1. Introduction
Context-aware methods, i.e., content-based models, and social context-aware methods, i.e., social context-based models, are two of the most used techniques for detecting fake news [
1,
2,
3,
4]. Content-based models focus on the content of news, i.e., title, body, image, and video. While, socially aware methods take user creation time, engagements, connections, comments, and reposts into consideration. The socially aware methods further extend their expertise in measuring the propagation patterns and comparing them with fake news propagation patterns to detect anomalies, known as propagation structure-based methods. Furthermore, comments, likes, and retweets of a post are also examined to detect irregularities. These methods are known as post-based methods [
5,
6,
7,
8,
9,
10,
11,
12,
13].
The content-based techniques offer a simpler and more realistic method for detecting fake news, especially in the initial stages, but unimodal content-based fake news detection techniques are inefficient at identifying false news since they employ distinct textual [
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27] and visual characteristics [
28,
29,
30,
31,
32,
33,
34]. However, users are purposefully led astray on social media by fake news that is packaged in a variety of genuine facts. Therefore, additional measures such as social context are considered for the accurate detection of fake news. For news articles, we have also introduced a similarity measure between the title and body of news. As the majority of fake news titles are just clickbait and the body of the news does not match the title [
35]. This will provide very crucial information about news articles’ authenticity and support the process of fake news detection. Furthermore, stance detection is incorporated for social media news, this is an important measure to determine a public standpoint and judgment towards a user’s social media post for fake news detection [
9].
The socially aware methods are targeted and effective, but data collection, noisy data, irrelevant data, and missing data pose a lot of challenges. Therefore, a multi-model approach for fake news detection is proposed using socially aware methods including user profile associations, user engagements stance, and context-aware methods including textual, visual features, and similarity measures. Compared to the previous works [
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60], we have added a wider range of news-related and social context features. We attempt to uncover fake news within a few minutes of inception. Our research is the first of its kind to use both credibility and stance in a multimodal automated fake news detection system. The primary objective of this study is to integrate content-based approaches with the social context to significantly boost the model’s effectiveness.
The following is the primary contribution that this study has made:
A similarity measure for the news article title and body for the credibility of the article.
User credibility based on a multi-feature of a user profile.
Fusing of textual and visual features via multi-modal factorized bilinear pooling.
A multimodal approach for identifying fake news based on news content and social context.
Evaluation, findings, and a critical examination of the proposed framework.
The various sections of the paper are structured as follows: A review of the literature is provided in
Section 2. In
Section 3, the proposed model and its components are described.
Section 4 describes the experimental setup.
Section 5 incorporates the results and discussions. Finally,
Section 6 concludes and explores future directions.
2. Literature Review
In this section, we provide a high-level summary of works that are pertinent to the proposed model. The researchers used content-based, social context-based, and hybrid features in multimodal fake news detection methods to verify the authenticity of the news. The following subsections provide descriptions of these techniques.
2.1. Content-Based Fake News Detection
The bulk of textual and visual data is utilized to create content-based characteristics. Textual qualities display the author’s thoughts and ideas, additional it also exhibits their favored writing style [
61,
62]. Modeling and primarily expressing textual representations with deep neural systems [
63,
64,
65] and tensor factorization [
66,
67,
68] has been shown to be effective in detecting fake news. Various parts of fake news broadcasts can be discovered by extracting visual characteristics from visual components such as pictures and videos [
35,
69,
70].
The framework provided by [
71] merged textual and visual aspects into a unified totality. The authors utilized a hierarchical attention network with four layers to achieve their objective. They discovered hidden patterns in the title and body material of the news section. A unique component of the recommended method was the creation of a visual summary. The authors analyzed the semantic similarity between the produced visual summary and title with the content of the news article. They proved that their proposed strategy produced superior results compared to the current best practices. Moreover, a content-based study [
72] offered a semi-supervised text fake news classification system utilizing a convolutional neural network that replicates temporal patterns. The authors trained the proposed technique by applying convolutional filters of different sizes on the titles and body of news items and then concatenating the generated feature vectors. The analysis of testing findings revealed the promising performance of the suggested approach for evaluating whether or not news items were manufactured relative to their legitimate sources.
Vishwakarma et al. [
70] suggested an image-to-text converter, entity extractor, web-scraping tool, and processing node to authenticate bogus news. First, it alters a news article’s picture to extract its content. The second element of the system detects and removes text. The third component searches Google for suitable connections using entity strings. Finally, the fourth collects the links’ text and estimates the proportion of entities shared by the image and the summed material. The proportion also reflects connection credibility. Finally, the ratio of trustworthy to untrustworthy connections determines news credibility.
Other studies examined content-based models using reinforcement learning, attention-residual networks, and fact-checking URL recommendation [
73,
74] "Hoax News Inspector" involves data collection and categorization [
73]. The first module’s query is the news article assertions. The second core module includes URL filtering, processing, and classification. URL filtering removes unwanted URLs. After collecting the most valuable URLs, the processing unit retrieves the characteristics needed to recognize fake news. A classification model predicts using all feature sets.
The Elementary Discoursed Unit, developed by Wang et al. [
44], has a level of detail between the word and the sentence, making it ideal for the early detection of fake news. Mishra et al. [
36] identified fake news by employing a probabilistic latent semantic analysis. Knowledge graph-based document representations can achieve state-of-the-art performance when combined with existing contextual representations, as demonstrated by Koloski et al. [
37]. Dynamic fake news detection using a knowledge graph was proposed by Abdelnabi, Hasan, and Fritz [
38] and Sun et al. [
39]. Significant gains have been seen with some unimodal approaches to detecting fake news. Yet the majority of content published on social media and in the news is of the multimodal variety. So, it’s clear that a detection method based solely on unimodal features is inadequate.
2.2. User Credibility Based Fake News Detection
Veracity in social media statistics is an urgent and modern problem. Given the sheer volume of information shared in the social media sphere, the authenticity of such information is especially important when individuals’ personal details are concerned [
75,
76]. There are a number of proposed methods for assessing social media credibility [
77,
78,
79,
80,
81,
82,
83,
84,
85]. There is a strong correlation between social network topology and user trustworthiness [
86]. Using the strength of the ties between a user’s Facebook friends, Podobnik et al. [
83] offers a model to ascertain the level of trust between those friends. In addition, Agarwal and Zhou [
82] provide an approach for gauging a social media user’s reliability that makes use of a heterogeneous network in which each actor in the Twitter domain is represented by a distinct vertex type. An evaluation of reliability was conducted utilizing a regressive spread approach. However, the value of a weighting method and the passage of time are ignored in that work. The believability of each edge category should be evaluated independently, hence a weighting mechanism is required. Incorporating a temporal/time dimension is important since the value placed on trustworthiness changes throughout time. Aghdam et al. [
87] and Al-Qurishi et al. [
88] both go into further detail on the subject of credibility and the inclusion of network structure. Kožuh & Čakš [
89] explored the topic of news credibility. They claimed that individuals’ characteristics and level of interest in the news are the decisive factors in establishing credibility in social media news. The research also established a link between NFC and both confidence in the media and active participation in that trust.
Few studies [
2,
7,
8,
9,
10,
11,
12,
13,
40,
41,
42,
43] have tried to employ user profile characteristics for fake news detection. Wu et al. [
12] identified bogus news by employing an LSTM network along propagation pathways and obtaining user personal information included from social media. To learn a representation for each tweet, Ma et al. [
10] developed a recursive neural model that takes advantage of tree topologies in neural networks. To uncover the spread of false information, Liu et al. [
7] developed a time series classifier model using RNN and CNN. To better detect false news, Guo et al. [
2] looked into the HSA-BLSTM model, which gathers information from both the text and the social context. One effective strategy for rumor detection was developed by Ma et al. [
9] and Li et al. [
8], which takes into account the user’s perspective during multi-task learning. News circulation trends were graphically recorded by Wu et al. [
13]. Unsupervised learning is utilized in the UbCadet model developed by Savyan and Bhanu [
11] to identify compromised Twitter accounts.
The approach of rumor identification presented by Chen, Zhou, Trajcevski, and Bonsangue [
40] makes use of multi-view learning and attention from several users. This method has the ability to learn and combine the representations of multiple users’ perspectives throughout the tweet’s propagation channel. Quantitative argumentation is the basis for Chi and Liao’s [
41] proposed QA-AXDS, a rumor-detection and user-interaction system that use a dialogue tree as its explanation model. Two parts make up the transformer framework-based model proposed by Raza and Ding [
42]: an encoder element to extract representations from the fake news data and a decoder component to detect behavior based on previous data. To identify fake information on social media, Jarrahi and Safari [
43] used CNN with three-dimensional input. They have concentrated their attention on the usefulness of the features offered by publishers
In this study, we analyze credibility as a complicated attribute used by publishers to identify fake news on social media and to present a multi-modal framework with a high level of performance.
2.3. Multimodal Fake News Detection
Deep neural networks have seen widespread application in multimodal data-dependent tasks in recent years, including the answering of visual questions [
28], the captioning of images [
53], and the identification of fake news [
54,
56,
57,
60]. Chen et al. [
17] developed an attention-based RNN model that extracts and uses an attention mechanism to blend aspects of a text, image, and social context. For use in a variety of internet-of-things (IoT) applications, Singh et al. [
55] developed a model known as an extreme learning machine (ELM). Yang et al. [
59] analyzed both the text and the images and then used the adaptive tag (AT) algorithm to derive user-interested tags. The Text Image-CNN model proposed by Yang et al. [
60] gathers information that is both overt and covert from both the text and the images to identify instances of fake news. Wang et al. [
58] introduced the Event Adversarial Neural Network, a comprehensive framework for the identification of misleading information and event discriminators (EANN). Textual and visual characteristics were retrieved in the multimodal feature extractor section using the Text-CNN and VGG-19 models, respectively. Unfortunately, there is no clear method for using this methodology to uncover intermodal relationships. Khattar et al. [
54] suggested a comparable framework, named Multivariational Autoencoder, for the identification of fake news (MVAE). An encoder module is responsible for teaching the MVAE model, the multimodal information’s common representation or latent vector, which includes both textual and visual components. This latent vector is used by the decoder to recreate the original samples. SpotFake is a multimodal system for detecting false news that was developed by Shivangi et al. [
57]. This model avoids the extra tasks of EANN and MVAE and achieves a greater detection accuracy increase. The BERT model for representing textual features and a pre-trained CNN model using the Imagenet database (VGG-19) for representing visual features, SpotFake delivers a reasonable accuracy improvement over EANN and MVAE compared to past efforts [
54,
58]. Shivangi et al. [
56] created SpotFake+, an enhanced version of SpotFake [
57]. This suggested architecture has the advantage of being able to manage a dataset including full-length articles. This model outperformed previous efforts [
54,
57,
58] because it makes use of transfer learning to recognize a news item’s written and visual characteristics.
As a means of exploiting both the visual and textual content of news articles, Zhou et al. [
45] presented the FND-CLIP framework. A ResNet-based encoder and a BERT-based encoder were used to combine the deep-learning features of text and images, respectively. Article classification has been improved by applying scaled dot-product attention to a fine-grained fusion of image and text data, as performed by Wang et al. [
46]. Their technique focused on associations between visual characteristics and collected multimodal feature interdependence. Shivangi et al. [
47] developed a method to selectively extract useful data from the dominant modality while discarding irrelevant data from the weaker modalities. Using a contrastive learning strategy, Chen et al. [
48] have trained variational autoencoders (VAE) to compress pictures and texts and minimize the Kullback-Leibler (KL) divergence for news containing valid image-text pairs. The multimodal characteristics are then reweighted based on the matching cross-modal ambiguity score. An implementation of a two-stage network is provided by Wei et al. [
49], which initially trains two unimodal networks to learn cross-modal correlation via contrastive learning before fine-tuning the network for false news detection. The model developed by Das et al. [
50] incorporates a wide variety of characteristics seen in social settings and in news articles. The dynamic analysis uses a recurrent neural network (RNN) to model the temporal evolution pattern of the propagation tree and the stance network.
Davoudi et al. [
51] identified news articles by source, username, and URL domain. These attributes were employed as statistical characteristics in an ensemble model comprising pre-trained models, a statistical feature fusion network, a unique heuristic approach, and news article variables. Segura-Bedmar and Alonso-Bartolome [
52] categorized fake news using unimodal and multimodal approaches. Their multimodal technique integrates text and image data based on CNN architecture. Images were beneficial for manipulative content, sarcasm, and misleading associations.
The following are some of the issues that current multimodal fake news detection systems are facing. Although the majority of them attain plenty of context information, they still:
Lack of similarity for title and body text.
Effective integration of text and visual features.
Lack of user context information.
Lack of stance analysis.
The objective of this research is to extract characteristics that are helpful and relevant from the substance of the news. Because we take into account a variety of modalities, our attention is focused on the extraction of features from the text and visual contents of a news item. Many sequence models exist for processing text, but they can’t develop persistent associations between words or access the input phrase in order. As a result, BRNN equipped with an attention mechanism is employed to analyze text features in both directions.
In addition, earlier research has employed CNN to extract visual characteristics, Nevertheless, as a result of its pooling operation and longitudinal sensitivity, CNN cannot retrieve more informative information. CapsNet has been used to address the issue of information extraction at CNN. The Routing-by-agreement approach and the Margin loss function are utilized to single out the visual components inside the photos of news items that are considered to be the most essential.
Furthermore, to improve the overall effectiveness of the identification of fake news, the suggested model combines semantically significant characteristics with cosine similarity perspective, and social context information to produce an improved feature vector representation for the supplied news. The goal is to combine the retrieved characteristics of the image and the text to get the highest possible correlation between the two and provide a more accurate shared representation. The Multimodal Factorized Bilinear-pooling (MFB) method allows us to accomplish this goal. The increased feature vector is further sent to the multi-perceptron layer. The output indicates whether or not the news item or tweet contains false news.
3. Methodology
The architecture of the proposed multimodal for fake news detection is presented in this section.
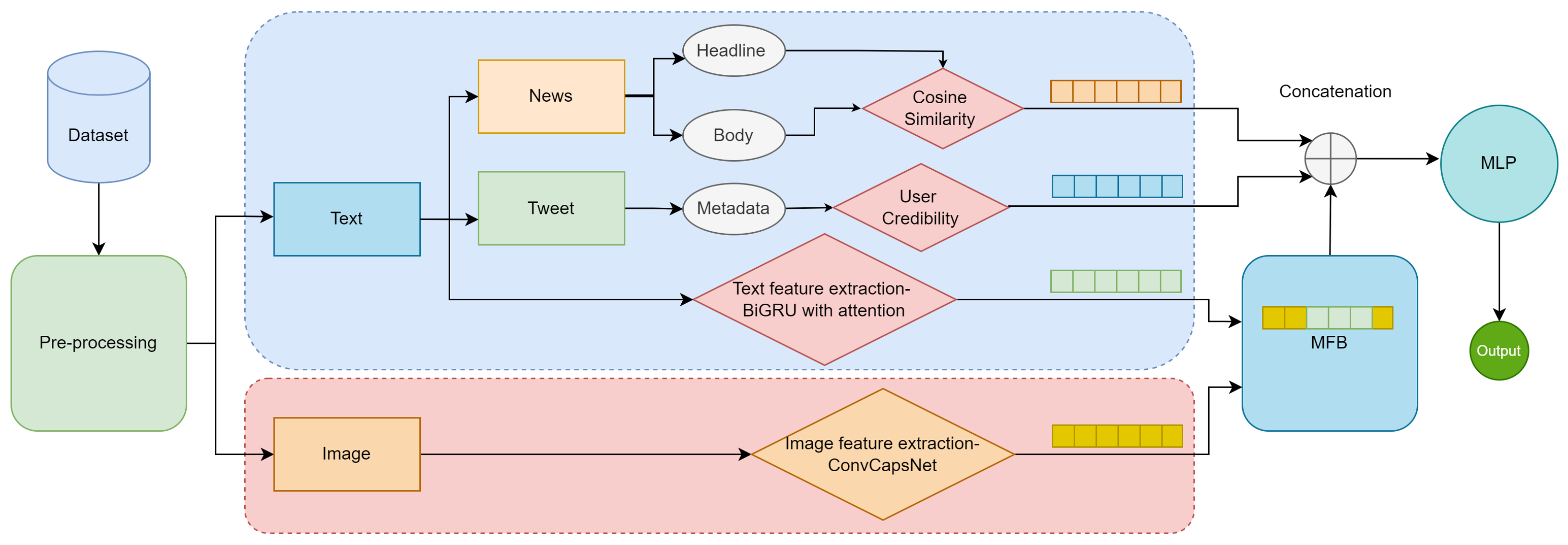
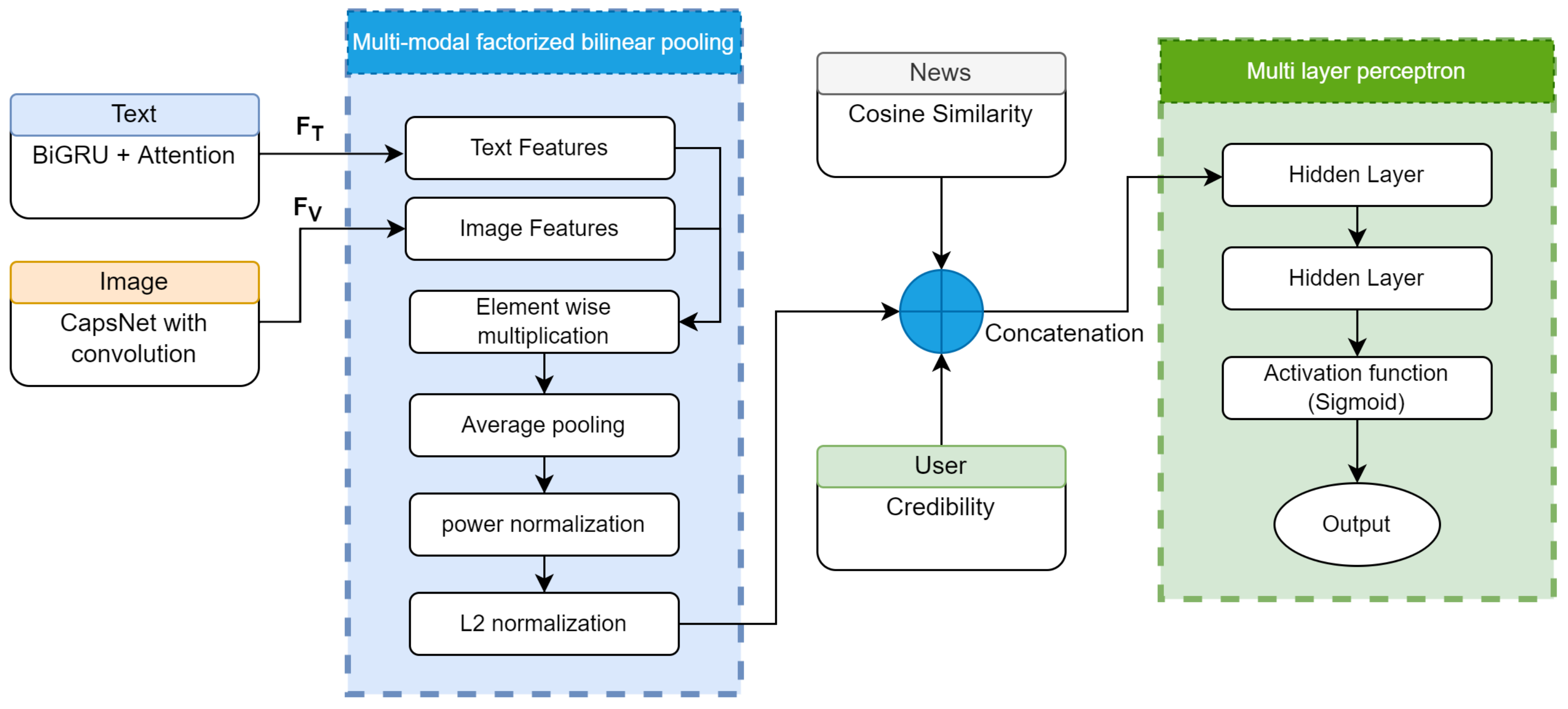
Figure 1 represents the workflow and related modules.
Several text preparation techniques, like tokenization, phrasing, denoising, lemmatization, and stop-word removal, are used to turn documents into a representation appropriate for the classification model in the initial stage. The datasets feature photographs collected from various locations. Images have a high resolution, hence a robust system is needed to evaluate them in their native dimensions employing capsule neural networks. The processing of such high-quality images is time-consuming and expensive in all standard deep-learning models. We scaled all the pictures to 256 × 256 to overcome this problem. Image and text feature vectors are separately trained using neural networks. The news article credibility module calculates the similarity index for the item’s title and body. Textual feature data from news articles is calculated with Semantic Encoding. Using metadata, the user credibility module ranks profiles. The fusion of textual characteristics and visual features is performed using multi-modal factorized bilinear pooling. Later the fused features are concatenated with text similarity and user credibility features. In the final stage, the concatenated features produced from the previous step are utilized as input vectors and fed into MLP for fake news classification.
3.1. Visual Encoding
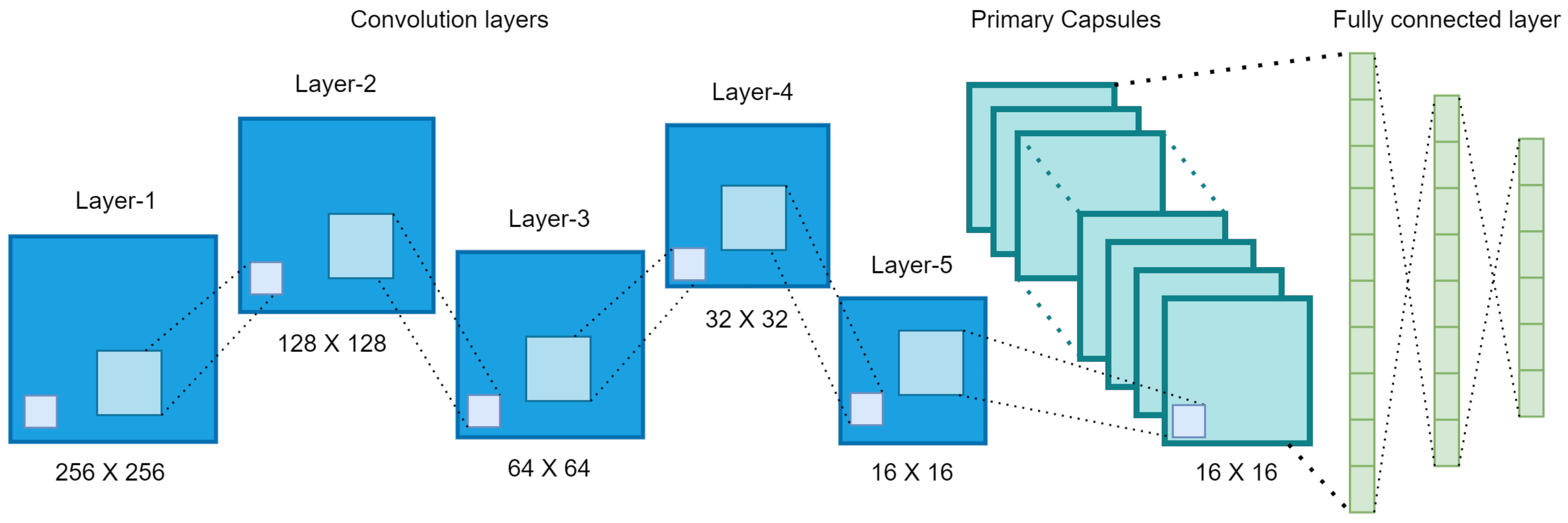
The components of the image learning module are presented in
Figure 2, followed by the description related to its processing.
To preserve item locations and attributes in a picture while modeling their hierarchical relationships, capsule networks have been constructed [
90]. With the pooling layer, convolutional neural networks can extract the most insightful insights from their input. Since the data is pooled before being sent on to the next layer, likely, the network won’t pick up on finer distinctions [
91]. And the neural output that CNN generates is a scalar value. By packing multiple neurons into each capsule, capsule networks provide a vectorial output of the same size but with distinct routings. [
92] A vector’s paths stand in for the pictures’ settings. Scalar input activation functions like ReLU, Sigmoid, and Tangent are used by CNN. Instead, capsule networks employ a vectorial activation function described by the Equation (
1) as squashing. If there is an item in the image,
squeezes short vectors toward 0 and long vectors towards 1 [
93,
94]. In capsule networks, the input value of capsule
is calculated by adding the weighted sum of the prediction vectors
in the capsules of the lower layers, with the exception of the first layer. Multiplying the output
of a lower-layer capsule by a weight matrix yields the prediction vector (
) (
).
where,
represents capsule j’s output and
its entire input. The dynamic routing procedure selects the coefficient
. Logarithmic probability is a gift from
. Log prior probability is calculated using SoftMax [
95] and is equal to the total of the correlation coefficients between capsule I and capsules in the top layer. Objects of a certain class can be detected by calculating the margin loss in capsule networks using the Equation (
2).
If class
k exists, then and only then does
equal 1. The loss is down-weighted when the hyperparameters,
= 0.9,
= 0.1, are used [
95]. Parameter information such as texture, color, location, size, etc. is contained in the direction of the vectors generated by the capsule networks, while the length of the vector reflects the likelihood of appearing in that region of the picture [
94,
96].
In this research, we present a capsule network with six convolution layers for classifying images of size 256 × 256. The number of convolution layers is raised to improve the performance of the primary layer’s feature map. The first layer has 16 filters of size 5 × 5 with a stride of 1. After each layer, a Max-pooling of size 2 × 2 is applied. The second, third, fourth, and fifth layers contain 32, 64, 128, and 256 filters with dimensions of 5 × 5, 5 × 5, 5 × 5, and 9 × 9, respectively. The sixth layer is the primary layer, and it has 512 filters with 32 capsules containing filters of size 9 × 9.
3.2. Semantic Encoding
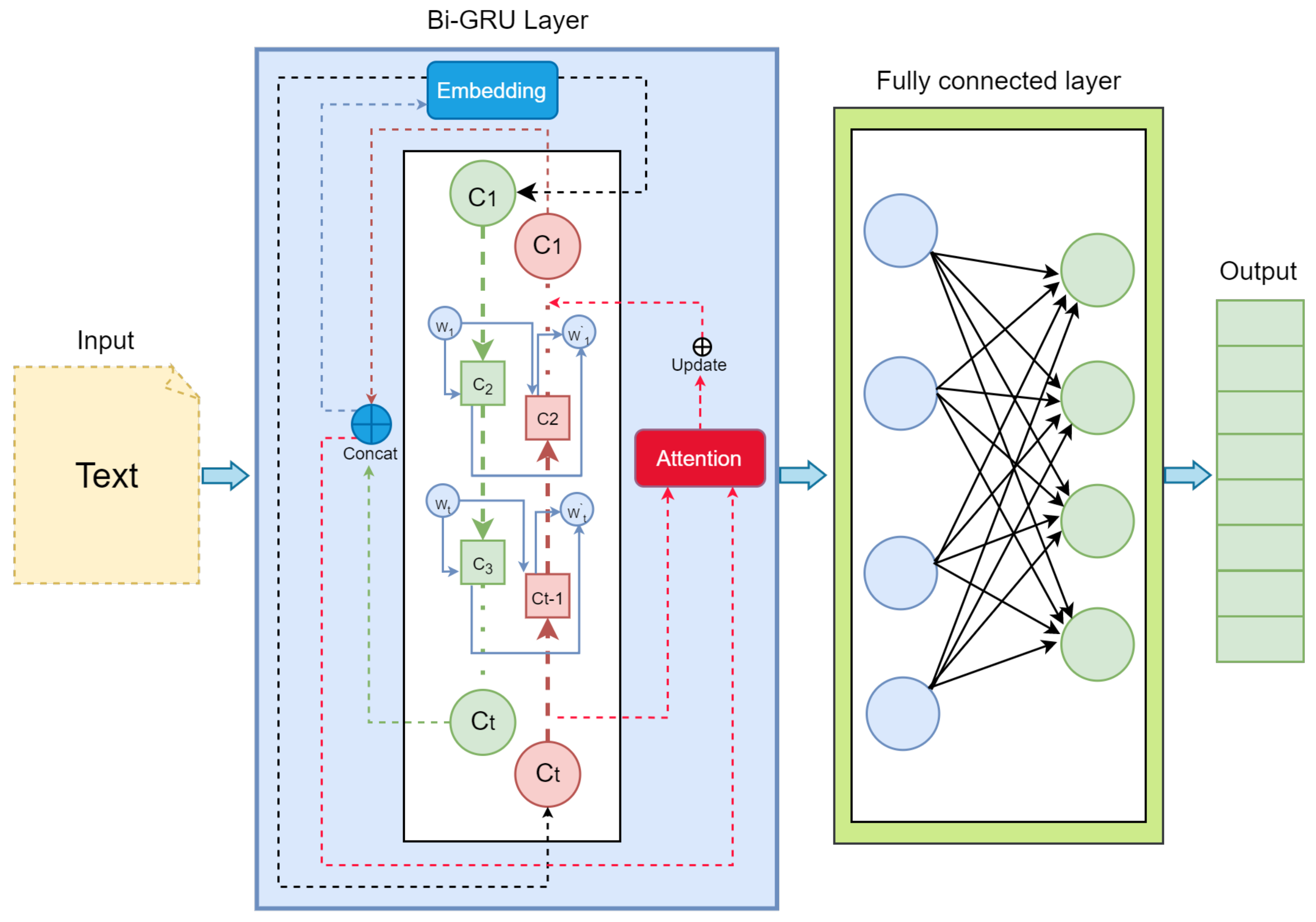
The text learning modules are represented in
Figure 3, and the feature extraction process is discussed in the following paragraphs.
The proposed model seeks to learn information at the word, phrase, and document levels from various news articles and tweets. The word encoder is based on a bidirectional recurrent neural network (BRNN) [
97], which allows the usage of variable-length contexts before and after the current word placement. Since we didn’t want to use separate memory cells to keep tabs on the status of the input sequences, we turned to the Gated Recurrent Unit (GRU) [
98], It works well for determining correlation over broad temporal ranges. Both reset gate
and update gate
are included in GRU. Both attempts to control the state’s access to the most recent data. The GRU computes its new state at time t using the Equation (
3). Using the new sequence information, this is a linear interpolation between the old state
and the candidate state
. The update gate
is responsible for deciding what percentage of the previously stored data will be kept and what percentage of new data will be added. Here,
is calculated using Equation (
4).
where,
represents the embedding vector at time
t.
represents the weight matric,
and
represents bias matrices with the proper dimensions. The symbol
indicates a sigmoid activation function, whereas the operation
denotes elementwise multiplication. The current state is calculated as
represented in Equation (
5).
where the reset gate
is responsible for determining the amount of information from the previous state that is added to the current state. The bidirectional GRU employs hidden layers in both the forward and backward directions to perform an analysis of the input data, much like the unidirectional GRU does. The output is the result of adding together the computed values in both directions. Let
and
represent the forward and reverse outputs of the bidirectional GRU, respectively. The output is calculated by adding the forward and reverse outputs in order, such as
.
The sentence encoder takes the word representation as input and utilizes the embedding and bidirectional GRU layers to generate sentence-level vectors. After that, the sentence-level vectors are transformed into document-level vectors by the utilization of bidirectional GRU layers. There is a disparity in the amount of contribution made by individual words and sentences to the generative model. Consequently, the attention mechanism [
90] is included in our effort to extract the crucial features of the model. Assume, the input text comprises
M sentences, with
words per sentence. Let
and
represent the words in the
i. sentence. The embedding layer and bidirectional GRU layer are responsible for the transformation of a
into the hidden state
. The transformation is described as Equation (
6):
where
represents the matrix of the embedding layer and
and
reflect the procedures described in the preceding section. Consequently, the attention weights of words
and sentences vectors
can be calculated as Equation (
7):
During the training phase, the context vector
receives a random starting point and is simultaneously updated with new information. This vector may be thought of as a high-level representation of a fixed input across words [
99,
100]. The sentence vectors
are then transformed into the hidden state
using a second bidirectional GRU layer, as shown in Equation (
8).
Afterward, the attention weights of words
and item vectors
v are determined using the formulas in Equation (
9).
To represent the sentence-level context vector, is given a random starting point and is then updated in the same way as . Through the foregoing training procedure, the item vector F that is generated from a text contains multilevel contextual information derived from both the word-level and the sentence-level structures. Therefore, we refer to it as in the next parts.
3.3. News Article Credibility Module
Based on research by Dong et al. [
101] on detecting sensationalism in headlines and bodies of articles, we hypothesize that the degree to which these two elements are the same is a good indicator of an article’s reliability. To determine the degree of resemblance, we first embed the article body and title onto the same space and then calculate the cosine distance between them. Since cosine similarity captures the angle of the documents rather than the magnitude, it is an excellent similarity metric for determining the relationship of the documents regardless of their size. It is a mathematical measure of the cosine of the angle formed by the projection of two vectors into space, represented in Equation (
10).
The dot product of the two vectors is represented as .
3.4. User Credibility Module
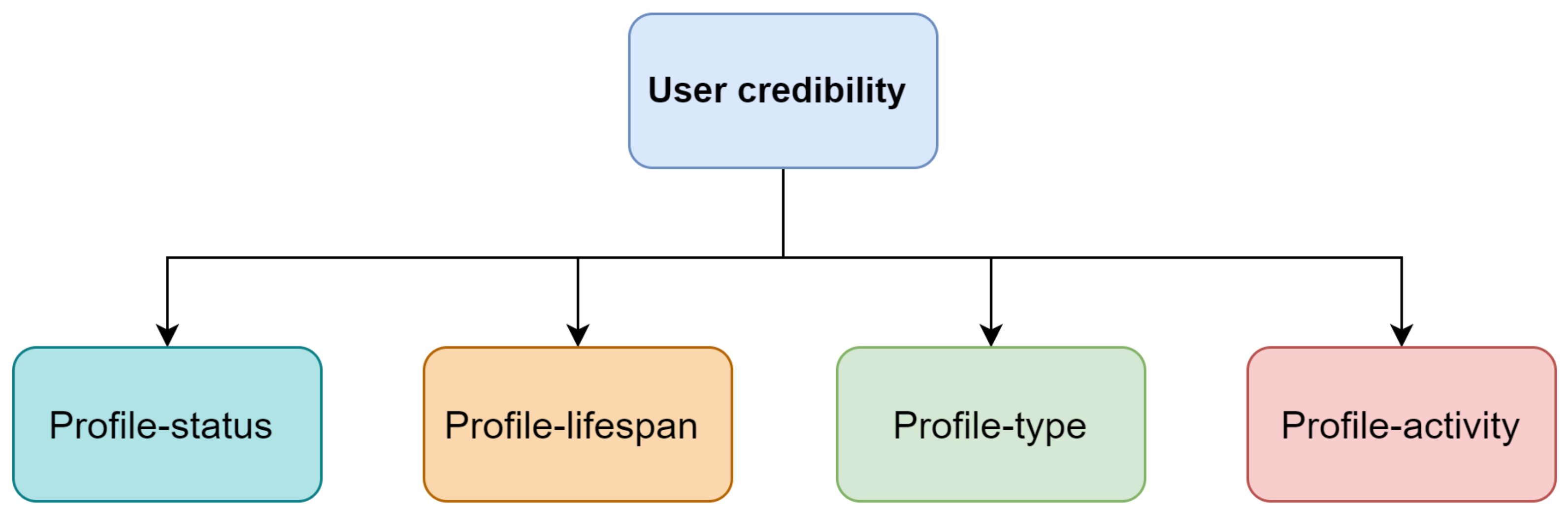
To locate socially trustworthy content, it is crucial to have a proper understanding of user interaction-based qualities. Examining the level of interest that users’ followers have in their posts is a crucial part of this process. A feature-based ranking model is constructed using a measure that considers a number of critical characteristics shown in
Figure 4.
3.4.1. Profile Lifespan
It provides most information related to user credibility. Most of the time the misinformation is spread from user accounts that are not verified therefore the overall score for this feature is kept at the highest priority. The verified accounts get a 1 and the unverified accounts get a 0 score.
3.4.2. Profile Status
It calculates the time information about the existence of user accounts on social media platforms. The variables under consideration are
is the signup date for the user,
is the date of creation of the social media platform, and
is today’s date. The calculations are presented in Equation (
11).
where
is the number of months of the user profile, and
is the number of months after the creation of a social network.
3.4.3. Profile Type
Every who uses social media agrees with the fact that the number of followers and friends can be a huge factor in determining the credibility of a user. The users on a social network can be roughly classified into three types. The first ones are looking for information, they mostly scroll through the platform, follow people, and barely post their own updates. The second ones are content creators with few to the huge number of followers, they update quite often and keep their followers interested in their content. The third ones do not get their head into the social network but rather keep it balanced. They don’t follow everyone and mostly interact with their circle of friends only. The profile type is calculated as Equation (
12).
Here, the resultant determines the type of the user. A score less than 0.7 indicates the user is a scroller, a score greater than 1.2 indicates the user is a content creator and a score between 0.7 and 1.2 indicates the user is a balanced user.
3.4.4. Profile Activity
The content of a post is very critical to gaining and losing followers. The number of times a user posts new content or retweets is an essential dimension of its credibility. In this study, we give less score to the retweet and more score to the original content posted by a user, represented in Equation (
13).
where
is the content score associated with the profile.
is the number of posts,
is the number of retweets, and
is the age in the number of months for the user profile.
3.4.5. Total Credibility
The total user credibility
score is computed by combing the profile status (50%), lifespan (20%), type (10%), and activity (20%) scores, represented in Equation (
14). After that, a feature vector representing the user’s trustworthiness is constructed by computing the average of the vector values associated with each location vector.
3.5. Multi-Modal Factorized Bilinear Pooling (MFB)
To generate a common representation, MFB provides a phenomenon for the fusion of extracted features from semantic and visual encoders.
Figure 5 represents the structure of MFB.
Using the MFB module, we combine the news article text feature () with visual () feature representations after acquiring them. MFB is preferred over regular concatenation for the reasons outlined below.
Using a typical concatenation of data from many sources, it might be difficult to identify the endpoint of the derived features.
Because features are piled one after the other after concatenation, it is possible that the association between picture and text feature representations will not be recognized.
Using the MFB module, these two issues may indeed be effectively addressed. Furthermore, using this fusion technique, the association between textual and visual components is strengthened. Let us suppose that the textual feature vector is represented by (
) and the visual feature vector is represented by (
). The fundamental multimodal bilinear model is thus specified by the following Equation (
15).
where
is a projection matrix. The bilinear model’s output is
. Though it is effective at capturing pairwise interactions across feature dimensions, bilinear pooling introduces a large number of parameters, leading to a high processing cost and the possibility of over-fitting.
where
k is the hidden dimensionality of the factored matrices
and
is the replication of two vectors, element by element, and
is a vector of ones to obtaining the output feature
using Equation (
16). First, we need to get familiar with two three-order tensors,
and
, which will serve as weights for the output dimension. A further transformation into two-dimensional matrices is possible,
and
after which it may be rewritten as Equation (
17):
3.6. Multi-Layer Perceptron (MLP)
In this step, we develop a multi-layer perceptron consisting of hidden layers and a sigmoid-activated sub-network. The input to this multi-layer perceptron network is a fusion of features from MFB concatenated with similarity features, and user credibility features. The final prediction probability of whether or not a news item or post is fake is calculated by mapping the input onto an objective space comprising two classes, shown in
Figure 5. A binary cross-entropy loss between the ground truth and the predictions is designed as the optimal solution. The letters L and P in the Equation (
18) stand for the original class and the predicted class, respectively.
4. Experiment and Parameter Setup
The models are built, trained, tested, and evaluated all inside the confines of the Google Colab environment. Python is utilized to execute all coding strategies. The proposed multimodal is evaluated using the k-fold strategy for cross-validation. The TensorFlow and scikit-learn libraries are used to create machine learning models. CountVectorizer and the NLTK library are utilized for text preparation.
The news article’s accompanying image is used in conjunction with convolutional CapsNet to generate a visual feature vector. The recommended batch size for training a convolutional CapsNet is 32, and the recommended number of epochs is 100. We used eight child capsules in the Primary capsule layer and two-parent capsules in the Child Capsule Layer. The number of capsules and the complexity of intermediary capsule layers determine the significance of the routing-by-agreement approach. The overall number of hyperparameters will vary depending on them, but it will be less than CNN. The capsule connections in the CapsNet model are established between groups of neurons as opposed to individual neurons; hence, it has fewer parameters than CNN. In comparison to CNN, the Convolutional CapsNet model needs the least amount of time to learn entire sequence data. To produce the 32-dimensional visual feature vector, Fvisual, we evaluated and modified a higher-capsule layer.
The proposed model combines 32-dimensional textual and visual feature vectors using Factorized bilinear pooling to produce a 32-dimensional multimodal feature vector, , with high-level informative features. These multimodal features along with other important features are given into MLP, which is utilized to distinguish bogus and true news based on anticipated probability values.
4.1. Dataset
For our research, we used the publicly available standard fake news dataset called FakeNewsNet. It includes two datasets Gossipcop and Politifact, which comprise news stories about politics and entertainment, respectively. The performance of the proposed model is measured by its effectiveness on these two datasets. The collection consists of news stories, both text, and visuals. The details of various important aspects of datasets are provided in
Table 1.
4.2. Evaluation Metrics
We employed the standard set of performance measures, including accuracy, recall, precision, and f-measure. Furthermore, the challenge of establishing the veracity of a news item is modeled after a classification issue. Here’s a quick rundown of what each metric measures from Equations (
19)–(
22):
where, False positive (
) means that fake news was correctly identified as such, whereas false negative (
) means that real news was correctly identified as fake. The
value in the challenge of identifying false news indicates the proportion of news pieces that were properly labeled.
is measured by the percentage of anticipated false news stories that were accurately labeled. By counting how many false news articles were accurately identified as such, we may determine the recall or true positive rate (TPR). The
is the harmonic mean of the
and
, and it is used to indicate the overall performance of the proposed model.
5. Results and Discussions
In the preceding paragraphs, we detailed our findings from an in-depth analysis of the experimental outcomes of the proposed model utilizing various indicators for measuring performance.
To access the performance of the suggested model, it is put up against FakeNewsNet, a publicly available benchmark dataset.
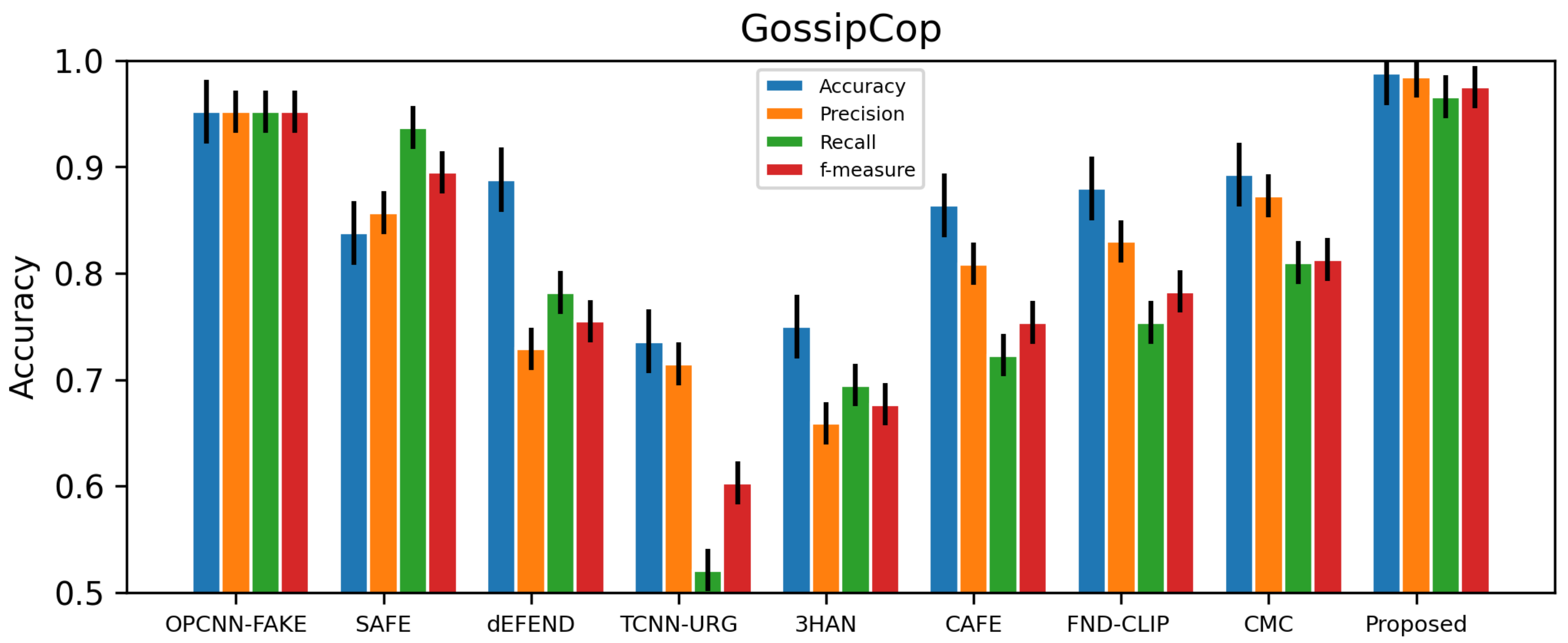
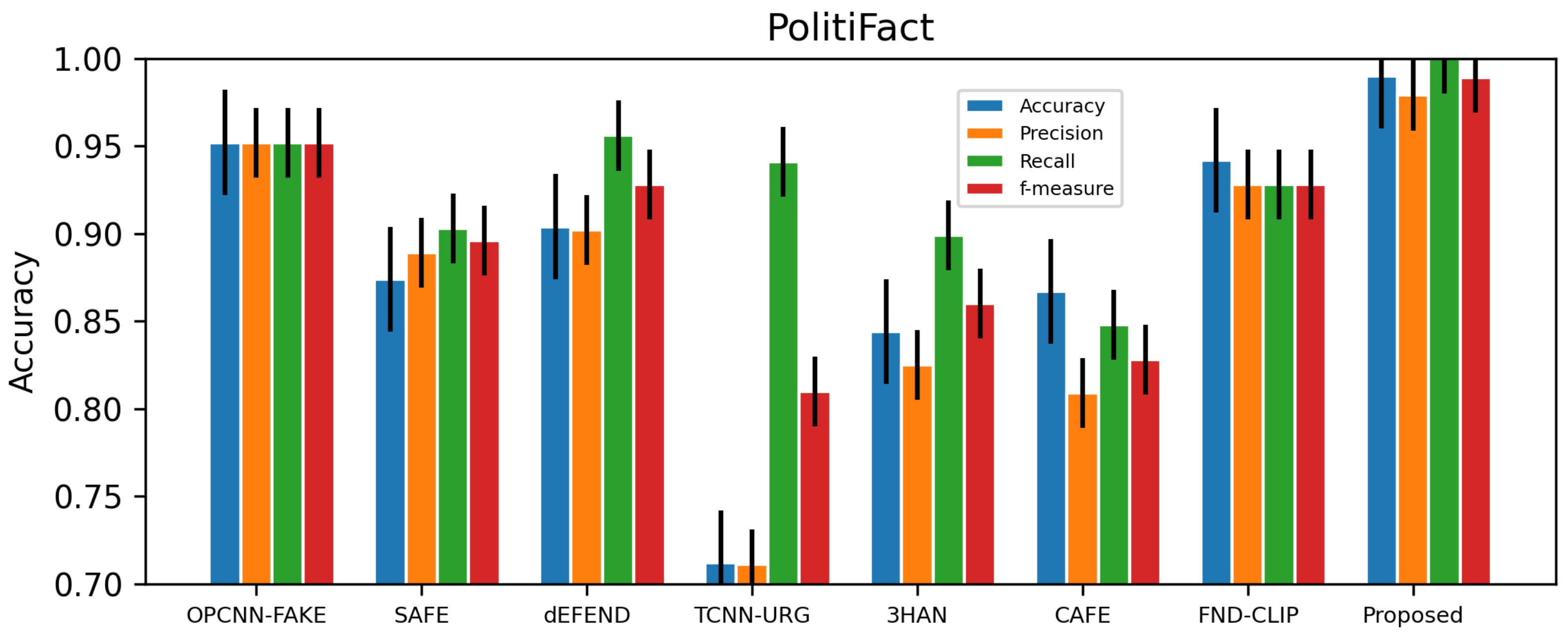
Table 2 displays the collected data. The experimental results show that the proposed model has better accuracy, precision, recall, and f-measure than the baseline and state-of-the-art methods.
When compared to the textual model, it is abundantly clear that the visual model is responsible for producing superior results. This may be due to the fact that texts might occasionally include noisy and unstructured information, but images display evidence more clearly. It is possible to conclude from the findings that combining pictures and text is advantageous since it achieves superior performance when compared to either using images or text alone.
Furthermore, the proposed multimodal provides a complete solution for the fake news detection in news articles, since information like reposts, likes, shares, etc. are not available immediately after a news article is published, the actual content of the article is of utmost significance. Then content can be the only factor examined for detecting fake news. The proposed model uses both the textual and visual aspects of news articles as its input. Cosine similarity of the title and body of the news provides a concrete measurement for comparison of relatedness. Additionally, the information included inside the user profile as well as the behavioral features of the user was added to improve the efficacy of the proposed model.
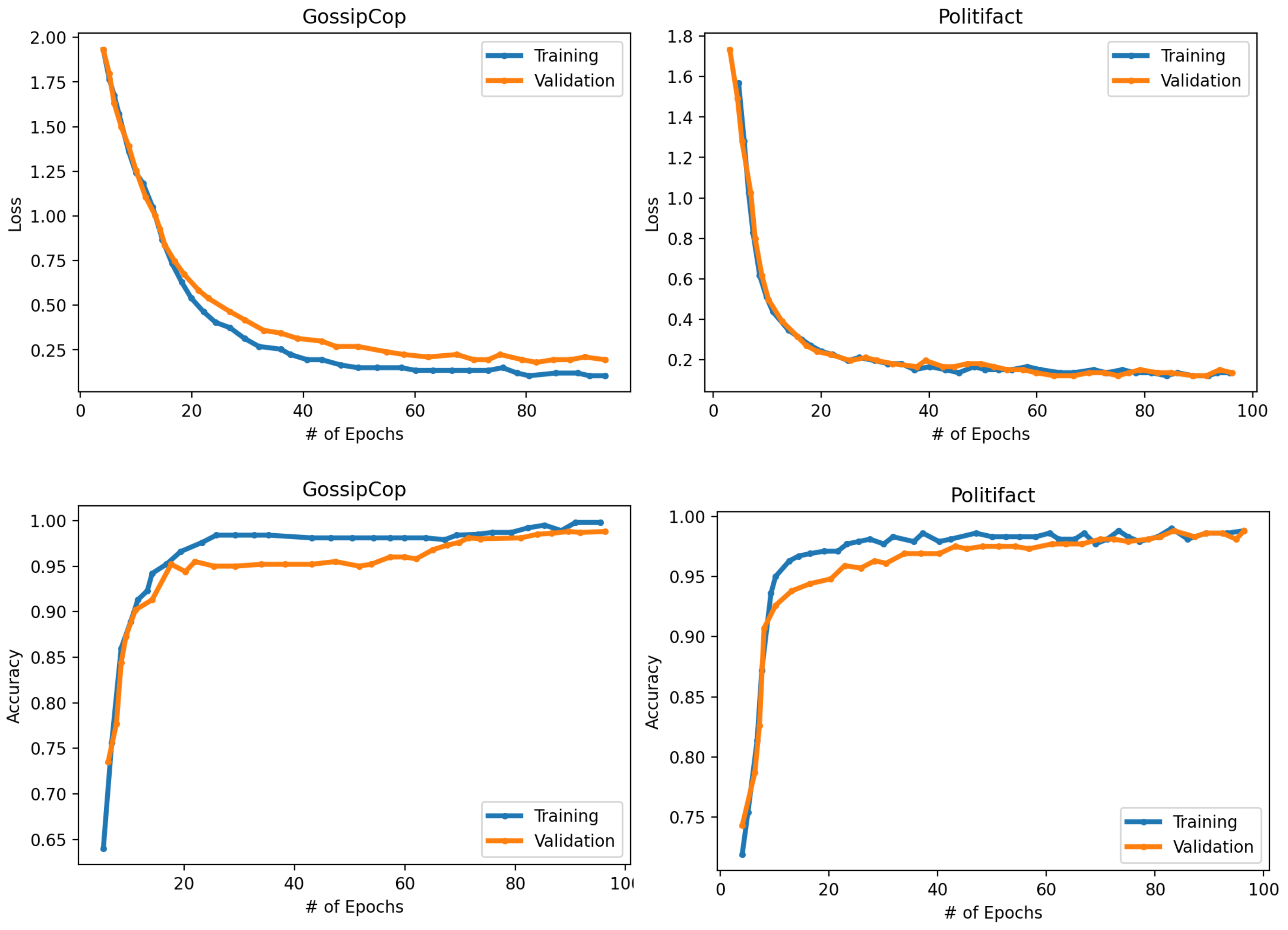
To highlight the value of cosine similarity as a feature, we have attempted encoding the news headline and body together with their degree of similarity and found that this method beats encoding only the title and content. Evidently, the findings show a significant improvement in the reliability of the tests. To test the quality of our model and ensure that its findings are equivalent to those of other models using the same dataset, we have implemented a 10-fold Cross-validation resampling technique. The average loss and accuracy based on epochs are shown in
Figure 6. Even though we used k-fold stratified cross-validation, there were still some misclassified test samples. The main reason for this is that it is difficult to tell the two groups apart due to the features that they share.
As shown in
Table 2, our proposed multimodal outperforms the state-of-the-art multimodal. The image features, cosine similarity, and routing-by-agreement method of the CapsNet architecture are crucial to the success of our suggested model. The accuracy improvement is also a reflection of the user credibility module’s effectiveness. Despite the fact that textual characteristics are superior to visual features in unimodality mode, there are still some worries regarding textual features. Our suggested model achieves 7.3%, 21.5%, and 13.3% better performance than the current baseline models EANN [
58], MVAE [
54] and, SpotFake+ [
56], respectively for the GossipCop dataset. Furthermore, for the PolitiFact dataset, our proposed model outperformed EANN [
58], MVAE [
54] and, SpotFake+ [
56] with 24.5%, 32% and, 14.5% improved accuracy, respectively.
In the end, we also examined how well our suggested model performed in comparison to the most recent and cutting-edge techniques for identifying fake news.
Table 3 represents the algorithms that were utilized for comparison.
The models compared here have the ability of early detection since they do not rely entirely on social interactions. OPCNN-FAKE combined the data from both sources into a single report. The outcomes in
Table 4 show that the suggested model has the highest performance across all measures for both datasets. The comparison between the proposed multimodal and the state-of-the-art multimodal for the GossipCop and politifact datasets are shown in
Figure 7 and
Figure 8, respectively.
The proposed multimodal provides improved performance because we took the necessary steps to address the issues discovered by previous techniques. The combined feature representation can only be obtained using the approaches that are now considered state-of-the-art by concatenating textual and visual characteristics, which does not result in a strong connection between the picture and the text. In this work, features are extracted from a variety of models, and then those characteristics are combined to generate a common representation. In a later stage, the extra feature representations are enhanced by concatenating the additional features. We have conducted empirical research to explore and confirm the significance that pictures and social behavior play in the identification of false news.
Figure 9 provides a selection of tweets and news stories that illustrate how well the suggested algorithm was able to classify their content.
We have employed word, phrase, and document-level encoding for multilayer contextual information retrieval, which permits adjustable text length and simplifies the semantic encoder. In the instance of the visual encoder, we supply a six-layer convolutional network that is responsible for obtaining the most insightful insights and domain-specific characteristics. Some user-related qualities, such as cold start and unreliability, are particularly relevant in practical contexts. Because of the user’s inexperience, very little information may be provided. In this research, we find that the cold start problem affects all of the attributes except for Credibility, Influence, and Sociality. It is not a major issue in the field of identifying fake news since content created by newcomers cannot be extensively disseminated on social media because of the absence of a considerable number of followers.
Furthermore, skepticism is crucial to uncovering fake news. This feature’s unpredictability suggests it might be affected by the user’s actions. It’s possible that publishers will utilize this tactic to fool the system. Only the Sociality trait, out of all the ones we’ve studied, is suspect in this research. On the contrary, if a social influencer spreads misinformation or disinformation, it spreads quickly and widely. For this reason, we cannot recommend Sociality as a tool for identifying fake news. The median number of outlets sharing a given story shifted significantly among beats. There are more outlets that publish political news than other types of news. Furthermore, while more outlets spread false celebrity news than fake political news, political fakery is produced by a smaller number of outlets. Accordingly, it’s safe to say that publishers’ online activities vary greatly depending on the type of news they’re producing.
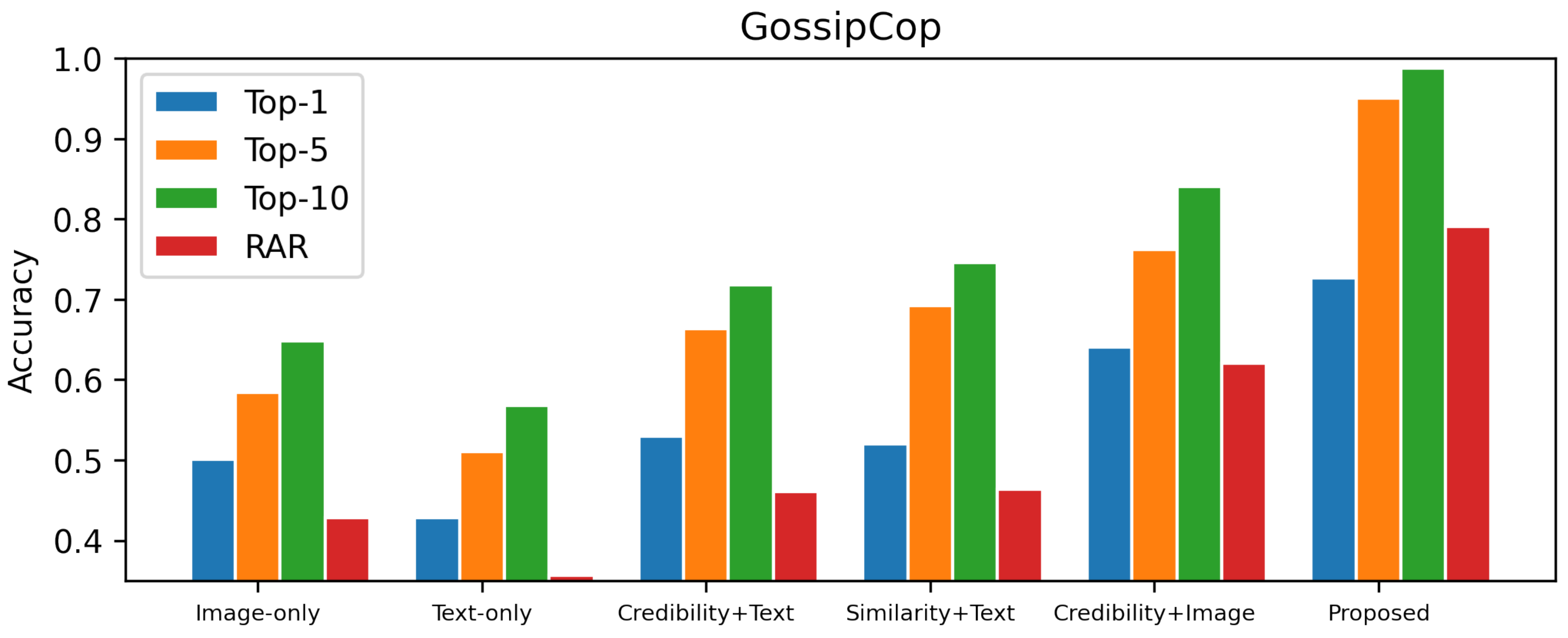
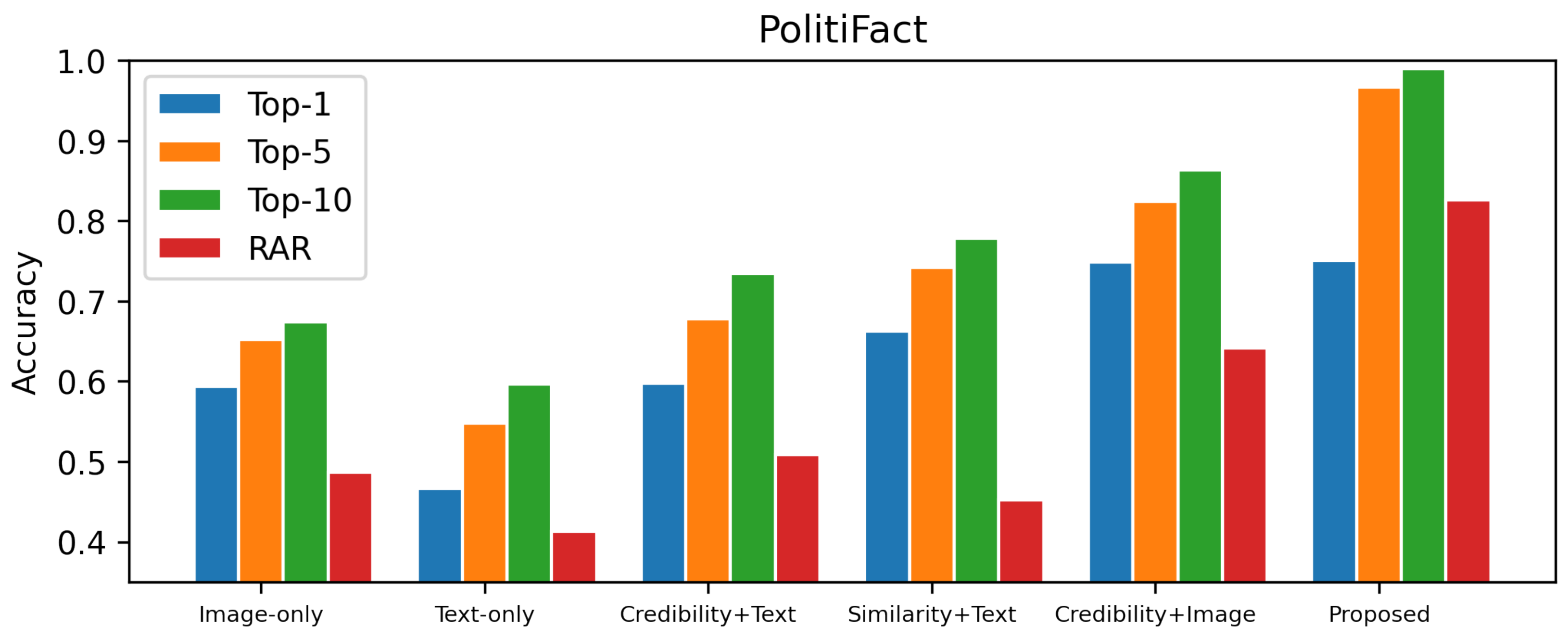
Ablation Study
The act of carefully assessing a framework in both the presence and absence of a certain component is referred to as an ablation study. This analysis is performed by individually removing and then grouping the framework’s components. Identifying both the bottleneck and the unnecessary components lends a hand in the process of optimizing the design of the system. The ablation research is carried out to demonstrate the significance of the contributions made by each of the different modules as well as their level of efficacy. Text features, cosine similarity features, user trustworthiness features, and image features are included in the multi-modal that is being suggested. Experiments are being conducted with individual approaches, ensembles of two modules using the FakeNewsnet dataset with the same parameter settings as the overall proposed framework, shown in
Figure 10 and
Figure 11.
Assessing the relative merits of alternative component arrangements within the framework, we made use of the top-1, top-5, and top-10 accuracies, as well as the reciprocal average rank (RAR) metric. The top-K accuracy measures how accurate the top-k projected scores are by calculating the percentage of correct labels within those scores, presented in
Table 5. The RAR offers information on how far down the list the correct label is located.
Since we’ve taken the appropriate steps to address the issues uncovered by earlier methodologies, the ablation investigation also demonstrates the effectiveness of the proposed framework. picture and text features that have been obtained to maximize similarities and give a more reliable common representation. We can achieve this using the Multimodal Factorized Bilinear-pooling (MFB) technique. Furthermore, the proposed model integrates semantically significant characteristics, the cosine similarity perspective, and social context information to generate a better feature vector representation for the provided news, which in turn improves the overall effectiveness of the identification of fake news. Furthermore, the success of the user credibility module is seen in the increased precision.
This research provides a theoretical account of the steps involved in news classification using processed data, including the extraction of essential features from several modalities, the influence of social context and similarity characteristics, and the fusing of features to generate a common representation. We have conducted empirical research to verify the importance of cosine similarity in identifying fabricated articles. Second, our results provide light on hitherto unrecognized aspects of false news concerning social profiling and online behavior. Every one of these discoveries adds to the body of theoretical information on the subject.
The multimodal approach has several advantages, including the fact that it does not rely on a single data source, which is especially helpful in the case of the early identification of fake news on social media to halt the spread of disinformation. In its earliest stages, it just requires text and images as input, and based on these basic inputs, it derives the semantic and visual essential elements necessary to form a robust correlation. To further forecast whether or not a piece of news is true, it incorporates the cosine similarity properties. Based on our research results, multimodality is an effective technique for detecting bogus news. In this research, we show how to put a deep learning-based multimodal false news detection framework into practice.
In this study, we have developed a multimodal approach that considers the most essential information sources and extraction procedures for detecting fake news. In addition, we have resolved the issues of the current state of the art. However, our model also has some limitations: it does not support languages other than English because it has not been tested and calibrated for other languages. Due to the high association between visuals and accompanying language, complex and altered images with matching text descriptions can occasionally trick the framework. We could address these restrictions to generate a significant, long-lasting influence on the propagation and early identification of fake news. We can also add forgery detection, non-English languages, and meta information that may have a substantial impact on fake news detection. However, it requires the development of a suitable dataset, models, and experimental framework.



 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}