
Towards Massive Data and Sparse Data in Adaptive Micro Open Educational Resource Recommendation: A Study on Semantic Knowledge Base Construction and Cold Start Problem

 ,
, 
Abstract
:1. Introduction
2. Background
2.1. Nature of OERs and Open Learning Delivery in Mobile Environments
2.2. Micro Learning
3. Research Challenges and Design
3.1. Research Design
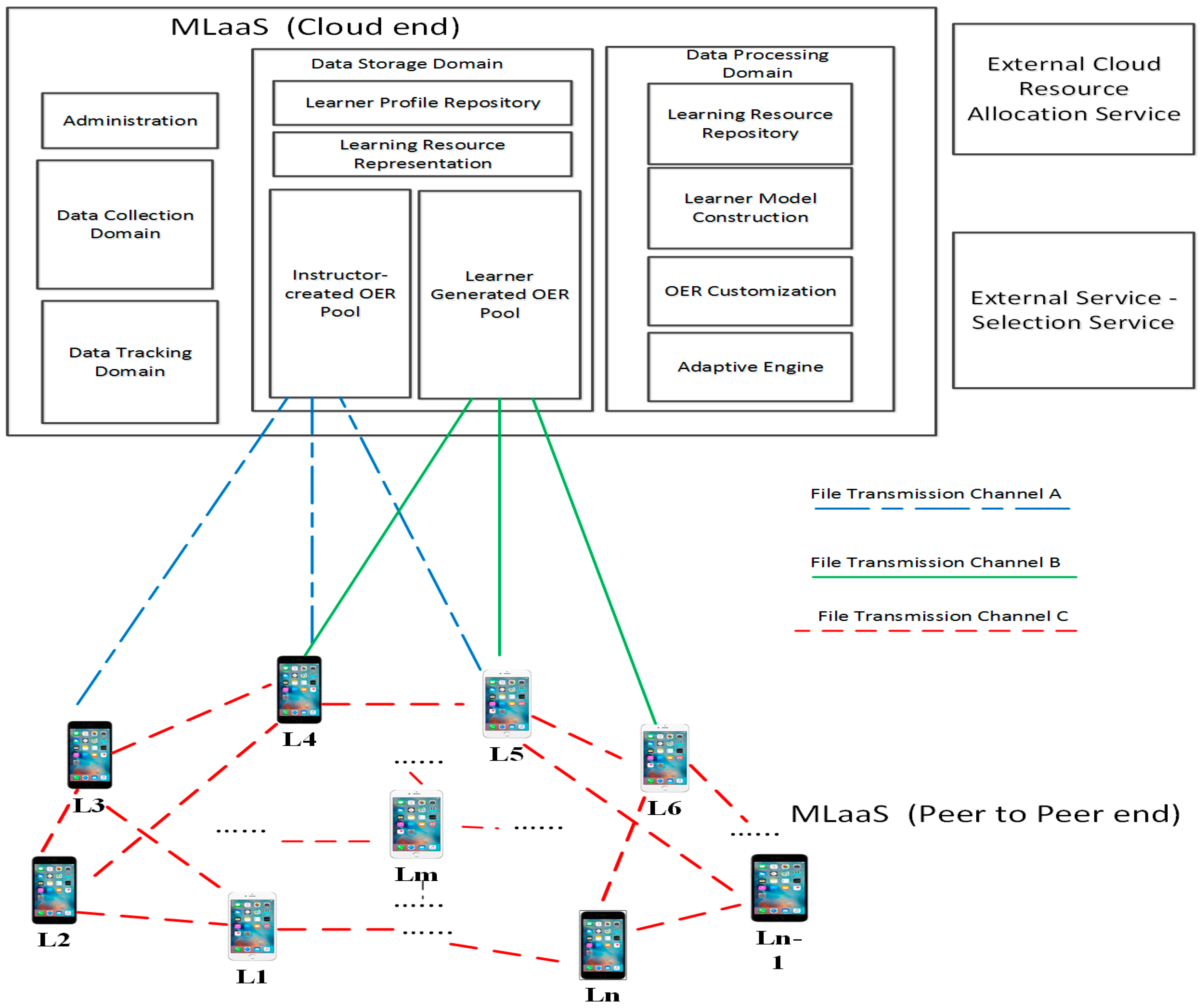
3.1.1. System Framework and Previous Work
- A channel between learners and an instructor-created OER pool in the cloud storage part (i.e., Channel A in Figure 1).
- A channel between learners and a learner-generated OER pool in the cloud storage part (i.e., Channel B in Figure 1).
- A channel among all learners engaged in open learning (i.e., Channel C in Figure 1).
3.1.2. Research Problem Identification and Design
- If a learner is well-known by the MLaaS, an educational data mining and learning analytics (EDM/LA) approach will be applied to his or her historical data to understand his or her learning patterns and preferences. Thereby, a well-grounded recommendation can be made based on his or her personalized settings and particular surroundings.
- If a learner is relatively poorly known by the MLaaS, (i.e., this is a new learner to the OER environment), this will be treated as a cold-start problem and tackled by filling in the gaps with predicted data, so that a recommendation will be made based on demographic information. Freshly generated information, along with the cold-start recommendation, will populate the first version of a learner’s profile.
3.2. Research Challenges
3.2.1. EDM/LA for Micro Learning
3.2.2. Cold Start Problem in Micro OER Delivery
3.3. Contribution
- Top-down processing of semantic knowledge base building.
- Conceptual graph-based ontology construction for the pattern level.
- Data source documentation and data processing strategies for the data level.
- Complete ontology-based mechanism for tackling the cold start problem.
4. Conceptual Graph-Based Ontology Construction for Micro Open Learning and Proposed Data Processing Strategy
4.1. Conceptual Graph-Based Ontology Construction
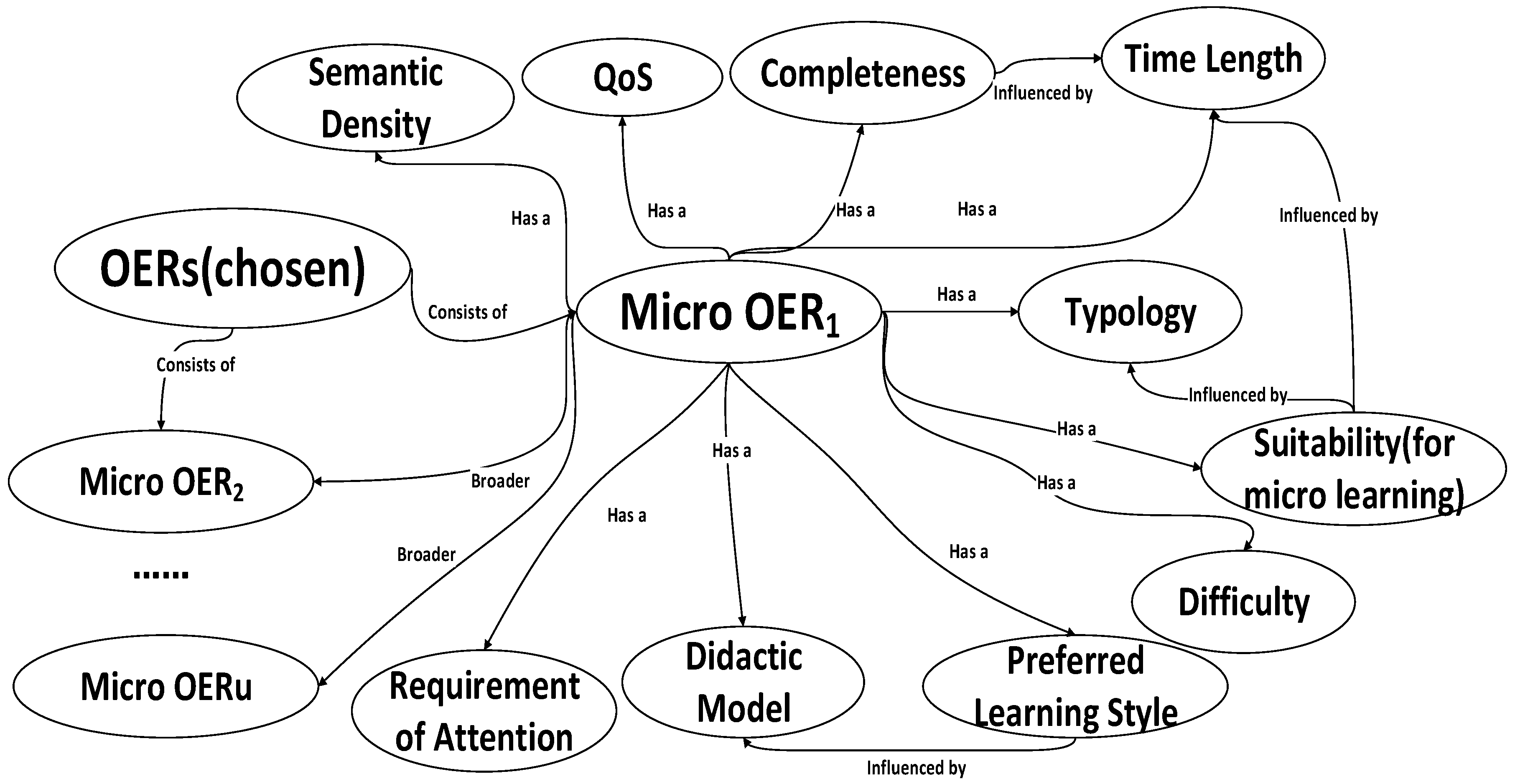
4.1.1. Augmented Micro OER Ontology
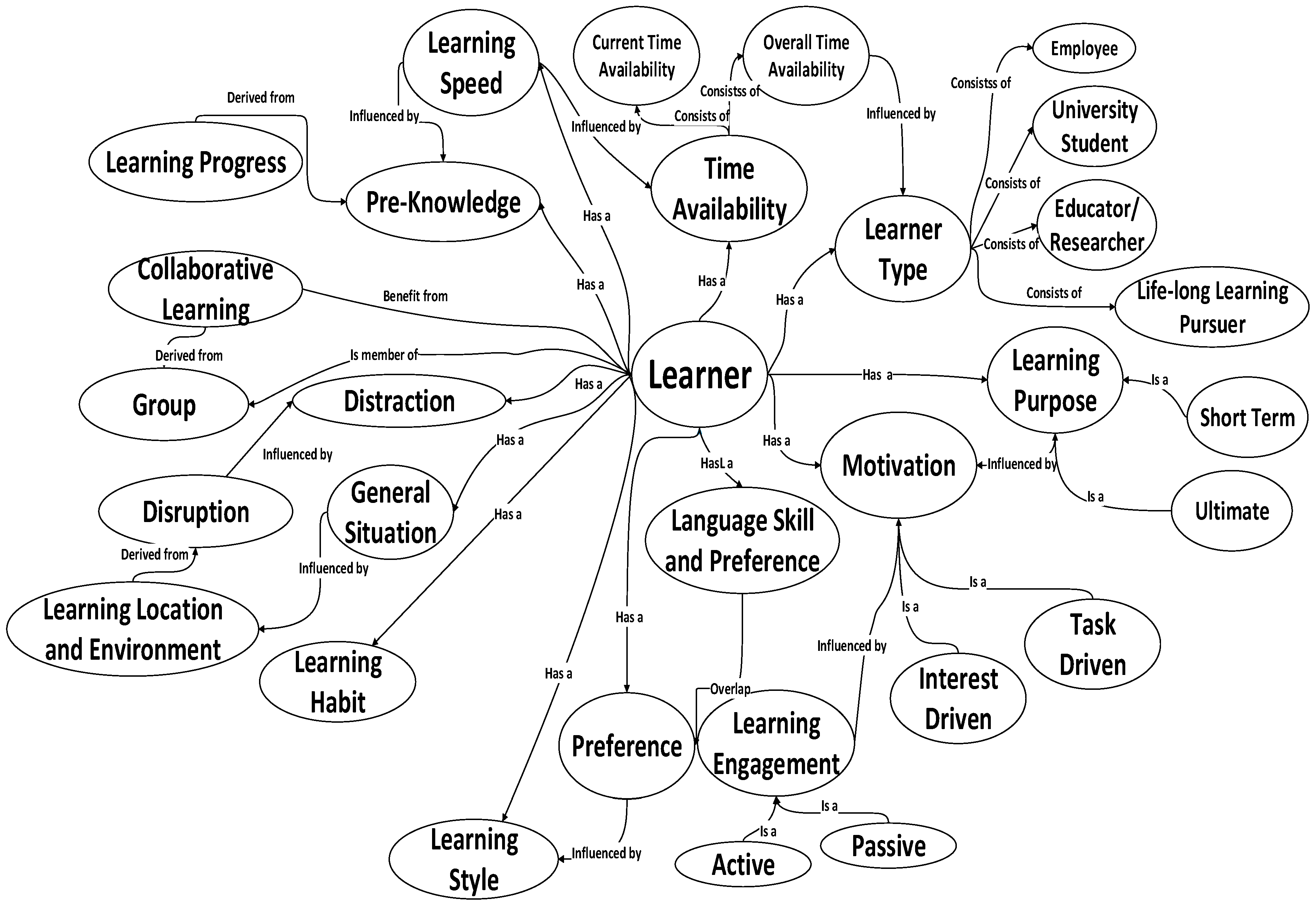
4.1.2. Augmented Micro Learning Learner Profile Taxonomy
4.2. EDM and LA Strategy
- ConsistsOf is an inclusion relation. This relation can be generally found between two OERs or one OER and one micro OER. Two items with this relation are located in different hierarchies of the augmented micro OER ontology.
- RequiredSequence is a strong order between two items (OER or micro OER), where the former micro OER must necessarily be learnt before the latter one, due to course settings and educational consideration.
- RecommendedSequence is a weak order relation between two items (OER and micro OER), where the former micro OER is suggested to be learnt before the latter one, according to the instructor’s guidance, but is not mandatory.
- It is certainly possible for two items (OER or micro OER) to have no relation at all.
- Both relations regarding sequence can be inherited by entities’ descendants, for example, if there is a RecommendedSequence(R1, R2) indicating an OER R1 is preferably learnt prior to R2, then, for MR1 ∈ R1 and MR2∈ R2, there is a RecommendedSequence(MR1, MR2).
- Identify and select heterogeneous data sources to determine the scope of the content.
- Model vocabularies for OER domains.
- Data extraction.
- Generate standardized data descriptions (e.g., RDF data).
- Publish linked data.
- Consume and display linked data.
5. Ontological Approach for the Cold Start Problem
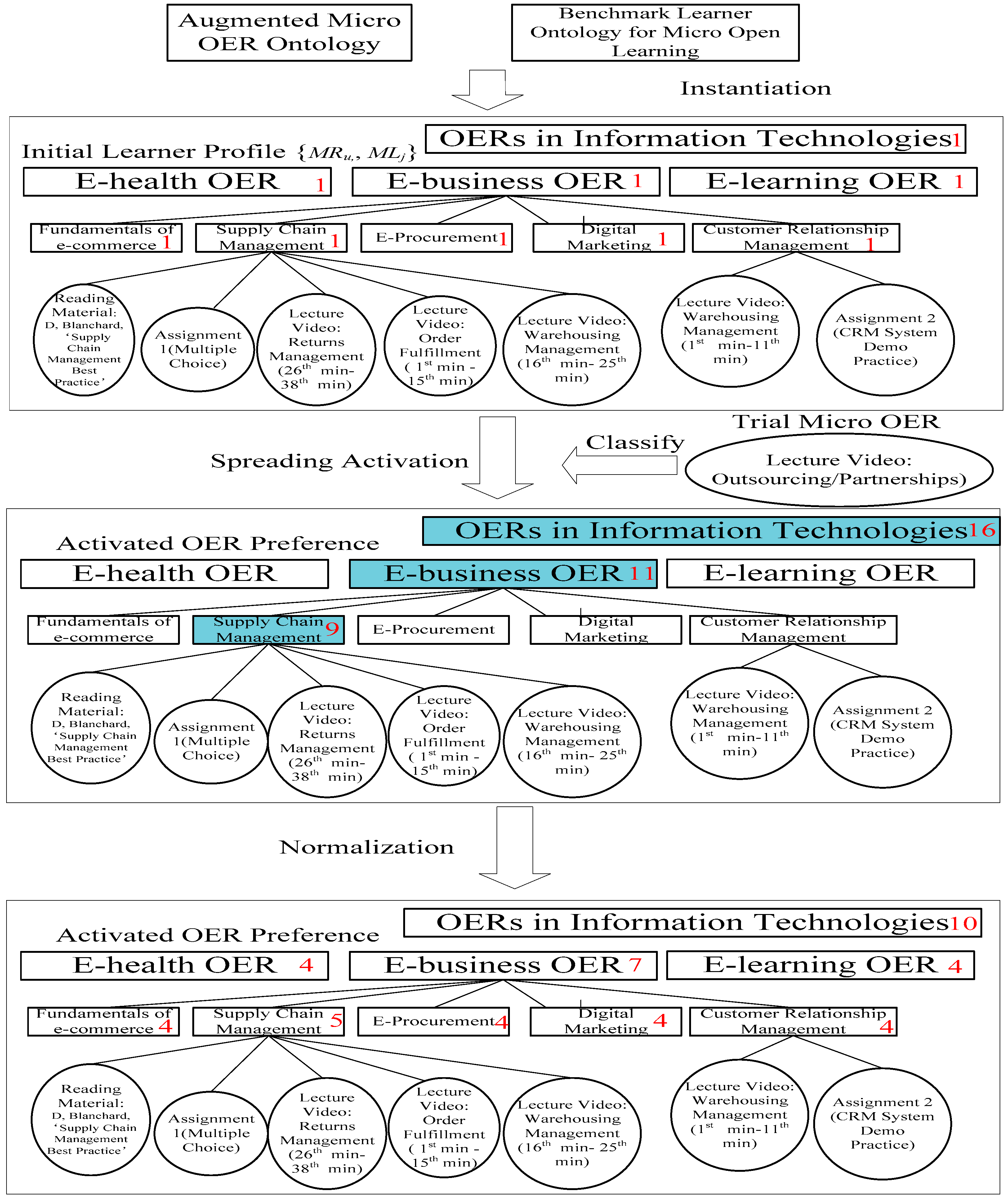
5.1. Representation of Learner Profile
5.2. Preference Propagation
| Algorithm 1 Preference Propagation |
| Input: Dynamic part of learner profile Lj ={ MRu, MLj }, a trial micro OER MRu , Lj ∈ L |
| Output: Updated dynamic part of learner profile with updated Pu,j value in the triple dimensional set ML |
| P(Rv)and Activation(Rv), preference value and activation value for the OER Rv |
| //Step 1: Spreading Activation |
| begin: Initialize PriorityQueue;//PriorityQueue is the set of OERs within the same discipline where Rv belongs to |
| Set Activation of all micro OER to 0 |
| for each Lj ∈ L do |
| if (MRu ∈ Rv) then |
| Activation(Rv)= P(Rv) |
| PriorityQueue.Add(Rv) |
| end if |
| end for |
| while PriorityQueue.Count >0 do |
| Sort PriorityQueue; //activation values in descending order |
| Select the first item MRu in PriorityQueue // Rv with highest P value |
| Remove Rv in PriorityQueue |
| for each Rv do |
| LinkedOERs=GetLinkedOERs(Rv)//get linked nodes of Rv |
| for each Rw in LinkedOERs do //propagate activation to its neighbors |
| Activation(Rw)+=Activation(Rv)*Weight(Rv, Rw ) |
| PriorityQueue.Add(Rv) |
| Sort PriorityQueue |
| end for |
| end for |
| end while |
| //Step2: Learner Profile Normalization |
| for each Lj ∈ L do |
| P(Rv)= P(Rv)+ Activation(Rv) |
| //normalization factor |
| P(Rv) = P(Rv)*k //normalization |
| Pv,j=P(Rv) |
| end for |
| end |
5.3. Instant Time Availability
5.4. Learner Feature Prediction
5.4.1. Demographic Classification
| Algorithm 2 New Learner Classification (One-against-All) |
| Input: Sample (Current learner set L), Lables y ( where yi is the label for a sample learner Li and yi ∈ {1,2,…K} ), Training Algorithm F, a new learner Lj |
| Output: Category of the new learner Lj, Cj |
| begin: |
| for each k in {1,2,…K} do |
| set a new label vector zi for yi, |
| if (yi=k) then |
| zi=1 |
| else |
| zi=0 |
| end if |
| Ck=F(L,zi) //use binary classification technique to produce classifiers |
| end for |
| for Lj ∈ Ldo |
| end for |
| output Cj =k //category of the new learner Lj |
| end |
| Algorithm 3 Neighbourhood Calculation |
| Input: new learner set N and Existing learner set L |
| Output: set of neighbours, NBj, of a new learnerLj |
| begin: Build a binary classifier |
| Execute the one-against-all model//as in Algorithm 2 |
| Build the ensemble method of multiclass classifier//categorize new learners |
| for each Lj in N do |
| NBj=null |
| Predict Cj// Lj’s category |
| for each Li in l do |
| Retrieve Ci |
| if Cj== Ci then |
| NBj.add(Li) |
| end if |
| end for |
| end for |
| end |
5.4.2. Similarity Measure between Two Learners
5.4.3. Distraction Prediction
5.5. Integration of Recommendation Results
5.5.1. Downwards Propagation
5.5.2. Micro OER Sorting Rules
- If there is a RequiredSequence relation between these two micro OERs, the prerequisite one is placed above (refer to Section 4.1.1).
- If in the preference regarding these two OERs, Pu,j, Pw,j, the former is higher than the latter one, then MRu is above MRw.
- If, in absolute terms, the confidence degree CD(Pu,j) is high and the CD(Pw,j) is low, then MRu is above MRw.
- If there is a RecommendedSequence relation between these two micro OERs, the one which is suggested to be accessed first is placed above (refer to Section 4.1.1).
- The micro OER which is more related to the learner’s education background, or falls in relevant disciplines or inter-disciplines, is placed with priority if the disciplinary difference between these two candidate micro OERs is obvious.
- Otherwise, the recommended micro OER list is randomly ordered if none of the above rules applies.
5.5.3. Recommendation Results Optimization
| Algorithm 4 Micro OER Recommendation in a Cold Start Condition |
| Input: Pu,j (the Learner Lk’s predicted reference to the micro OER MRu), Dj,Loa (predicted distraction level), CD(Pu,j) and CD(Di,Loa) (their confidence degree), RAu (the degree of required attention of MRu), TAj (the instant time availability), rules (1st–6th) |
| Output: the tag of a micro OER which acts as the first delivery |
| begin: Randomly generate candidate learning paths as chromsomes |
| for each chromosome k do |
| Select micro OER it contains |
| for each MRu in a chromosome k, |
| Caculate its Pu,j and CD(Pu,j). |
| Import Dj,Loa , CD(Di,Loa) and RAu |
| Caculate its RTu,j |
| end for |
| Calculate k’s VDk |
| Use Equation (8) to evaluate its fitness η |
| end for |
| while iteration times < max iteration time do |
| apply heuristic approach to generate new candidate solutions |
| for each new chromosome k’ do |
| check time length of the first micro OER in k’, |
| if is in the range of TAj |
| keep k’ |
| otherwise |
| reject k’ |
| end if |
| evaluate the fitness of k’, η, using Equation (8) |
| end for |
| replace chromosomes with higher η values |
| end while |
| output the selected chromosome k’’with minimum η and satisfied |
| select the first micro OER in k’’as the first delivery |
| end |
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hilton, J. Open Educational Resources and College Textbook Choices: A Review of Research on Efficacy and Perceptions. Educ. Technol. Res. Dev. 2016, 64, 573–590. [Google Scholar] [CrossRef]
- Baggaley, J. MOOC Rampant. Distance Educ. 2013, 34, 368–378. [Google Scholar] [CrossRef]
- Hylen, J.; Damme, D.V.; Mulder, F.; D’Antoni, S. Open Educational Resources: Analysis of Responses to the OECD Country Questionnaire; OECD Education Working Papers; OECD: Paris, France, 2012. [Google Scholar]
- Nawrot, I.; Doucet, A. Building engagement for MOOC students: Introducing support for time management on online learning platforms. In Proceedings of the WWW’14 Companion, Seoul, Korea, 7–11 April 2014. [Google Scholar]
- Warrd, I.; Koutropoulos, A.; Keskin, N.O.; Abajian, S.C.; Hogue, R.; Rodriguez, C.O.; Gallagher, M.S. Exploring the MOOC format as a pedagogical approach for m-learning. In Proceedings of the 10th World Conference on Mobile and Contextual Learning, Beijing, China, 19–21 October 2011. [Google Scholar]
- Sun, G.; Cui, T.; Chen, S.; Guo, W.; Shen, J. MLaaS: A cloud based system for mobile micro learning in MOOC. In Proceedings of the 4th IEEE International Conference on Mobile Service (MS), New York, NY, USA, 27 June–2 July 2015; pp. 120–127. [Google Scholar]
- Sun, G.; Cui, T.; Li, K.; Xu, D.; Chen, S.; Shen, J.; Guo, W. Towards bringing adaptive micro learning into MOOC courses. In Proceedings of the 15th IEEE International Conference on Advanced Learning Technologies (ICALT), Hualien, Taiwan, 6–9 July 2015. [Google Scholar]
- Dennen, V.P.; Hao, S. Intentionally Mobile Pedagogy: The M-COPE Framework for Mobile Learning in Higher Education. Technol. Pedagog. Educ. 2014, 23, 397–419. [Google Scholar] [CrossRef]
- Trifonova, A.; Ronchetti, M. Mobile learning: Is anytime + anywhere = always online? In Proceedings of the 6th IEEE International Conference on Advanced Learning Technologies, Kerkrade, The Netherlands, 5–7 July 2006. [Google Scholar]
- Attewell, J. A technology update and m-learning project summary. In Mobile Technology and Learning; Learning and Skills Development Agency: London, UK, 2005. [Google Scholar]
- Wu, H.; Hamdi, L.; Mahe, N. Tango: A flexible mobility-enabled architecture for online and offline mobile enterprise applications. In Proceedings of the 11th International Conference on Mobile Data Management, Kansas City, MO, USA, 23–26 May 2010. [Google Scholar]
- Lee, M.J.W.; McLoughlin, C. Teaching and Learning in the Web 2.0 Era: Empowering Students through Learner-Generated Content. Int. J. Instr. Technol. Distance Learn. 2007, 4, 21–24. [Google Scholar]
- Kovachev, D.; Cao, Y.; Klamma, R.; Jarke, M. Learn-as-you-go, new ways of cloud based micro-learning for the mobile web. In Proceedings of the 10th International Conference on Web-based Learning, Hongkong, China, 8–10 December 2011. [Google Scholar]
- Bruck, P.A.; Motiwalla, L.; Foerster, F. Mobile learning with micro-content: A framework and evaluation. In Proceedings of the 25th Bled eConference, Bled, Slovenia, 18–21 June 2012; pp. 527–542. [Google Scholar]
- Hug, T.; Lindner, M. ML: Emerging concepts, practices and technologies after e-Learning. In Proceedings of the Micro Learning, Innsbruck, Austria, 23–24 June 2005. [Google Scholar]
- Souza, M.I.; Amaral, S.F.D. Educational Micro content for Mobile Learning Virtual Environments. Creative Educ. 2014, 5, 672–681. [Google Scholar] [CrossRef]
- Sun, Z.; Shen, J. A high performance peer to cloud and peer model augmented with hierarchical secure communications. J. Syst. Softw. 2013, 86, 1790–1796. [Google Scholar] [CrossRef]
- Shen, J.; Beydoun, G.; Yuan, S.; Low, G. Comparison of bio-inspired algorithms for peer selection in services composition. In Proceedings of the IEEE International Conference on Services Computing, Washington, DC, USA, 4–9 July 2011; pp. 250–257. [Google Scholar]
- Sun, G.; Cui, T.; Guo, W.; Beydoun, G.; Xu, D.; Shen, J. Micro learning adaptation in MOOC: A software as a service and a personalized learner model. In Proceedings of the 14th International Conference on Web-based Learning (ICWL), Guangzhou, China, 5–8 November 2015; pp. 174–184. [Google Scholar]
- Wang, L.; Shen, J. Multi-phase ant colony system for multi-party data-intensive service provision. IEEE Trans. Serv. Comput. 2016, 9, 264–276. [Google Scholar] [CrossRef]
- Sun, G.; Cui, T.; Yong, J.; Shen, J.; Chen, S. MLaaS: A Cloud-based System for Delivering Adaptive Micro Learning in Mobile MOOC Learning. IEEE Trans. Serv. Comput. 2015. [Google Scholar] [CrossRef]
- Starr, R.R.; de Oliveira, J.M.P. Concept Maps as the First Step in an Ontology Construction Method. Inf. Syst. 2013, 38, 771–783. [Google Scholar] [CrossRef]
- Xu, D.; Wijesooriya, C.; Wang, Y.-G.; Beydoun, G. Outbound logistics exception monitoring: A multi-perspective ontologies approach with intelligent agents. Expert Syst. Appl. 2011, 38, 13604–13611. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, and Productivity. 2011. Available online: http://abesit.in/wp-content/uploads/2014/07/big-data-frontier.pdf (accessed on 26 May 2017).
- Romero, C.; Ventura, S. Educational Data Mining: A Review of the State-of-the-Art. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Sieg, A.; Mobasher, B.; Burke, R. Ontology-based collaborative recommendation. In Proceedings of the 8th Workshop on Intelligent Techniques for Web Personalization and Recommender Systems, Big Island, HI, USA, 20 June 2010; pp. 20–32. [Google Scholar]
- Miranda, S.; Mangione, G.R.; Orciuoli, F.; Gaeta, M.; Loia, V. Automatic generation of assessment objects and remedial works for MOOCs. In Proceedings of the 12th International Conference on Information Technology Based Higher Education and Training, Antalya, Turkey, 10–12 Octorber 2013. [Google Scholar]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the Cold Start Problem in Recommender Systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Sun, G.; Cui, T.; Beydoun, G.; Chen, S.; Shen, J. Profiling and supporting adaptive micro learning on open education resources. In Proceedings of the 4th International Conference on Advanced Cloud and Big Data (CBD), Chengdu, China, 13–14 August 2016; pp. 158–163. [Google Scholar]
- Cambria, E.; Olsher, D.; Rajagopal, D. SenticNet3: A common and common-sense knowledge base for cognition-driven sentiment analysis. In Proceedings of the 28th AAAI Conference on Artificial Intelligence (AAAI), Quebec, QC, Canada, 27–31 July 2014; pp. 1515–1521. [Google Scholar]
- Dou, D.; Wang, H.; Liu, H. Semantic data mining: A survey of ontology-based approaches. In Proceedings of the 9th IEEE International Conference on Semantic Computing (ICSC), Anaheim, CA, USA, 7–9 February 2015; pp. 244–251. [Google Scholar]
- Miranda, S.; Albano, G. Personalized Learning in Mathematics. J. e-Learn. Knowl. Soc. 2015, 11, 25–42. [Google Scholar]
- Moreno, A.; Valls, A.; Isern, D.; Marin, L.; Borras, J. SigTur/E-Destination: Ontology-Based Personalized Recommendation of Tourism and Leisure Activities. Eng. Appl. Artif. Intell. 2013, 26, 633–651. [Google Scholar] [CrossRef]
- Capuano, N.; Dell’Angelo, L.; Orciuoli, F. Ontology extraction from existing education al content to improve personalized e-Learning experiences. In Proceedings of the 3rd IEEE International Conference on Semantic Computing, Berkeley, CA, USA, 14–16 September 2009; pp. 577–582. [Google Scholar]
- Markellou, P.; Mousourouli, I.; Spiros, S.; Tsakalidis, A. Using semantic web mining technologies for personalized e-learning experiences. Proceedings of The Web-based Education, Grindelwald, Switzerland, 21–23 February 2005; pp. 461–826. [Google Scholar]
- Milgram, J.; Cheriet, M.; Sabourin, M. One against one or one against all: Which one is better for handwriting recognition with SVMs. In Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition, La Baule, France, 23–26 October 2006. [Google Scholar]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An Overview of Ensemble Methods for Binary Classifiers in Multi-class Problems: Experimental Study on One-vs.-One and One-vs.-All Schemes. Pattern Recognit. 2011, 44, 1761–1766. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Polat, K.; Gunes, S. A Novel Hybrid Intelligent Method Based on C4.5 Decision Tree Classifier and One-against-All Approach for Multi-class Classification Problems. Expert Syst. Appl. 2009, 36, 1587–1592. [Google Scholar] [CrossRef]
- Dalton, L.A.; Dougherty, E.R. Optimal Classifiers with Minimum Expected Error within a Bayesian Framework-Part II: Properties and Performance Analysis. Pattern Recognit. 2013, 46, 1288–1300. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Purpose |
|---|---|
| Learners’ exact time of logon/out for each time | To know how long they stay online each time |
| The IP address or gateway information of their internet connection | To know their exact learning location and surroundings |
| Mobile device information, mobile operator information and mobile OSs | To know their general situation |
| Their personal enrollment information (full time or part time, nationality) | To know their learning time availability, organization and language skills |
| Their residential information (session address and permanent address) | To understand their distance to campus and the potential modes of transportation they adopt) |
| Subjects they have chosen (current) | To know their academic background and field |
| Subjects they have chosen (historical) | To know their academic background and field |
| Historical grades | To know their academic background and infer level of pre-knowledge |
| Course materials they have accessed (material type, topic, length, requirement associated with them) | To know their learning habits (how they prefer learning resources to be passed on) |
| Course requirement/milestones set in LMS (by instructor) | To know the suggested learning schedule |
| Their detailed learning activities (What they do when staying online and how long they spend on each specific learning activity, type of resource they access for each specific time) | To know their learning habits, learning engagements, learning speed and so on. |
| Their interactions with LMS and learner-generated content (from forum and thread, etc.) | To know their preferences, interests and to measure their engagement. |
| Frequencies of their participation in interactive learning activities (e.g., forum, thread) | To know their engagement |
| Extent of completeness for each learning activity | To know whether they finished an entire step of learning or drop off halfway |
| The learning paths they have gone through (the sequence of their access of learning resources over LMS) | To further establish optimal learning paths |
| Their learning achievement (grades and final marks if possible) | To know how their learning behaviors affect their learning outcomes |
| Groups or teams they have participated in | To know their collaborative learning performance and similarities/changes of learning time frame among learners |
| Technique | Object | Purpose |
|---|---|---|
| Prediction | Well-defined micro OERs | To establish a recommendation model for students in similar situations in the future |
| Structure Discovery | Well-defined micro OERs | For web documents using clustering methods in order to personalize e-learning based on maximal frequent item sets |
| Latent Knowledge Estimation | Non-micro OERs | To discover which stages of them are generally finished within relatively larger time length |
| Structure Discovery | Non-micro OERs | To determine time spans where the pauses made by learners usually fall in |
| Factor Analysis | Non-micro OERs | To find out the actual reasons why learners spent more time on these stages and made such pauses |
| Latent Knowledge Estimation | Non-micro OERs | To measure potential suitability of micro learning (from learners’ frequencies of using fragmented time pieces) |
| Factor Analysis | Non-micro OERs | To identify resources’ suitability for micro learning, for example, whether hands-on practice is needed, or whether the OER delivery is necessarily associated with lots of writing or computation work which is inconvenient to complete on mobile devices |
| Prediction | Subscription OERs | To determine when to push information to learners in the best timing and remind them |
| Clustering | All micro OERs | To determine their correlations for better repository purpose |
| Relationship Mining | Time Availability | To discover the correlation between their overall time availability and learners’ types |
| Clustering/Prediction | Time Availability | To involve similar learners into cohorts and build a potential time frame for their overall learning schedule |
| Latent Knowledge Estimation | Learning habit (learning time distribution) | To discover whether there are regular patterns of time organization within time frame among learners in or across cohorts |
| Latent Knowledge Estimation | Learners’ latest learning contents and activities | To retrieve and profile learners’ learning recentness |
| Categorization | Learning habits | To set up a unique learning habit summary for each learner |
| Relationship Mining | Learners’ learning location data | To know the degree of distraction and how it interrelates to disruption from external environment |
| Relationship Mining | Learners’ mobile app usage | To know the degree of distraction and how it interrelates to disruption from the content on mobile internet |
| Social Network Analysis | OERs in affiliated social networks | To distinguish information that can be useless, harmful and may cause time wasted for learners. |
| Social Network Analysis | Other content in affiliated social networks | To screen well-recognized information in order to recommend to learners as their learning augmentation besides the OERs (text mining technique employed) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, G.; Cui, T.; Beydoun, G.; Chen, S.; Dong, F.; Xu, D.; Shen, J. Towards Massive Data and Sparse Data in Adaptive Micro Open Educational Resource Recommendation: A Study on Semantic Knowledge Base Construction and Cold Start Problem. Sustainability 2017, 9, 898. https://doi.org/10.3390/su9060898
Sun G, Cui T, Beydoun G, Chen S, Dong F, Xu D, Shen J. Towards Massive Data and Sparse Data in Adaptive Micro Open Educational Resource Recommendation: A Study on Semantic Knowledge Base Construction and Cold Start Problem. Sustainability. 2017; 9(6):898. https://doi.org/10.3390/su9060898
Chicago/Turabian StyleSun, Geng, Tingru Cui, Ghassan Beydoun, Shiping Chen, Fang Dong, Dongming Xu, and Jun Shen. 2017. "Towards Massive Data and Sparse Data in Adaptive Micro Open Educational Resource Recommendation: A Study on Semantic Knowledge Base Construction and Cold Start Problem" Sustainability 9, no. 6: 898. https://doi.org/10.3390/su9060898