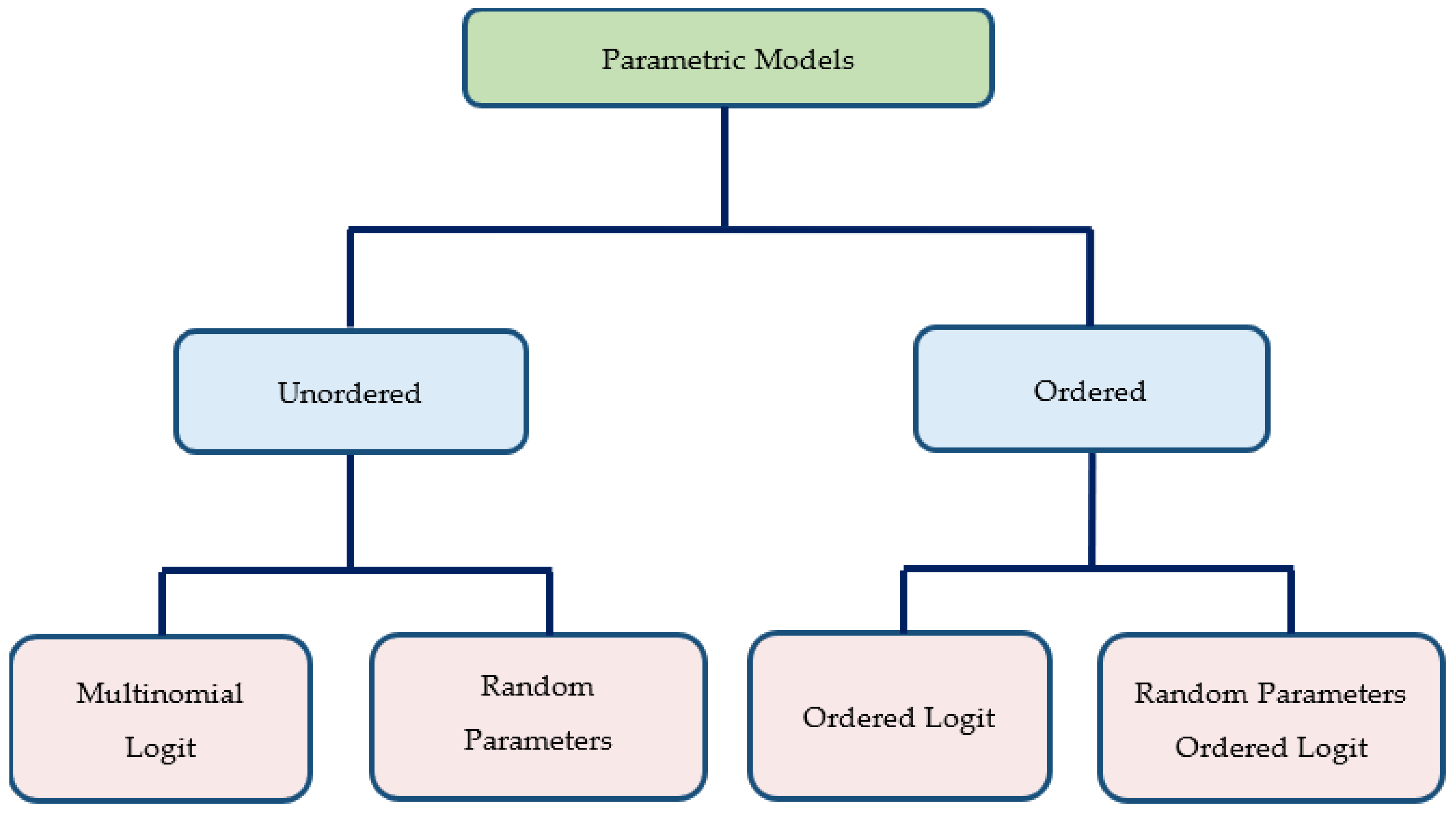
4.1. Parametric Models
4.1.1. General Issues
4.1.2. Multinomial Logit Model
- is a (K × 1) column vector of K exogenous attributes (geometric variables, environmental conditions, driver characteristics, etc.) that affects the pedestrian injury severity level (j); and
- is a (K × 1) column vector of the estimable parameters for the crash severity category (j).
4.1.3. Random Parameter Multinomial Logit Model
4.1.4. Ordered Logit Model
4.1.5. Random Parameter Ordered Logit Model
4.2. Non-Parametric Models
4.2.1. Association Rules
4.2.2. Classification Trees
4.2.3. Random Forests
- A bootstrap sample, which creates a random sample with a replacement from the original sample, with the sample size (Nt) replicated B times.
- For each bootstrap sample, the growing of a tree uses the CART algorithm, and chooses, at each node, the best split among a randomly selected subset of descriptors;
- Repeat the above steps until B trees are generated.
4.2.4. Artificial Neural Networks
- The backpropagation algorithm starts with random weights, and the goal is to adjust them to reduce this error until the ANN learns the training data;
- If the expected output is not obtained, backward propagation begins. The difference between the actual and the expected outputs is calculated recursively and step by step, and the error is returned through the original link access;
- The weight and the value of each neuron are then modified and are transmitted successively to the input layer, and the forward multilayer perceptron restarts.
4.2.5. Support Vector Machines
4.3. Dealing with Imbalanced Data
4.4. Comparison among the Models
5. Results
5.1. Parametric Models
5.1.1. Multinomial Logit Model
5.1.2. Random Parameter Multinomial Logit Model
5.1.3. Ordered Logit Model
5.1.4. Random Parameter Ordered Logit Model
5.2. Non-Parametric Models
5.2.1. Association Rules
5.2.2. Classification Tree
5.2.3. Random Forests
5.2.4. Artificial Neural Networks
5.2.5. Support Vector Machine Model
5.3. Model Comparisons
5.3.1. Significant Explanatory Variables and Effects on Crash Severity
Pedestrian Characteristics
Driver Characteristics
Vehicle Characteristics
Roadway Characteristics
Junction Characteristics
Environmental Characteristics
Crash Characteristics
5.3.2. Measures of Performance
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Fatal | Serious | Slight | Total | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| First Road Class | ||||||||
| Motorway | 47 | 32.2 | 49 | 33.6 | 50 | 34.2 | 146 | 0.2 |
| A | 747 | 3.3 | 5941 | 26.2 | 16,013 | 70.5 | 22,701 | 33.7 |
| B | 128 | 1.8 | 1819 | 25.7 | 5129 | 72.5 | 7076 | 10.5 |
| C | 78 | 1.6 | 1067 | 22.0 | 3712 | 76.4 | 4857 | 7.2 |
| Missing | 366 | 1.1 | 7483 | 23.0 | 24,727 | 75.9 | 32,576 | 48.4 |
| Road Type | ||||||||
| Dual carriageway | 296 | 5.2 | 1653 | 28.9 | 3763 | 65.9 | 5712 | 8.5 |
| Single carriageway | 990 | 1.8 | 13,285 | 24.4 | 40,200 | 73.8 | 54,475 | 80.9 |
| One-way street | 43 | 1.1 | 833 | 21.3 | 3026 | 77.5 | 3902 | 5.8 |
| Roundabout | 15 | 1.4 | 236 | 21.5 | 846 | 77.1 | 1097 | 1.6 |
| Slip road | 12 | 2.4 | 97 | 19.6 | 387 | 78.0 | 496 | 0.7 |
| Missing | 10 | 0.6 | 255 | 15.2 | 1409 | 84.2 | 1674 | 2.5 |
| Second Road Class | ||||||||
| Motorway | 5 | 17.9 | 9 | 32.1 | 14 | 50.0 | 28 | 0.0 |
| A | 97 | 1.8 | 1284 | 23.6 | 4051 | 74.6 | 5432 | 8.1 |
| B | 46 | 2.3 | 492 | 24.5 | 1471 | 73.2 | 2009 | 3.0 |
| C | 34 | 1.6 | 486 | 22.6 | 1631 | 75.8 | 2151 | 3.2 |
| Missing | 439 | 1.7 | 6553 | 24.7 | 19,574 | 73.7 | 26,566 | 39.4 |
| n.a. | 745 | 2.4 | 7536 | 24.2 | 22,891 | 73.4 | 31,172 | 46.3 |
| Speed Limit | ||||||||
| 20 mph | 74 | 0.9 | 1840 | 21.9 | 6476 | 77.2 | 8390 | 12.5 |
| 30 mph | 821 | 1.5 | 13,007 | 23.9 | 40,697 | 74.6 | 54,525 | 81.0 |
| 40 mph | 129 | 5.4 | 829 | 34.7 | 1429 | 59.9 | 2387 | 3.5 |
| ≥50 mph | 342 | 16.7 | 681 | 33.3 | 1020 | 49.9 | 2043 | 3.0 |
| Missing | 0 | 0.0 | 2 | 18.2 | 9 | 81.8 | 11 | 0.0 |
| Junction Detail | ||||||||
| T or staggered junction | 366 | 1.7 | 5472 | 24.8 | 16,240 | 73.6 | 22,078 | 32.8 |
| Crossroads | 108 | 1.9 | 1411 | 24.6 | 4208 | 73.5 | 5727 | 8.5 |
| More than 4 arms (not roundabout) | 14 | 1.6 | 199 | 23.4 | 638 | 75.0 | 851 | 1.3 |
| Mini-roundabout | 6 | 1.0 | 128 | 21.5 | 462 | 77.5 | 596 | 0.9 |
| Roundabout | 34 | 1.8 | 467 | 24.1 | 1438 | 74.2 | 1939 | 2.9 |
| Slip road | 27 | 7.2 | 103 | 27.5 | 244 | 65.2 | 374 | 0.6 |
| Private drive or entrance | 25 | 1.7 | 325 | 21.9 | 1135 | 76.4 | 1485 | 2.2 |
| Not at junction | 745 | 2.4 | 7536 | 24.2 | 22,891 | 73.4 | 31,172 | 46.3 |
| Other junction | 41 | 1.5 | 697 | 25.0 | 2051 | 73.5 | 2789 | 4.1 |
| Missing | 0 | 0.0 | 21 | 6.1 | 324 | 93.9 | 345 | 0.5 |
| Junction Control | ||||||||
| Authorized person | 2 | 0.6 | 60 | 17.9 | 273 | 81.5 | 335 | 0.5 |
| Auto traffic signal | 163 | 2.1 | 1939 | 25.5 | 5514 | 72.4 | 7616 | 11.3 |
| Give way/uncontrolled | 451 | 1.7 | 6669 | 24.8 | 19,792 | 73.5 | 26,912 | 40.0 |
| Stop sign | 3 | 0.9 | 64 | 19.9 | 254 | 79.1 | 321 | 0.5 |
| Not at junction or within 20 m | 747 | 2.3 | 7627 | 23.7 | 23,798 | 74.0 | 32,172 | 47.8 |
| Variable | Fatal | Serious | Slight | Total | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| Area | ||||||||
| Rural | 457 | 5.7 | 2149 | 26.9 | 5392 | 67.4 | 7998 | 11.9 |
| Urban | 909 | 1.5 | 14,208 | 23.9 | 44,232 | 74.5 | 59,349 | 88.1 |
| Missing | 0 | 0.0 | 2 | 22.2 | 7 | 77.8 | 9 | 0.0 |
| Pedestrian-Crossing Human Control | ||||||||
| School-crossing patrol | 2 | 0.4 | 88 | 17.8 | 403 | 81.7 | 493 | 0.7 |
| None within 50 m | 1345 | 2.1 | 15,918 | 24.6 | 47,494 | 73.3 | 64,757 | 96.1 |
| Other | 14 | 1.3 | 232 | 21.7 | 824 | 77.0 | 1070 | 1.6 |
| Missing | 5 | 0.5 | 121 | 11.7 | 910 | 87.8 | 1036 | 1.5 |
| Pedestrian-Crossing Physical Facilities | ||||||||
| No physical crossing facilities within 50 m | 931 | 2.1 | 10,567 | 24.1 | 32,387 | 73.8 | 43,885 | 65.2 |
| Central refuge | 67 | 2.7 | 702 | 28.1 | 1725 | 69.2 | 2494 | 3.7 |
| Footbridge/subway | 8 | 6.2 | 48 | 36.9 | 74 | 56.9 | 130 | 0.2 |
| Pedestrian phase at traffic signal junction | 125 | 1.8 | 1785 | 25.4 | 5108 | 72.8 | 7018 | 10.4 |
| Pelican, puffin, toucan, or similar nonjunction pedestrian light crossing | 192 | 2.5 | 2102 | 27.4 | 5368 | 70.1 | 7662 | 11.4 |
| Zebra | 39 | 0.8 | 1038 | 20.4 | 4005 | 78.8 | 5082 | 7.5 |
| Missing | 4 | 0.4 | 117 | 10.8 | 964 | 88.8 | 1085 | 1.6 |
| Lighting | ||||||||
| Daylight | 632 | 1.3 | 10,840 | 22.8 | 36,040 | 75.9 | 47,512 | 70.5 |
| Darkness—lighting unknown | 31 | 2.2 | 300 | 21.6 | 1056 | 76.1 | 1387 | 2.1 |
| Darkness—lights lit | 456 | 2.7 | 4654 | 27.9 | 11,585 | 69.4 | 16,695 | 24.8 |
| Darkness—lights unlit | 25 | 4.9 | 151 | 29.3 | 339 | 65.8 | 515 | 0.8 |
| Darkness—no lighting | 222 | 17.8 | 414 | 33.2 | 611 | 49.0 | 1247 | 1.9 |
| Weather | ||||||||
| Fine no high winds | 1127 | 2.1 | 13,423 | 24.4 | 40,369 | 73.5 | 54,919 | 81.5 |
| Fine + high winds | 17 | 2.7 | 180 | 29.0 | 423 | 68.2 | 620 | 0.9 |
| Fog or mist | 8 | 5.0 | 45 | 28.3 | 106 | 66.7 | 159 | 0.2 |
| Raining + high winds | 21 | 3.1 | 208 | 31.1 | 440 | 65.8 | 669 | 1.0 |
| Raining, no high winds | 137 | 2.0 | 1693 | 25.3 | 4857 | 72.6 | 6687 | 9.9 |
| Snowing | 13 | 3.4 | 101 | 26.2 | 272 | 70.5 | 386 | 0.6 |
| Other | 17 | 1.4 | 253 | 21.3 | 916 | 77.2 | 1186 | 1.8 |
| Missing | 26 | 1.0 | 456 | 16.7 | 2248 | 82.3 | 2730 | 4.1 |
| Pavement | ||||||||
| Dry | 921 | 1.8 | 12,158 | 23.8 | 37,997 | 74.4 | 51,076 | 75.8 |
| Wet or damp | 432 | 2.9 | 3914 | 26.6 | 10,393 | 70.5 | 14,739 | 21.9 |
| Snowy/Frozen | 12 | 1.7 | 173 | 24.7 | 515 | 73.6 | 700 | 1.0 |
| Missing | 1 | 0.1 | 114 | 13.6 | 726 | 86.3 | 841 | 1.2 |
| Day of Week | ||||||||
| Weekday | 955 | 1.8 | 12,413 | 23.7 | 39,094 | 74.5 | 52,462 | 77.9 |
| Weekend | 411 | 2.8 | 3946 | 26.5 | 10,537 | 70.7 | 14,894 | 22.1 |
| Crash Severity | 1366 | 2.0 | 16,359 | 24.3 | 49,631 | 73.7 | 67,356 | 100.0 |
| Variable | Fatal | Serious | Slight | Total | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| Number of Vehicles | ||||||||
| 1 | 1170 | 1.9 | 15,171 | 24.1 | 46,635 | 74.1 | 62,976 | 93.50 |
| 2 | 143 | 3.9 | 958 | 25.9 | 2603 | 70.3 | 3704 | 5.50 |
| >2 | 53 | 7.8 | 230 | 34.0 | 393 | 58.1 | 676 | 1.00 |
| Vehicle Type | ||||||||
| Bicycle | 8 | 0.6 | 399 | 28.2 | 1006 | 71.2 | 1413 | 2.10 |
| PTW < 500 | 23 | 0.9 | 614 | 24.9 | 1833 | 74.2 | 2470 | 3.67 |
| PTW ≥ 500 | 32 | 4.7 | 206 | 30.2 | 445 | 65.2 | 683 | 1.01 |
| Car | 906 | 1.7 | 12,789 | 23.9 | 39,724 | 74.4 | 53,419 | 79.31 |
| Van | 92 | 2.3 | 1033 | 25.3 | 2960 | 72.5 | 4085 | 6.06 |
| Bus | 72 | 2.6 | 704 | 25.6 | 1976 | 71.8 | 2752 | 4.09 |
| Truck | 199 | 13.6 | 375 | 25.7 | 885 | 60.7 | 1459 | 2.17 |
| Other | 27 | 3.4 | 187 | 23.3 | 587 | 73.3 | 801 | 1.19 |
| Missing | 7 | 2.6 | 52 | 19.0 | 215 | 78.5 | 274 | 0.41 |
| Vehicle Towing and Articulation | ||||||||
| Articulated vehicle | 97 | 28.9 | 110 | 32.7 | 129 | 38.4 | 336 | 0.50 |
| No tow/articulation | 1252 | 1.9 | 15,989 | 24.4 | 48,280 | 73.7 | 65,521 | 97.28 |
| Other | 13 | 4.7 | 83 | 29.7 | 183 | 65.6 | 279 | 0.41 |
| Missing | 4 | 0.3 | 177 | 14.5 | 1039 | 85.2 | 1220 | 1.81 |
| Vehicle Maneuver | ||||||||
| Going ahead | 1060 | 2.7 | 10,717 | 26.9 | 28,032 | 70.4 | 39,809 | 59.10 |
| Turning left/right/U | 101 | 1.1 | 2127 | 23.6 | 6770 | 75.2 | 8998 | 13.36 |
| Moving off | 67 | 1.3 | 961 | 19.3 | 3943 | 79.3 | 4971 | 7.38 |
| Overtaking | 30 | 1.3 | 573 | 24.3 | 1755 | 74.4 | 2358 | 3.50 |
| Reversing | 61 | 1.2 | 964 | 19.1 | 4033 | 79.7 | 5058 | 7.51 |
| Other | 42 | 0.9 | 851 | 18.4 | 3738 | 80.7 | 4631 | 6.88 |
| Missing | 5 | 0.3 | 166 | 10.8 | 1360 | 88.8 | 1531 | 2.27 |
| Vehicle Location | ||||||||
| At junction | 620 | 1.8 | 8711 | 24.9 | 25,691 | 73.4 | 35,022 | 52.00 |
| Not at junction | 744 | 2.4 | 7533 | 24.2 | 22,895 | 73.4 | 31,172 | 46.28 |
| Missing | 2 | 0.2 | 115 | 9.9 | 1045 | 89.9 | 1162 | 1.73 |
| Variable | Fatal | Serious | Slight | Tot | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| Vehicle Skidding and Overturning | ||||||||
| No | 1222 | 1.9 | 15,508 | 24.3 | 47,089 | 73.8 | 63,819 | 94.75 |
| Yes | 141 | 7.6 | 654 | 35.4 | 1054 | 57.0 | 1849 | 2.75 |
| Missing | 3 | 0.2 | 197 | 11.7 | 1488 | 88.2 | 1688 | 2.51 |
| Vehicle’s First Point of Impact | ||||||||
| Back | 63 | 1.2 | 1031 | 19.4 | 4230 | 79.5 | 5324 | 7.90 |
| Front | 1041 | 2.7 | 9932 | 26.1 | 27,023 | 71.1 | 37,996 | 56.41 |
| Nearside/Offside | 219 | 1.1 | 4577 | 23.4 | 14,755 | 75.5 | 19,551 | 29.03 |
| No impact | 35 | 1.1 | 631 | 20.4 | 2431 | 78.5 | 3097 | 4.60 |
| Missing | 8 | 0.6 | 188 | 13.5 | 1192 | 85.9 | 1388 | 2.06 |
| Vehicle Engine (CC) | ||||||||
| <1000 | 100 | 2.1 | 1271 | 27.0 | 3336 | 70.9 | 4707 | 6.99 |
| 1000–1500 | 236 | 1.8 | 3426 | 25.7 | 9692 | 72.6 | 13,354 | 19.83 |
| 1500–2000 | 417 | 1.9 | 5456 | 25.3 | 15,675 | 72.7 | 21,548 | 31.99 |
| 2000–3000 | 155 | 2.5 | 1594 | 25.8 | 4435 | 71.7 | 6184 | 9.18 |
| >3000 | 233 | 6.9 | 932 | 27.7 | 2204 | 65.4 | 3369 | 5.00 |
| Missing | 225 | 1.2 | 3680 | 20.2 | 14,289 | 78.5 | 18,194 | 27.01 |
| Vehicle Propulsion Code | ||||||||
| Heavy oil | 650 | 2.9 | 5869 | 26.2 | 15,886 | 70.9 | 22,405 | 33.26 |
| Hybrid electric | 14 | 1.0 | 258 | 17.7 | 1184 | 81.3 | 1456 | 2.16 |
| Petrol | 479 | 1.9 | 6537 | 25.9 | 18,244 | 72.2 | 25,260 | 37.50 |
| Other | 2 | 1.0 | 60 | 29.0 | 145 | 70.0 | 207 | 0.31 |
| Missing | 221 | 1.2 | 3635 | 20.2 | 14,172 | 78.6 | 18,028 | 26.77 |
| Vehicle Age | ||||||||
| ≤15 years | 1002 | 2.3 | 11,292 | 25.6 | 31,869 | 72.2 | 44,163 | 65.57 |
| >15 years | 79 | 2.6 | 853 | 28.3 | 2079 | 69.0 | 3011 | 4.47 |
| Missing | 285 | 1.4 | 4214 | 20.9 | 15,683 | 77.7 | 20,182 | 29.96 |
| Variable | Fatal | Serious | Slight | Tot | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| Driver Journey Purpose | ||||||||
| Commuting to/from work | 147 | 2.5 | 1759 | 30.1 | 3944 | 67.4 | 5850 | 8.69 |
| Journey as part of work | 399 | 3.4 | 3107 | 26.3 | 8299 | 70.3 | 11,805 | 17.53 |
| To/from school | 7 | 0.4 | 317 | 19.8 | 1277 | 79.8 | 1601 | 2.38 |
| Other | 108 | 2.6 | 1387 | 33.4 | 2653 | 64.0 | 4148 | 6.16 |
| Missing | 705 | 1.6 | 9789 | 22.3 | 33,458 | 76.1 | 43,952 | 65.25 |
| Driver Gender | ||||||||
| F | 217 | 1.3 | 3917 | 24.2 | 12,050 | 74.5 | 16,184 | 24.03 |
| M | 1079 | 2.7 | 10,503 | 26.2 | 28,529 | 71.1 | 40,111 | 59.55 |
| Missing | 70 | 0.6 | 1939 | 17.5 | 9052 | 81.8 | 11,061 | 16.42 |
| Driver Age | ||||||||
| ≤24 years | 194 | 2.8 | 2062 | 29.3 | 4776 | 67.9 | 7032 | 10.44 |
| 25–34 years | 284 | 2.3 | 3215 | 26.3 | 8718 | 71.4 | 12,217 | 18.14 |
| 35–44 years | 230 | 2.2 | 2627 | 25.2 | 7550 | 72.5 | 10,407 | 15.45 |
| 45–54 years | 242 | 2.4 | 2548 | 25.5 | 7191 | 72.0 | 9981 | 14.82 |
| 55–64 years | 187 | 2.7 | 1800 | 26.2 | 4887 | 71.1 | 6874 | 10.21 |
| 65–74 years | 95 | 2.5 | 987 | 26.0 | 2713 | 71.5 | 3795 | 5.63 |
| ≥75 years | 60 | 2.3 | 740 | 28.6 | 1785 | 69.1 | 2585 | 3.84 |
| Missing | 74 | 0.5 | 2380 | 16.5 | 12,011 | 83.0 | 14,465 | 21.48 |
| Driver IMD Decile | ||||||||
| Less deprived | 441 | 2.7 | 4432 | 27.0 | 11,570 | 70.4 | 16,443 | 24.41 |
| More deprived | 542 | 2.2 | 6652 | 26.4 | 17,959 | 71.4 | 25,153 | 37.34 |
| Missing | 383 | 1.5 | 5275 | 20.5 | 20,102 | 78.0 | 25,760 | 38.24 |
| Driver Home Area | ||||||||
| Rural | 126 | 3.6 | 995 | 28.6 | 2357 | 67.8 | 3478 | 5.16 |
| Small town | 108 | 3.4 | 922 | 29.4 | 2109 | 67.2 | 3139 | 4.66 |
| Urban | 899 | 2.3 | 10,462 | 26.3 | 28,415 | 71.4 | 39,776 | 59.05 |
| Missing | 233 | 1.1 | 3980 | 19.0 | 16,750 | 79.9 | 20,963 | 31.12 |
| Variable | Fatal | Serious | Slight | Tot | ||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | |
| Number of pedestrians involved | ||||||||
| 1 | 1,28 | 2.0 | 15,691 | 24.0 | 48,301 | 74.0 | 65,272 | 96.91 |
| 2 | 66 | 3.6 | 572 | 30.8 | 1220 | 65.7 | 1858 | 2.76 |
| >2 | 20 | 8.8 | 96 | 42.5 | 110 | 48.7 | 226 | 0.34 |
| Pedestrian gender | ||||||||
| F | 458 | 1.6 | 6864 | 23.2 | 22,216 | 75.2 | 29,538 | 43.85 |
| M | 908 | 2.4 | 9494 | 25.1 | 27,406 | 72.5 | 37,808 | 56.13 |
| Missing | 0 | 0.0 | 1 | 10.0 | 9 | 90.0 | 10 | 0.01 |
| Pedestrian age | ||||||||
| 0–14 years | 67 | 0.4 | 3442 | 22.9 | 11,516 | 76.6 | 15,025 | 22.31 |
| 15–24 years | 148 | 1.3 | 2505 | 21.5 | 9002 | 77.2 | 11,655 | 17.30 |
| 25–34 years | 160 | 1.6 | 2049 | 20.9 | 7593 | 77.5 | 9802 | 14.55 |
| 35–44 years | 155 | 2.1 | 1578 | 21.1 | 5732 | 76.8 | 7465 | 11.08 |
| 45–54 years | 153 | 2.1 | 1694 | 23.7 | 5306 | 74.2 | 7153 | 10.62 |
| 55–64 years | 151 | 2.7 | 1551 | 27.6 | 3919 | 69.7 | 5621 | 8.35 |
| 65–74 years | 152 | 3.4 | 1494 | 33.4 | 2826 | 63.2 | 4472 | 6.64 |
| ≥75 years | 379 | 7.5 | 1897 | 37.3 | 2803 | 55.2 | 5079 | 7.54 |
| Missing | 1 | 0.1 | 149 | 13.7 | 934 | 86.2 | 1084 | 1.61 |
| Pedestrian location | ||||||||
| Crossing elsewhere within 50 m of pedestrian crossing | 118 | 2.1 | 1511 | 27.5 | 3866 | 70.4 | 5495 | 8.16 |
| Crossing on pedestrian crossing facility | 182 | 1.7 | 2518 | 24.1 | 7727 | 74.1 | 10,427 | 15.48 |
| In carriageway, crossing elsewhere | 516 | 1.8 | 7500 | 25.9 | 20,968 | 72.3 | 28,984 | 43.03 |
| In carriageway, not crossing | 220 | 3.2 | 1449 | 20.9 | 5272 | 76.0 | 6941 | 10.30 |
| In center of carriageway | 90 | 3.1 | 769 | 26.6 | 2034 | 70.3 | 2893 | 4.30 |
| On footway or verge | 125 | 1.8 | 1398 | 20.7 | 5238 | 77.5 | 6761 | 10.04 |
| Missing | 115 | 2.0 | 1214 | 20.7 | 4526 | 77.3 | 5855 | 8.69 |
| Pedestrian movement | ||||||||
| Crossing from driver’s nearside | 440 | 2.0 | 5742 | 25.5 | 16,367 | 72.6 | 22,549 | 33.48 |
| Crossing from driver’s offside | 315 | 2.3 | 3717 | 26.8 | 9863 | 71.0 | 13,895 | 20.63 |
| Crossing from nearside, masked by parked or stationary vehicle | 19 | 0.4 | 1199 | 26.3 | 3344 | 73.3 | 4562 | 6.77 |
| Crossing from offside, masked by parked or stationary vehicle | 30 | 1.0 | 839 | 27.1 | 2222 | 71.9 | 3091 | 4.59 |
| In carriageway, stationary—not crossing (standing or playing) | 69 | 2.1 | 598 | 18.5 | 2565 | 79.4 | 3232 | 4.80 |
| In carriageway, stationary—not crossing—masked by parked or stationary vehicle | 8 | 1.5 | 112 | 21.6 | 399 | 76.9 | 519 | 0.77 |
| Walking along in carriageway, back to traffic | 64 | 4.3 | 329 | 21.9 | 1109 | 73.8 | 1502 | 2.23 |
| Walking along in carriageway, facing traffic | 40 | 4.2 | 200 | 21.0 | 711 | 74.8 | 951 | 1.41 |
| Missing | 381 | 2.2 | 3623 | 21.2 | 13,051 | 76.5 | 17,055 | 25.32 |
| Pedestrian IMD decile | ||||||||
| Less deprived | 412 | 2.4 | 4207 | 24.8 | 12,311 | 72.7 | 16,930 | 25.14 |
| More deprived | 541 | 1.6 | 7999 | 24.1 | 24,713 | 74.3 | 33,253 | 49.37 |
| Missing | 413 | 2.4 | 4153 | 24.2 | 12,607 | 73.4 | 17,173 | 25.50 |
| Parametric/Non-Parametric Models. | Only Parametric Models | Only Non-Parametric Models |
|---|---|---|
| First road class | Pedestrian-crossing human control | Driver home area |
| Area | Driver journey purpose | |
| Day of week | Vehicle’s first point of impact | |
| Driver age | Vehicle engine capacity (CC) | |
| Driver gender | Weather | |
| Lighting | Junction control | |
| Number of vehicles | ||
| Pavement | ||
| Pedestrian age | ||
| Pedestrian-crossing physical facilities | ||
| Pedestrian gender | ||
| Speed limit | ||
| Vehicle age | ||
| Vehicle maneuver | ||
| Vehicle propulsion code | ||
| Vehicle skidding and overturning | ||
| Vehicle towing and articulation | ||
| Vehicle type | ||
| Junction detail | ||
| Parametric/Non-Parametric Models | Only Parametric Models | Only Non-Parametric Models |
|---|---|---|
| First road class | Pedestrian-crossing human control | Driver home area |
| Area | Driver journey purpose | |
| Day of week | Number of pedestrians involved | |
| Driver age | Vehicle’s first point of impact | |
| Driver gender | Vehicle engine capacity (CC) | |
| Lighting | Weather | |
| Number of vehicles | Junction control | |
| Pavement | ||
| Pedestrian age | ||
| Pedestrian-crossing physical facilities | ||
| Pedestrian gender | ||
| Speed limit | ||
| Vehicle age | ||
| Vehicle maneuver | ||
| Vehicle skidding and overturning | ||
| Vehicle towing and articulation | ||
| Vehicle type | ||
| Junction detail | ||
References
- European Commission. EU Road Safety Policy Framework 2021–2030-Next Steps towards “Vision Zero”. 2019. Available online: https://ec.europa.eu/transport/sites/transport/files/legislation/swd20190283-roadsafety-vision-zero.pdf (accessed on 15 September 2020).
- Department for Transport. Road Accidents and Safety Statistics. 2020. Available online: https://www.gov.uk/government/collections/road-accidents-and-safety-statistics (accessed on 30 September 2020).
- Theofilatos, A.; Yannis, G. A review of powered-two-wheeler behaviour and safety. Int. J. Inj. Control. Saf. Promot. 2015, 22, 284–307. [Google Scholar] [CrossRef] [PubMed]
- Montella, A.; Andreassen, D.; Tarko, A.; Turner, S.; Mauriello, F.; Imbriani, L.L.; Romero, M. Crash databases in Australasia, the European Union, and the United States. Trans. Res. Rec. 2013, 2386, 128–136. [Google Scholar] [CrossRef]
- Cerwick, D.M.; Gkritza, K.; Shaheed, M.S.; Hans, Z. A comparison of the mixed logit and latent class methods for crash severity analysis. Anal. Methods Accid. Res. 2014, 3, 11–27. [Google Scholar] [CrossRef]
- Haleem, K.; Alluri, P.; Gan, A. Analyzing pedestrian crash injury severity at signalized and non-signalized locations. Accid. Anal. Prev. 2015, 81, 14–23. [Google Scholar] [CrossRef]
- Uddin, M.; Huynh, N. Factors influencing injury severity of crashes involving HAZMAT trucks. Int. J. Transp. Sci. Technol. 2018, 7, 1–9. [Google Scholar] [CrossRef]
- Tay, R.; Choi, J.; Kattan, L.; Khan, A. A Multinomial Logit Model of Pedestrian–Vehicle Crash Severity. Int. J. Sustain. Transp. 2011, 5, 233–249. [Google Scholar] [CrossRef]
- Rothman, L.; Howard, A.W.; Camden, A.; Macarthur, C. Pedestrian crossing location influences injury severity in urban areas. Inj. Prev. 2012, 18, 365–370. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.D. A multinomial logit model of pedestrian-vehicle crash severity in North Carolina. Int. J. Transp. Sci. Technol. 2019, 8, 43–52. [Google Scholar] [CrossRef]
- Mannering, F.L.; Shankar, V.; Bhat, C.R. Unobserved heterogeneity and the statistical analysis of highway accident data. Anal. Methods Accid. Res. 2016, 11, 1–16. [Google Scholar] [CrossRef]
- Savolainen, P.; Mannering, F.; Lord, D.; Quddus, M. The statistical analysis of highway crash-injury severities: A review and assessment of methodological alternatives. Accid. Anal. Prev. 2011, 43, 1666–1676. [Google Scholar] [CrossRef] [Green Version]
- Mannering, F.L.; Bhat, C.R.; Shankar, V.; Abdel-Aty, M. Big data, traditional data and the tradeoffs between prediction and causality in highway-safety analysis. Anal. Methods Accid. Res. 2020, 25, 100113. [Google Scholar] [CrossRef]
- Washington, S.P.; Karlaftis, M.G.; Mannering, F.L. Statistical and Econometric Methods for Transportation Data Analysis, 3rd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Milton, J. Highway accident severities and the mixed logit model: An exploratory empirical analysis. Accid. Anal. Prev. 2006, 40, 260–266. [Google Scholar] [CrossRef] [PubMed]
- Yasmin, S.; Eluru, N. Evaluating alternate discrete outcome frameworks for modeling crash injury severity. Accid. Anal. Prev. 2014, 59, 506–521. [Google Scholar] [CrossRef] [PubMed]
- Yamamoto, T.; Hashiji, J.; Shankar, N. Underreporting in traffic accident data, bias in parameters and the structure of injury severity models. Accid. Anal. Prev. 2008, 40, 1320–1329. [Google Scholar] [CrossRef] [PubMed]
- Abay, K.A. Examining pedestrian-injury severity using alternative disaggregate models. Res. Transp. Econ. 2013, 43, 123–136. [Google Scholar] [CrossRef]
- Eluru, N.; Bhat, C.R.; Hensher, D.A. A mixed generalized ordered response model for examining pedestrian and bicyclist injury severity level in traffic crashes. Accid. Anal. Prev. 2008, 40, 1033–1054. [Google Scholar] [CrossRef] [Green Version]
- Paleti, R.; Eluru, N.; Bhat, C.R. Examining the influence of aggressive driving behavior on driver injury severity in traffic crashes. Accid. Anal. Prev. 2010, 42, 1839–1854. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, K.K. Injury Severity Analysis with Variable and Correlated Thresholds: Ordered Mixed Logit Formulation. Trans. Res. Rec. 2002, 1784, 132–142. [Google Scholar] [CrossRef]
- Das, S.; Dutta, A.; Dixon, K.; Sun, X.; Jalayer, M. Supervised association rules mining on pedestrian crashes in urban areas: Identifying patterns for appropriate countermeasures. Int. J. Urban Sci. 2018, 23, 30–48. [Google Scholar] [CrossRef]
- Das, S.; Tamakloe, R.; Zubaidi, H.; Obaid, I. Fatal pedestrian crashes at intersections: Trend mining using association rules. Accid. Anal. Prev. 2021, 160, 106306. [Google Scholar] [CrossRef]
- Montella, A.; Aria, M.; D’Ambrosio, A.; Mauriello, F. Data-Mining Techniques for Exploratory Analysis of Pedestrian Crashes. Trans. Res. Rec. 2011, 2237, 107–116. [Google Scholar] [CrossRef]
- Montella, A.; de Oña, R.; Mauriello, F.; Rella Riccardi, M.; Silvestro, G. A data mining approach to investigate patterns of powered two-wheeler crashes in Spain. Accid. Anal. Prev. 2020, 134, 105251. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Ranjitkar, P.; Zhao, Y.; Yi, H.; Rashidi, S. Analyzing pedestrian crash injury severity under different weather conditions. Traffic Inj. Prev. 2017, 18, 427–430. [Google Scholar] [CrossRef] [PubMed]
- Mafi, S.; AbdelRazing, Y.; Doczy, R. Machine Learning Methods to Analyze Injury Severity of Drivers from Different Age and Gender Groups. Trans. Res. Rec. 2018, 2672, 171–183. [Google Scholar] [CrossRef]
- Mokhtarimousavi, S.; Anderson, J.C.; Azizinamini, A.; Hadi, M. Factors affecting injury severity in vehicle-pedestrian crashes: A day-of-week analysis using random parameter ordered response models and Artificial Neural Networks. Int. J. Transp. Sci. Technol. 2020, 9, 100–115. [Google Scholar] [CrossRef]
- Ni, Y.; Wang, M.; Sun, J.; Li, K. Evaluation of pedestrian safety at intersections: A theoretical framework based on pedestrian-vehicle interaction patterns. Accid. Anal. Prev. 2016, 96, 118–129. [Google Scholar] [CrossRef]
- King, G.; Zeng, L. Logistic regression in rare events data. Political Anal. 2001, 9, 137–163. [Google Scholar] [CrossRef] [Green Version]
- Ndour, C.; Diop, A.; Dossou-Gbété, S. Classification Approach Based on Association Rules Mining for Unbalanced Data. arXiv 2012, arXiv:1202.5514. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the Class Imbalance Problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 4, pp. 192–201. [Google Scholar] [CrossRef]
- Sáez, J.A.; Luengo, J.; Stefanowski, J.; Herrera, F. SMOTE–IPF: Addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering. Inf. Sci. 2015, 291, 184–203. [Google Scholar] [CrossRef]
- Tinessa, F.; Papola, A.; Marzano, V. The importance of choosing appropriate random utility models in complex choice contexts. In Proceedings of the 2017 Fifth International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017; pp. 884–888. [Google Scholar] [CrossRef]
- Agresti, A. Categorical Data Analysis, 3rd ed.; John Wiley & Sons: New York, NY, USA, 2002; ISBN 978-0-470-46363-5. [Google Scholar]
- Jobson, J. Applied Multivariate Data Analysis: Volume II: Categorical and Multivariate Methods; Springer: New York, NY, USA, 2012; ISBN 978-0-387-97804-8. [Google Scholar] [CrossRef]
- Seraneeprakarn, P.; Huang, S.; Shankar, V.; Mannering, F.; Venkataraman, N.; Milton, J. Occupant injury severities in hybrid-vehicle involved crashes: A random parameters approach with heterogeneity in means and variances. Anal. Methods Accid. Res. 2017, 15, 41–55. [Google Scholar] [CrossRef]
- McFadden, D. Structural Analysis of Discrete Data with Econometric Applications; The MIT Press: Cambridge, MA, USA, 1981; ISBN 9780262131599. [Google Scholar]
- Train, K. Discrete Choice Methods with Simulation, 2nd ed.; Cambridge University Press: New York, NY, USA, 2009; ISBN 978-0-521-76655-5. [Google Scholar]
- Long, J.S. Regression Models for Categorical and Limited Dependent Variables; SAGE Publications: Thousand Oaks, CA, USA, 1997; ISBN 0803973748. [Google Scholar]
- Greene, W.H.; Hensher, D.A. Modeling Ordered Choices; Cambridge University Press: New York, NY, USA, 2010; ISBN 9780511845062. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; Association for Computing Machinery: New York, NY, USA, 1993; pp. 207–216. [Google Scholar] [CrossRef]
- López, G.; Abellán, J.; Montella, A.; de Oña, J. Patterns of Single-Vehicle Crashes on Two-Lane Rural Highways in Granada Province, Spain: In-Depth Analysis through Decision Rules. Transp. Res. Rec. 2014, 2432, 133–141. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- de Villiers, J.; Barnard, E. Backpropagation neural nets with one and two hidden layers. IEEE Trans. Neural Netw. 1993, 4, 136–141. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Q.; Huang, H.; Pei, X.; Wong, S.C.; Gao, M. Rule extraction from an optimized neural network for traffic crash frequency modelling. Accid. Anal. Prev. 2016, 97, 87–95. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Assi, K.; Rahaman, S.M.; Monsoor, U.; Rtrout, N. Predicting Crash Injury Severity with Machine Learning Algorithm Synergized with Clustering Technique: A Promising Protocol. Int. J. Environ. Res. Public Health 2020, 17, 5497. [Google Scholar] [CrossRef]
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2012, 28, 92–122. [Google Scholar] [CrossRef]
- Oh, S.H. Error back-propagation algorithm for classification of imbalanced data. Neurocomputing 2011, 74, 1058–1061. [Google Scholar] [CrossRef]
- Huang, W.; Song, G.; Li, M.; Hu, W.; Xie, K. Adaptive Weight Optimization for Classification of Imbalanced Data. In IScIDE 2013, Intelligence Science and Big Data Engineering, Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Beijing, China, 31 July–2 August 2013; Lecture Notes in Computer Science; Sun, C., Fang, F., Zhou, Z.H., Yang, W., Liu, Z.Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8261. [Google Scholar] [CrossRef]
- Kamaldeep, S. How to Improve Class Imbalance Using Class Weights in Machine Learning. 2020. Available online: https://www.analyticsvidhya.com/blog/author/procrastinator/ (accessed on 15 September 2020).
- Damju, J.S.; Wening, B.; Das, T.; Lee, D. Learning Spark: Lightning-Fast Big Data Analytics, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2020; Available online: https://pages.databricks.com/rs/094-YMS-629/images/LearningSpark2.0.pdf. (accessed on 11 October 2020).
- Fernandez, A.; Garcìa, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: New York, NY, USA, 2018; ISBN 978-3-319-98073-7. [Google Scholar] [CrossRef]
- Kashani, A.; Rabieyan, R.; Besharati, M. A data mining approach to investigate the factors influencing the crash severity of motorcycle pillion passengers. J. Saf. Res. 2014, 51, 93–98. [Google Scholar] [CrossRef]
- Bina, B.; Schulte, O.; Crawford, B.; Qian, Z.; Xiong, Y. Simple decision forests for multi-relational classification. Decis. Support Syst. 2013, 54, 1269–1279. [Google Scholar] [CrossRef] [Green Version]
- Ye, F.; Lord, D. Investigating the Effects of Underreporting of Crash Data on Three Commonly Used Traffic Crash Severity Models: Multinomial Logit, Ordered Probit and Mixed Logit Models. Transp. Res. Rec. 2011, 2241, 51–58. [Google Scholar] [CrossRef]
- Kim, J.K.; Ulfarsson, G.F.; Sarkar, V.N.; Mannering, F.L. A note on modeling pedestrian-injury severity in motor-vehicle crashes with the mixed logit model. Accid. Anal. Prev. 2010, 42, 1751–1758. [Google Scholar] [CrossRef] [PubMed]
- Moral-Garcia, S.; Castellano, J.G.; Mantas, J.G.; Montella, A.; Abellan, J. Decision tree ensemble method for analyzing traffic accidents of novice drivers in urban areas. Entropy 2019, 21, 360. [Google Scholar] [CrossRef] [Green Version]
- Montella, A.; Mauriello, F.; Pernetti, M.; Rella Riccardi, M. Rule discovery to identify patterns contributing to overrepresentation and severity of run-off-the-road crashes. Accid. Anal. Prev. 2021, 155, 106119. [Google Scholar] [CrossRef]
- Noh, Y.; Kim, M.; Yoon, Y. Elderly pedestrian safety in a rapidly aging society—Commonality and diversity between the younger-old and older-old. Traffic Inj. Prev. 2019, 19, 874–879. [Google Scholar] [CrossRef]
- Babić, D.; Babić, D.; Fiolić, M.; Ferko, M. Factors affecting pedestrian conspicuity at night: Analysis based on driver eye tracking. Saf. Sci. 2021, 139, 105257. [Google Scholar] [CrossRef]
- Fekety, D.K.; Edewaard, D.E.; Stafford Sewall, A.A.; Tyrrell, R.A. Electroluminescent Materials Can Further Enhance the Nighttime Conspicuity of Pedestrians Wearing Retroreflective Materials. Hum. Factors 2016, 58, 976–985. [Google Scholar] [CrossRef]
- Wood, J.M.; Tyrrell, R.A.; Lacherez, P.; Black, A.A. Night-time Pedestrian Conspicuity: Effects of Clothing on Drivers’ Eye Movements. Ophthalmic Physiol. Opt. 2017, 37, 184–190. [Google Scholar] [CrossRef]







| Issue | References |
|---|---|
| The MNL is the most widely used model to investigate the crash contributory factors. | [8,9,10] |
| The MNL limits the effect of each attribute so that they are the same across all observations. | [11,12] |
| Random parameter models overcome the limits of the fixed formulation of the MNL. | [13,14,15] |
| Multinomial parametric models do not consider the ordered nature of the crash severity. | [16,17] |
| Standard ordered models impose a monotonic effect of the independent variables on all the injury severity levels. | [18,20] |
| Random parameter models overcome the limits of the fixed formulations of the standard unordered and ordered models. | [11,12,13,14,15,21] |
| All parametric models require a priori assumptions. | [14] |
| Non-parametric models do not require a priori assumptions and they handle large amounts of data. | [13] |
| Limited prediction abilities of both parametric and non-parametric models in the presence of imbalanced data. | [30,31] |
| Variable | Fatal | Serious | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | OR | Std. Err. | P > |z| | Estimate | OR | Std. Err. | P > |z| | |
| Intercept | −5.215 | 0.005 | 0.129 | <0.001 | −1.529 | 0.217 | 0.031 | <0.001 |
| Number of vehicles (“1 vehicle” as baseline) | ||||||||
| 2 | 0.682 | 1.978 | 0.106 | <0.001 | 0.183 | 1.201 | 0.042 | <0.001 |
| ≥3 | 1.170 | 3.222 | 0.187 | <0.001 | 0.498 | 1.645 | 0.091 | <0.001 |
| First Road class (“C” as baseline) | ||||||||
| B | 0.091 | 1.095 | 0.031 | 0.004 | ||||
| A | 0.558 | 1.747 | 0.067 | <0.001 | 0.095 | 1.100 | 0.022 | <0.001 |
| Motorway | 0.979 | 2.662 | 0.263 | <0.001 | 0.484 | 1.623 | 0.230 | 0.035 |
| Speed limit (“20 mph” as baseline) | ||||||||
| 30 mph | 0.382 | 1.465 | 0.125 | 0.002 | 0.073 | 1.076 | 0.037 | 0.044 |
| 40 mph | 1.384 | 3.991 | 0.163 | <0.001 | 0.565 | 1.759 | 0.057 | <0.001 |
| ≥50 mph | 2.227 | 9.272 | 0.164 | <0.001 | 0.638 | 1.893 | 0.064 | <0.001 |
| Area (“Urban” as baseline) | ||||||||
| Rural | 0.347 | 1.415 | 0.086 | <0.001 | ||||
| Junction detail (“T or staggered junction” as baseline) | ||||||||
| Not at junction | −0.034 | 0.967 | 0.015 | 0.021 | ||||
| Roundabout | −0.353 | 0.703 | 0.187 | 0.059 | −0.082 | 0.921 | 0.048 | 0.091 |
| Pedestrian-crossing human control (“None within 50 m” as baseline) | ||||||||
| School-crossing patrol | −0.204 | 0.815 | 0.120 | 0.089 | ||||
| Pedestrian-crossing physical facilities (“None within 50 m” as baseline) | ||||||||
| Zebra | −0.743 | 0.476 | 0.169 | <0.001 | −0.212 | 0.809 | 0.037 | <0.001 |
| Pelican | 0.254 | 1.289 | 0.094 | 0.007 | 0.114 | 1.121 | 0.033 | 0.001 |
| Lighting (“Daylight” as baseline) | ||||||||
| Darkness | 1.090 | 2.974 | 0.066 | <0.001 | 0.290 | 1.336 | 0.022 | <0.001 |
| Pavement (“Dry” as baseline) | ||||||||
| Wet or damp | 0.142 | 1.153 | 0.078 | 0.069 | 0.049 | 1.050 | 0.027 | 0.075 |
| Snow | −0.877 | 0.416 | 0.306 | 0.004 | ||||
| Day of week (“Weekday” as baseline) | ||||||||
| Weekend | 0.356 | 1.428 | 0.066 | <0.001 | 0.126 | 1.134 | 0.023 | <0.001 |
| Vehicle maneuver (“Moving off” as baseline) | ||||||||
| Going ahead | 1.126 | 3.083 | 0.073 | <0.001 | 0.505 | 1.657 | 0.026 | <0.001 |
| Turning maneuver | 0.140 | 1.150 | 0.035 | <0.001 | ||||
| Reversing maneuver | −0.152 | 0.859 | 0.044 | 0.001 | ||||
| Vehicle skidding and overturning (“No” as baseline) | ||||||||
| Yes | 1.165 | 3.206 | 0.117 | <0.001 | 0.480 | 1.616 | 0.056 | <0.001 |
| Vehicle type (“Car” as baseline) | ||||||||
| Bicycle | −1.290 | 0.275 | 0.366 | <0.001 | 0.141 | 1.151 | 0.064 | 0.028 |
| Bus | 0.710 | 2.034 | 0.164 | <0.001 | ||||
| PTW < 500 | −1.122 | 0.326 | 0.224 | <0.001 | −0.103 | 0.902 | 0.051 | 0.044 |
| Truck | 1.515 | 4.549 | 0.124 | <0.001 | ||||
| Vehicle towing and articulation (“No towing/articulation” as baseline) | ||||||||
| Articulated vehicle | 1.228 | 3.414 | 0.221 | <0.001 | 0.855 | 2.351 | 0.141 | <0.001 |
| Vehicle propulsion code (“Petrol” as baseline) | ||||||||
| Heavy oil vehicles | 0.284 | 1.328 | 0.072 | <0.001 | 0.170 | 1.185 | 0.033 | <0.001 |
| Hybrid vehicles | −0.466 | 0.628 | 0.283 | 0.100 | −0.289 | 0.749 | 0.062 | <0.001 |
| Vehicle age (“≤15 years” as baseline) | ||||||||
| >15 years | 0.327 | 1.387 | 0.128 | 0.011 | 0.213 | 1.237 | 0.043 | <0.001 |
| Driver gender (“Male” as baseline) | ||||||||
| Female | −0.293 | 0.746 | 0.078 | <0.001 | ||||
| Driver age (“35–44 years” as baseline) | ||||||||
| ≤24 years | 0.596 | 1.815 | 0.091 | <0.001 | 0.272 | 1.313 | 0.030 | <0.001 |
| 25–34 years | 0.293 | 1.340 | 0.076 | <0.001 | 0.145 | 1.156 | 0.024 | <0.001 |
| Pedestrian gender (“Male” as baseline) | ||||||||
| Female | −0.155 | 0.856 | 0.064 | 0.015 | −0.072 | 0.931 | 0.019 | <0.001 |
| Pedestrian age (“35–44 years” as baseline) | ||||||||
| 0–14 years | −0.837 | 0.433 | 0.137 | <0.001 | ||||
| 15–24 years | −0.534 | 0.586 | 0.105 | <0.001 | ||||
| 25–34 years | −0.303 | 0.739 | 0.103 | 0.003 | ||||
| 45–54 years | 0.154 | 1.166 | 0.031 | <0.001 | ||||
| 55–64 years | 0.633 | 1.883 | 0.110 | <0.001 | 0.417 | 1.517 | 0.033 | <0.001 |
| 65–74 years | 1.295 | 3.651 | 0.111 | <0.001 | 0.770 | 2.160 | 0.035 | <0.001 |
| ≥75 years | 2.578 | 13.171 | 0.092 | <0.001 | 1.111 | 3.037 | 0.034 | <0.001 |
| Log likelihood null model | −48,217.27 | |||||||
| Log likelihood full model | −40,469.52 | |||||||
| R2McFadden | 0.161 | |||||||
| AIC | 81,079.04 | |||||||
| BIC | 81,717.28 | |||||||
| Variable | Fatal | Serious | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | OR | Std. Err. | P > |z| | Estimate | OR | Std. Err. | P > |z| | |
| Intercept | −5.364 | 0.005 | 0.196 | <0.001 | −1.041 | 0.353 | 0.043 | <0.001 |
| Number of vehicles (“1 vehicle” as baseline) | ||||||||
| 2 | 0.735 | 2.085 | 0.117 | <0.001 | 0.175 | 1.191 | 0.042 | <0.001 |
| ≥3 | 1.218 | 3.380 | 0.199 | <0.001 | 0.493 | 1.637 | 0.090 | <0.001 |
| First Road class (“C” as baseline) | ||||||||
| B | 0.108 | 1.114 | 0.032 | 0.001 | ||||
| A | 0.577 | 1.781 | 0.072 | <0.001 | 0.104 | 1.110 | 0.022 | <0.001 |
| Motorway | 1.043 | 2.838 | 0.284 | <0.001 | 0.448 | 1.565 | 0.215 | 0.037 |
| Speed limit (“20 mph” as baseline) | ||||||||
| 30 mph | 0.423 | 1.527 | 0.137 | 0.002 | 0.051 | 1.052 | 0.030 | 0.088 |
| 40 mph | 1.478 | 4.384 | 0.178 | <0.001 | 0.524 | 1.689 | 0.055 | <0.001 |
| ≥50 mph | 2.431 | 11.370 | 0.186 | <0.001 | 0.582 | 1.790 | 0.061 | <0.001 |
| Area (“Urban” as baseline) | ||||||||
| Rural | 0.377 | 1.458 | 0.096 | <0.001 | ||||
| Junction detail (“T or staggered junction” as baseline) | ||||||||
| Not at junction | −0.044 | 0.957 | 0.021 | 0.035 | ||||
| Roundabout | −2.477 | 0.084 | 0.966 | 0.010 | −0.107 | 0.899 | 0.059 | 0.069 |
| Pedestrian-crossing human control (“None within 50 m” as baseline) | ||||||||
| School-crossing patrol | −0.207 | 0.813 | 0.123 | 0.093 | ||||
| Pedestrian-crossing physical facilities (“None within 50 m” as baseline) | ||||||||
| Zebra | −0.781 | 0.458 | 0.188 | <0.001 | −0.231 | 0.794 | 0.039 | <0.001 |
| Pelican | 0.280 | 1.323 | 0.098 | 0.004 | 0.103 | 1.108 | 0.030 | 0.001 |
| Lighting (“Daylight” as baseline) | ||||||||
| Darkness | 1.164 | 3.203 | 0.076 | <0.001 | 0.289 | 1.335 | 0.022 | <0.001 |
| Pavement (“Dry” as baseline) | ||||||||
| Wet or damp | 0.153 | 1.165 | 0.075 | 0.041 | 0.040 | 1.041 | 0.023 | 0.078 |
| Snow | −1.045 | 0.352 | 0.359 | 0.004 | ||||
| Day of week (“Weekday” as baseline) | ||||||||
| Weekend | 0.373 | 1.452 | 0.074 | <0.001 | 0.123 | 1.131 | 0.023 | <0.001 |
| Vehicle maneuver (“Moving off” as baseline) | ||||||||
| Going ahead | 0.831 | 2.296 | 0.154 | <0.001 | 0.513 | 1.670 | 0.027 | <0.001 |
| Turning maneuver | 0.143 | 1.154 | 0.037 | <0.001 | ||||
| Reversing maneuver | −0.255 | 0.775 | 0.051 | <0.001 | ||||
| Vehicle skidding and overturning (“No” as baseline) | ||||||||
| Yes | 1.266 | 3.457 | 0.133 | <0.001 | 0.450 | 1.568 | 0.054 | <0.001 |
| Vehicle type (“Car” as baseline) | ||||||||
| Bicycle | −1.427 | 0.240 | 0.403 | <0.001 | 0.223 | 1.250 | 0.067 | 0.001 |
| Bus | 0.634 | 1.885 | 0.147 | <0.001 | ||||
| PTW < 500 | −1.288 | 0.276 | 0.254 | <0.001 | −0.112 | 0.894 | 0.053 | 0.033 |
| Truck | 1.674 | 5.333 | 0.151 | <0.001 | ||||
| Vehicle towing and articulation (“No towing/articulation” as baseline) | ||||||||
| Articulated vehicle | 1.272 | 3.568 | 0.234 | <0.001 | 0.833 | 2.300 | 0.141 | <0.001 |
| Vehicle propulsion code (“Petrol” as baseline) | ||||||||
| Heavy oil vehicles | 0.284 | 1.328 | 0.072 | <0.001 | 0.170 | 1.185 | 0.033 | <0.001 |
| Hybrid vehicles | −0.466 | 0.628 | 0.283 | 0.100 | −0.289 | 0.749 | 0.062 | <0.001 |
| Vehicle age (“≤15 years” as baseline) | ||||||||
| >15 years | 0.317 | 1.373 | 0.086 | <0.001 | 0.153 | 1.165 | 0.023 | <0.001 |
| Driver gender (“Male” as baseline) | ||||||||
| Female | −0.343 | 0.710 | 0.092 | <0.001 | ||||
| Driver age (“35–44 years” as baseline) | ||||||||
| ≤24 years | 0.635 | 1.887 | 0.101 | <0.001 | 0.294 | 1.342 | 0.031 | <0.001 |
| 25–34 years | 0.336 | 1.399 | 0.084 | <0.001 | 0.152 | 1.164 | 0.025 | <0.001 |
| Pedestrian gender (“Male” as baseline) | ||||||||
| Female | −0.156 | 0.856 | 0.070 | 0.027 | −0.097 | 0.908 | 0.020 | <0.001 |
| Pedestrian age (“35–44 years” as baseline) | ||||||||
| 0–14 years | −0.884 | 0.413 | 0.148 | <0.001 | ||||
| 15–24 years | −0.592 | 0.553 | 0.116 | <0.001 | ||||
| 25–34 years | −0.342 | 0.710 | 0.114 | 0.003 | ||||
| 45–54 years | 0.157 | 1.170 | 0.031 | <0.001 | ||||
| 55–64 years | 0.668 | 1.950 | 0.118 | <0.001 | 0.426 | 1.531 | 0.033 | <0.001 |
| 65–74 years | 1.367 | 3.924 | 0.120 | <0.001 | 0.785 | 2.192 | 0.035 | <0.001 |
| ≥75 years | 2.279 | 9.767 | 0.223 | <0.001 | 0.297 | 1.346 | 0.179 | 0.097 |
| Standard deviation of random parameter | ||||||||
| Going-ahead vehicle maneuver | 0.997 | 2.710 | 0.195 | <0.001 | ||||
| Roundabout | 2.583 | 13.237 | 0.643 | <0.001 | ||||
| Pedestrian age ≥ 75 years | 3.853 | 47.134 | 1.036 | <0.001 | ||||
| Log likelihood null model | −48,217.21 | |||||||
| Log likelihood full model | −39,565.46 | |||||||
| R2McFadden | 0.179 | |||||||
| AIC | 79,274.93 | |||||||
| BIC | 79,931.41 | |||||||
| Variable | Estimate | OR | Std. Err. | P > |z| |
|---|---|---|---|---|
| Number of vehicles (“1 vehicle” as baseline) | ||||
| 2 | 0.262 | 1.300 | 0.039 | <0.001 |
| ≥3 | 0.613 | 1.846 | 0.083 | <0.001 |
| First road class (“C” as baseline) | ||||
| B | 0.108 | 1.114 | 0.030 | <0.001 |
| A | 0.172 | 1.188 | 0.021 | <0.001 |
| Motorway | 1.003 | 2.726 | 0.184 | <0.001 |
| Speed limit (“20 mph” as baseline) | ||||
| 30 mph | 0.076 | 1.079 | 0.029 | 0.008 |
| 40 mph | 0.615 | 1.850 | 0.051 | <0.001 |
| ≥50 mph | 1.079 | 2.942 | 0.056 | <0.001 |
| Junction detail (“T or staggered junction” as baseline) | ||||
| Not at junction | −0.046 | 0.955 | 0.020 | 0.021 |
| Roundabout | −0.099 | 0.906 | 0.055 | 0.071 |
| Pedestrian-crossing human control (“None within 50 m” as baseline) | ||||
| School-crossing patrol | −0.244 | 0.783 | 0.120 | 0.042 |
| Pedestrian-crossing physical facilities (“None within 50 m” as baseline) | ||||
| Zebra | −0.226 | 0.798 | 0.037 | <0.001 |
| Pelican | 0.103 | 1.108 | 0.028 | <0.001 |
| Lighting (“Daylight” as baseline) | ||||
| Darkness | 0.409 | 1.505 | 0.021 | <0.001 |
| Pavement (“Dry” as baseline) | ||||
| Wet or damp | 0.047 | 1.048 | 0.022 | 0.035 |
| Snow | −0.236 | 0.790 | 0.091 | 0.010 |
| Day of week (“Weekday” as baseline) | ||||
| Weekend | 0.150 | 1.162 | 0.022 | <0.001 |
| Vehicle maneuver (“Moving off” as baseline) | ||||
| Going ahead | 0.587 | 1.799 | 0.023 | <0.001 |
| Turning maneuver | 0.187 | 1.206 | 0.032 | <0.001 |
| Vehicle skidding and overturning (“No” as baseline) | ||||
| Yes | 0.607 | 1.835 | 0.051 | <0.001 |
| Vehicle type (“Car” as baseline) | ||||
| Bus | 0.184 | 1.202 | 0.046 | <0.001 |
| PTW < 500 | −0.158 | 0.854 | 0.051 | 0.002 |
| Truck | 0.462 | 1.587 | 0.066 | <0.001 |
| Vehicle towing and articulation (“No towing/articulation” as baseline) | ||||
| Yes | 1.260 | 3.525 | 0.129 | <0.001 |
| Vehicle propulsion code (“Petrol” as baseline) | ||||
| Heavy oil vehicles | 0.119 | 1.126 | 0.022 | <0.001 |
| Hybrid vehicles | −0.340 | 0.712 | 0.071 | <0.001 |
| Vehicle age (“≤15 years” as baseline) | ||||
| >15 years | 0.232 | 1.261 | 0.042 | <0.001 |
| Driver age (“35–44 years” as baseline) | ||||
| ≤24 years | 0.304 | 1.355 | 0.029 | <0.001 |
| 25–34 years | 0.155 | 1.168 | 0.024 | <0.001 |
| Pedestrian gender (“Male” as baseline) | ||||
| Female | −0.080 | 0.923 | 0.019 | <0.001 |
| Pedestrian age (“35–44 years” as baseline) | ||||
| 0–14 years | −0.171 | 0.843 | 0.025 | <0.001 |
| 45–54 years | 0.233 | 1.262 | 0.031 | <0.001 |
| 55–64 years | 0.516 | 1.675 | 0.033 | <0.001 |
| 65–74 years | 0.895 | 2.447 | 0.035 | <0.001 |
| ≥75 years | 1.393 | 4.027 | 0.033 | <0.001 |
| Cut points | ||||
| Cut1 | 2.381 | 0.039 | ||
| Cut2 | 5.385 | 0.049 | ||
| Log likelihood null model | −48,217.27 | |||
| Log likelihood full model | −41,017.92 | |||
| R2McFadden | 0.149 | |||
| AIC | 82,101.85 | |||
| BIC | 82,402.74 | |||
| Variable | Estimate | OR | Std. Err. | P > |z| |
|---|---|---|---|---|
| Number of vehicles (“1 vehicle” as baseline) | ||||
| 2 | 0.195 | 1.215 | 0.039 | <0.001 |
| ≥3 | 0.571 | 1.770 | 0.083 | <0.001 |
| First road class (“C” as baseline) | ||||
| B | 0.110 | 1.116 | 0.030 | 0.001 |
| A | 0.150 | 1.162 | 0.021 | <0.001 |
| Motorway | 0.925 | 2.522 | 0.184 | <0.001 |
| Speed limit (“20 mph” as baseline) | ||||
| 30 mph | 0.090 | 1.094 | 0.029 | 0.002 |
| 40 mph | 0.627 | 1.872 | 0.052 | <0.001 |
| ≥50 mph | 1.029 | 2.798 | 0.061 | <0.001 |
| Junction detail (“T or staggered junction” as baseline) | ||||
| Not at junction | −0.057 | 0.945 | 0.020 | 0.004 |
| Roundabout | −0.133 | 0.875 | 0.056 | 0.017 |
| Pedestrian-crossing human control (“None within 50 m” as baseline) | ||||
| School-crossing patrol | −0.274 | 0.760 | 0.121 | 0.024 |
| Pedestrian-crossing physical facilities (“None within 50 m” as baseline) | ||||
| Zebra | −0.228 | 0.796 | 0.037 | <0.001 |
| Pelican | 0.122 | 1.130 | 0.028 | <0.001 |
| Lighting (“Daylight” as baseline) | ||||
| Darkness | 0.336 | 1.399 | 0.021 | <0.001 |
| Pavement (“Dry” as baseline) | ||||
| Wet or damp | 0.071 | 1.074 | 0.022 | 0.001 |
| Snow | −0.240 | 0.787 | 0.091 | 0.009 |
| Day of week (“Weekday” as baseline) | ||||
| Weekend | 0.133 | 1.142 | 0.022 | <0.001 |
| Vehicle maneuver (“Moving off” as baseline) | ||||
| Going ahead | 0.536 | 0.025 | <0.001 | |
| Turning maneuver | 0.203 | 0.035 | <0.001 | |
| Vehicle skidding and overturning (“No” as baseline) | ||||
| Yes | 0.593 | 1.809 | 0.051 | <0.001 |
| Vehicle type (“Car” as baseline) | ||||
| Bus | 0.142 | 1.153 | 0.046 | 0.002 |
| PTW < 500 | −0.149 | 0.862 | 0.051 | 0.004 |
| Truck | 0.424 | 1.528 | 0.066 | <0.001 |
| Vehicle towing and articulation (“No towing/articulation” as baseline) | ||||
| Yes | 1.299 | 3.666 | 0.129 | <0.001 |
| Vehicle propulsion code (“Petrol” as baseline) | ||||
| Heavy oil vehicles | 0.209 | 1.232 | 0.020 | <0.001 |
| Hybrid vehicles | −0.252 | 0.777 | 0.070 | <0.001 |
| Vehicle age (“≤15 years” as baseline) | ||||
| >15 years | 0.237 | 1.267 | 0.042 | <0.001 |
| Driver age (“35–44 years” as baseline) | ||||
| ≤24 years | 0.332 | 1.394 | 0.029 | <0.001 |
| 25–34 years | 0.171 | 1.186 | 0.023 | <0.001 |
| Pedestrian gender (“Male” as baseline) | ||||
| Female | −0.074 | 0.929 | 0.021 | <0.001 |
| Pedestrian age (“35–44 years” as baseline) | ||||
| 0–14 years | −0.391 | 0.676 | 0.032 | <0.001 |
| 45–54 years | 0.334 | 1.397 | 0.037 | <0.001 |
| 55–64 years | 0.602 | 1.826 | 0.039 | <0.001 |
| 65–74 years | 0.305 | 1.357 | 0.040 | <0.001 |
| ≥75 years | 1.000 | 2.718 | 0.036 | <0.001 |
| Standard deviation of random parameter | ||||
| Pedestrian age ≥ 75 years | 0.580 | 1.786 | 0.036 | <0.001 |
| Cut points | ||||
| Cut1 | 0.827 | 0.014 | ||
| Cut2 | 3.828 | 0.035 | ||
| Log likelihood null model | −48,217.27 | |||
| Log likelihood full model | −40,068.60 | |||
| R2McFadden | 0.169 | |||
| AIC | 80,209.10 | |||
| BIC | 80,537.34 | |||
| ID Rule | Antecedents | S% | C% | L | LIC | ||
|---|---|---|---|---|---|---|---|
| Item 1 | Item 2 | Item 3 | |||||
| 1 | Vehicle towing and articulation = Yes | 0.14 | 28.87 | 14.24 | n.a. | ||
| 2 | Lighting = Darkness—no lighting | 0.33 | 17.80 | 8.78 | n.a. | ||
| 3 | Lighting = Darkness—no lighting | Speed limit ≥ 50 mph | 0.29 | 30.06 | 14.82 | 1.69 | |
| 4 | Speed limit ≥ 50 mph | 0.51 | 16.74 | 8.25 | n.a. | ||
| 5 | Speed limit ≥ 50 mph | Day of week = Weekend | 0.16 | 18.41 | 9.08 | 1.10 | |
| 6 | Vehicle type = Truck | 0.30 | 13.64 | 6.73 | n.a. | ||
| 7 | Vehicle skidding and overturning = Yes | 0.21 | 7.63 | 3.76 | n.a. | ||
| 8 | Pedestrian age ≥ 75 years | 0.56 | 7.46 | 3.68 | n.a. | ||
| 9 | Pedestrian age ≥ 75 years | Lighting = Darkness—lights lit | 0.15 | 13.96 | 6.88 | 1.87 | |
| 10 | Pedestrian age ≥ 75 years | Lighting = Darkness—lights lit | Vehicle 1st point of impact = Front | 0.12 | 16.94 | 8.35 | 1.21 |
| 11 | Pedestrian age ≥ 75 years | Lighting = Darkness—lights lit | Driver home area = Urban | 0.11 | 14.72 | 7.26 | 1.05 |
| 12 | Pedestrian age ≥ 75 years | Lighting = Darkness—lights lit | Vehicle age ≥ 15 years | 0.11 | 14.68 | 7.24 | 1.05 |
| 13 | Pedestrian age ≥ 75 years | Vehicle Maneuver = Going ahead | 0.37 | 12.30 | 6.07 | 1.65 | |
| 14 | Pedestrian age ≥ 75 years | Vehicle Maneuver = Going ahead | Pavement = Wet or damp | 0.11 | 14.14 | 6.97 | 1.15 |
| 15 | Pedestrian age ≥ 75 years | Vehicle Maneuver = Going ahead | Vehicle propulsion = Petrol | 0.18 | 13.87 | 6.84 | 1.13 |
| 16 | Pedestrian age ≥ 75 years | Vehicle Maneuver = Going ahead | Junction detail = T or staggered | 0.12 | 13.42 | 6.62 | 1.09 |
| 17 | Pedestrian age ≥ 75 years | Vehicle 1st point of impact = Front | 0.40 | 10.41 | 5.13 | 1.40 | |
| 18 | Pedestrian age ≥ 75 years | Vehicle 1st point of impact = Front | Junction control = Not at junction or within 20 m | 0.18 | 13.16 | 6.49 | 1.26 |
| 19 | Pedestrian age ≥ 75 years | Vehicle 1st point of impact = Front | Vehicle propulsion = Heavy oil | 0.17 | 12.71 | 6.27 | 1.22 |
| 20 | Pedestrian age ≥ 75 years | Vehicle 1st point of impact = Front | Vehicle age ≥ 15 years | 0.30 | 11.18 | 5.51 | 1.07 |
| 21 | Pedestrian age ≥ 75 years | Day of week = Weekend | 0.14 | 9.76 | 4.81 | 1.31 | |
| 22 | Pedestrian age ≥ 75 years | Day of week = Weekend | Driver gender = M | 0.10 | 11.09 | 5.47 | 1.14 |
| 23 | Pedestrian age ≥ 75 years | Driver journey purpose = Journey as part of work | 0.16 | 9.70 | 4.79 | 1.30 | |
| 24 | Pedestrian age ≥ 75 years | Pavement = Wet or damp | 0.15 | 8.88 | 4.38 | 1.19 | |
| 25 | Pedestrian age ≥ 75 years | Vehicle Propulsion = Heavy oil | 0.25 | 8.82 | 4.35 | 1.18 | |
| 26 | Pedestrian age ≥ 75 years | Driver gender = M | 0.43 | 8.74 | 4.31 | 1.17 | |
| 27 | Pedestrian age ≥ 75 years | Pedestrian gender = M | 0.31 | 8.47 | 4.17 | 1.13 | |
| 28 | Pedestrian age ≥ 75 years | Driver age = 25–34 years | 0.11 | 8.10 | 3.99 | 1.09 | |
| 29 | Vehicle engine capacity (CC) = 3000+ | 0.35 | 6.89 | 3.40 | n.a. | ||
| 30 | Vehicle engine capacity (CC) = 3000+ | Speed limit ≥ 50 mph | 0.10 | 39.53 | 19.49 | 5.74 | |
| 31 | Vehicle engine capacity (CC) = 3000+ | Driver journey purpose = Journey as part of work | 0.31 | 8.17 | 4.03 | 1.19 | |
| 32 | Vehicle engine capacity (CC) = 3000+ | Driver gender = M | 0.33 | 7.33 | 3.61 | 1.06 | |
| 33 | Area = Rural | 0.68 | 5.71 | 2.82 | n.a. | ||
| 34 | Area = Rural | Number of vehicles = 2 | 0.10 | 10.15 | 5.00 | 1.78 | |
| 35 | Area = Rural | Day of week = Weekend | 0.22 | 8.04 | 3.96 | 1.41 | |
| ID Rule | Antecedents | S% | C% | L | LIC | ||
|---|---|---|---|---|---|---|---|
| Item 1 | Item 2 | Item 3 | |||||
| 36 | Number of pedestrians involved ≥ 2 | 0.14 | 42.48 | 1.75 | n.a. | ||
| 37 | Pedestrian age ≥ 75 years | 2.82 | 37.35 | 1.54 | n.a. | ||
| 38 | Pedestrian age ≥ 75 years | Vehicle age ≥ 15 years | 0.18 | 46.88 | 1.93 | 1.26 | |
| 39 | Pedestrian age ≥ 75 years | Driver journey purpose = Commuting to/from work | 0.26 | 44.53 | 1.83 | 1.19 | |
| 40 | Pedestrian age ≥ 75 years | Pavement = Wet or damp | 0.74 | 42.93 | 1.77 | 1.15 | |
| 41 | Pedestrian age ≥ 75 years | Driver age ≥ 75 years | 0.29 | 42.49 | 1.75 | 1.14 | |
| 42 | Pedestrian age ≥ 75 years | Driver home area = Small town | 0.22 | 42.30 | 1.74 | 1.13 | |
| 43 | Pedestrian age ≥ 75 years | Pedestrian-crossing physical facilities = Zebra | 0.20 | 41.77 | 1.72 | 1.12 | |
| 44 | Pedestrian age ≥ 75 years | Pedestrian-crossing physical facilities = Zebra | Driver gender = M | 0.15 | 46.70 | 1.92 | 1.12 |
| 45 | Pedestrian age ≥ 75 years | Vehicle type = Van | 0.27 | 40.77 | 1.68 | 1.09 | |
| 46 | Pedestrian age ≥ 75 years | Vehicle type = Van | Junction control = T or staggered | 0.11 | 48.10 | 1.98 | 1.18 |
| 47 | Pedestrian age ≥ 75 years | Vehicle type = Van | Junction control = Give way/uncontrolled | 0.15 | 45.02 | 1.85 | 1.10 |
| 48 | Pedestrian age ≥ 75 years | Vehicle propulsion code = Petrol | 1.23 | 40.68 | 1.67 | 1.09 | |
| 49 | Pedestrian age ≥ 75 years | Pedestrian gender = F | 1.58 | 40.54 | 1.67 | 1.09 | |
| 50 | Vehicle Skidding and Overturning = Yes | 0.97 | 35.37 | 1.46 | n.a. | ||
| 51 | Speed limit = 40 mph | 1.23 | 34.73 | 1.43 | n.a. | ||
| 52 | Speed limit = 40 mph | Day of week = Weekend | 0.32 | 39.63 | 1.63 | 1.14 | |
| 53 | Pedestrian age = 65–74 years | 2.22 | 33.41 | 1.38 | n.a. | ||
| 54 | Pedestrian age = 65–74 years | Driver journey purpose = Commuting to/from work | 0.21 | 42.22 | 1.74 | 1.26 | |
| 55 | Pedestrian age = 65–74 years | Driver age = 0–24 years | 0.27 | 39.57 | 1.63 | 1.18 | |
| 56 | Pedestrian age = 65–74 years | Driver age = 0–24 years | Vehicle age ≥ 15 years | 0.22 | 42.44 | 1.75 | 1.07 |
| 57 | Pedestrian age = 65–74 years | Pavement = Wet or damp | 0.63 | 37.63 | 1.55 | 1.13 | |
| 58 | Lighting = Darkness—no lighting | 0.61 | 33.20 | 1.37 | n.a. | ||
| 59 | Lighting = Darkness—no lighting | Speed limit ≥ 50 mph | 0.34 | 35.51 | 1.46 | 1.07 | |
| 60 | Weather = Raining + high winds | 0.31 | 31.09 | 1.28 | n.a. | ||
| 61 | Driver age = 0–24 years | 3.06 | 29.32 | 1.21 | n.a. | ||
| 62 | Driver age = 0–24 years | Speed limit ≥ 50 mph | 0.14 | 38.56 | 1.59 | 1.31 | |
| 63 | Driver age = 0–24 years | Speed limit ≥ 50 mph | Vehicle 1st point of impact = Front | 0.10 | 41.72 | 1.72 | 1.08 |
| 64 | Driver age = 0–24 years | Day of week = Weekend | 0.81 | 31.21 | 1.29 | 1.06 | |
| 65 | Lighting = Darkness—lights unlit | 0.22 | 29.32 | 1.21 | n.a. | ||
| Standard Parametric Models | Weighted Parametric Models | |||||||
|---|---|---|---|---|---|---|---|---|
| MNL | RPMNL | OL | RPOL | MNL | RPMNL | OL | RPOL | |
| Fatal | ||||||||
| F-measure | 0.16 | 0.23 | 0.00 | 0.02 | 0.28 | 0.53 | 0.00 | 0.16 |
| G-mean | 0.32 | 0.38 | 0.04 | 0.10 | 0.50 | 0.65 | 0.04 | 0.33 |
| AUC | 0.86 | 0.87 | 0.85 | 0.86 | 0.87 | 0.94 | 0.85 | 0.85 |
| Serious | ||||||||
| F-measure | 0.06 | 0.32 | 0.05 | 0.14 | 0.21 | 0.41 | 0.41 | 0.40 |
| G-mean | 0.17 | 0.46 | 0.17 | 0.28 | 0.36 | 0.58 | 0.43 | 0.58 |
| AUC | 0.62 | 0.63 | 0.61 | 0.63 | 0.62 | 0.68 | 0.61 | 0.62 |
| Averaged performances | ||||||||
| F-measure | 0.06 | 0.31 | 0.05 | 0.13 | 0.22 | 0.42 | 0.38 | 0.38 |
| G-mean | 0.18 | 0.45 | 0.16 | 0.27 | 0.37 | 0.59 | 0.40 | 0.56 |
| AUC | 0.64 | 0.65 | 0.63 | 0.64 | 0.64 | 0.70 | 0.63 | 0.63 |
| Standard Non-Parametric Algorithms | Weighted Non-Parametric Algorithms | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AR | CT | RF | ANN | SVM | AR | CT | RF | ANN | SVM | |
| Fatal | ||||||||||
| F-measure | 0.05 | 0.00 | 0.02 | 0.04 | 0.01 | 0.05 | 0.16 | 0.57 | 0.18 | 0.95 |
| G-mean | 0.36 | 0.00 | 0.09 | 0.15 | 0.07 | 0.36 | 0.72 | 0.77 | 0.66 | 0.96 |
| AUC | 0.79 | 0.80 | 0.23 | 0.83 | 0.76 | 0.79 | 0.82 | 0.88 | 0.78 | 0.88 |
| Serious | ||||||||||
| F-measure | 0.39 | 0.11 | 0.00 | 0.13 | 0.03 | 0.39 | 0.29 | 0.90 | 0.26 | 0.95 |
| G-mean | 0.54 | 0.24 | 0.04 | 0.27 | 0.12 | 0.54 | 0.46 | 0.92 | 0.43 | 0.96 |
| AUC | 0.58 | 0.61 | 0.56 | 0.61 | 0.55 | 0.58 | 0.47 | 0.71 | 0.76 | 0.76 |
| Averaged performances | ||||||||||
| F-measure | 0.36 | 0.10 | 0.00 | 0.12 | 0.02 | 0.36 | 0.28 | 0.87 | 0.25 | 0.95 |
| G-mean | 0.53 | 0.22 | 0.05 | 0.26 | 0.11 | 0.53 | 0.48 | 0.91 | 0.45 | 0.96 |
| AUC | 0.59 | 0.63 | 0.53 | 0.63 | 0.56 | 0.59 | 0.49 | 0.72 | 0.76 | 0.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rella Riccardi, M.; Mauriello, F.; Sarkar, S.; Galante, F.; Scarano, A.; Montella, A. Parametric and Non-Parametric Analyses for Pedestrian Crash Severity Prediction in Great Britain. Sustainability 2022, 14, 3188. https://doi.org/10.3390/su14063188
Rella Riccardi M, Mauriello F, Sarkar S, Galante F, Scarano A, Montella A. Parametric and Non-Parametric Analyses for Pedestrian Crash Severity Prediction in Great Britain. Sustainability. 2022; 14(6):3188. https://doi.org/10.3390/su14063188
Chicago/Turabian StyleRella Riccardi, Maria, Filomena Mauriello, Sobhan Sarkar, Francesco Galante, Antonella Scarano, and Alfonso Montella. 2022. "Parametric and Non-Parametric Analyses for Pedestrian Crash Severity Prediction in Great Britain" Sustainability 14, no. 6: 3188. https://doi.org/10.3390/su14063188