An Asymmetric Distribution with Heavy Tails and Its Expectation–Maximization (EM) Algorithm Implementation


1
Departamento de Matemáticas, Facultad de Ciencias Básicas, Universidad de Antofagasta, Antofagasta 1240000, Chile
2
Departamento de Ciencias Matemáticas y Físicas, Facultad de Ingeniería, Universidad Católica de Temuco, Temuco 4780000, Chile
3
Departamento de Matemática, Facultad de Ingeniería, Universidad de Atacama, Copiapó 1530000, Chile
*
Author to whom correspondence should be addressed.
Symmetry 2019, 11(9), 1150; https://doi.org/10.3390/sym11091150
Submission received: 8 August 2019
/
Revised: 31 August 2019
/
Accepted: 2 September 2019
/
Published: 10 September 2019
(This article belongs to the Special Issue Symmetric and Asymmetric Distributions: Theoretical Developments and Applications)
Abstract
:In this paper we introduce a new distribution constructed on the basis of the quotient of two independent random variables whose distributions are the half-normal distribution and a power of the exponential distribution with parameter 2 respectively. The result is a distribution with greater kurtosis than the well known half-normal and slashed half-normal distributions. We studied the general density function of this distribution, with some of its properties, moments, and its coefficients of asymmetry and kurtosis. We developed the expectation–maximization algorithm and present a simulation study. We calculated the moment and maximum likelihood estimators and present three illustrations in real data sets to show the flexibility of the new model.
1. Introduction
In recent years, for data with positive support, specifically, lifetime, or reliability, the half-normal (HN) model has been widely used. The probability density function (pdf) is given by
where is the scale parameter and represents the standard normal pdf. We denote this by writing .
Some generalizations for this model are proposed by Cooray and Ananda [1], Cordeiro et al. [2], Bolfarine and Gómez [3] and Gómez and Vidal [4].
Olmos et al. [5] extended the HN distribution by incorporating a kurtosis parameter q, with the purpose of obtaining heavier tails, i.e., it has greater kurtosis than the base model. They called this model the slashed half-normal (SHN) distribution. Its construction is based on considering the quotient of two independent random variables, with random variable in the numerator and the in the denominator (See Rogers and Tukey [6] and Mosteller and Tukey [7] for more details). Thus a model is obtained that has more flexible coefficients of asymmetry and kurtosis than the HN model. We say that a random variable T follows a SHN if its pdf is given by
where is a scale parameter, is a kurtosis parameter, is the cumulative distribution function (cdf) of the gamma distribution and is the pdf of the gamma model with shape and rate parameters a and b, respectively.
Reyes et al. [8] introduced the modified slash (MS) distribution. We say that M has a MS distribution if
the construction of which is based on considering an exponential (Exp) distribution with parameter 2 in the denominator, i.e., they consider that . The motivation of the selection of the distribution is given in Reyes et al. [8]. The result of this work shows that the MS model has a greater coefficient of kurtosis and this characteristic is very important for modeling data sets when they contain atypical observations.
The principal goal of this article is to use the idea published by Reyes et al. [8] to construct an extension of the half-normal model with a greater range in the coefficient of kurtosis than the SHN model, in order to use it to model atypical data. This will allow us obtain a new model generated on the basis of a scale mixture between an HN and a Weibull (Wei) distribution.
The rest of the paper is organized as follows: Section 2 contains the representation of this model and we generate the density of the new family, its basic properties and moments, and its coefficients of asymmetry and kurtosis. In Section 3 we make inferences using the moments and maximum likelihood (ML) methods. In Section 4 we implement the expectation–maximization (EM) algorithm. In Section 5 we carry out a simulation study for parameter recovery. We show three illustrations in real datasets in Section 6 and finally in Section 7 we present our conclusions.
2. An Asymmetric Distribution
In this section we introduce the representation, its pdf, and some important properties and graphs to show the flexibility of the new model.
2.1. New Distribution
The representation of this new distribution is
where and are independent, , . We call the distribution of T the modified slashed half-normal (MSHN) distribution. This is denoted by .
2.2. Density Function
The following Proposition shows the pdf of the MSHN distribution with scale parameter and kurtosis parameter q, generated using the representation given in (3).
Proposition 1.
Proof.
Using the stochastic representation given in (3) and the Jacobian method, we obtain that the density function associated with T is given by
Making the change of variable we have,
Hence, applying the Lemma 1 as set forth in the Appendix A, we obtain the result. □
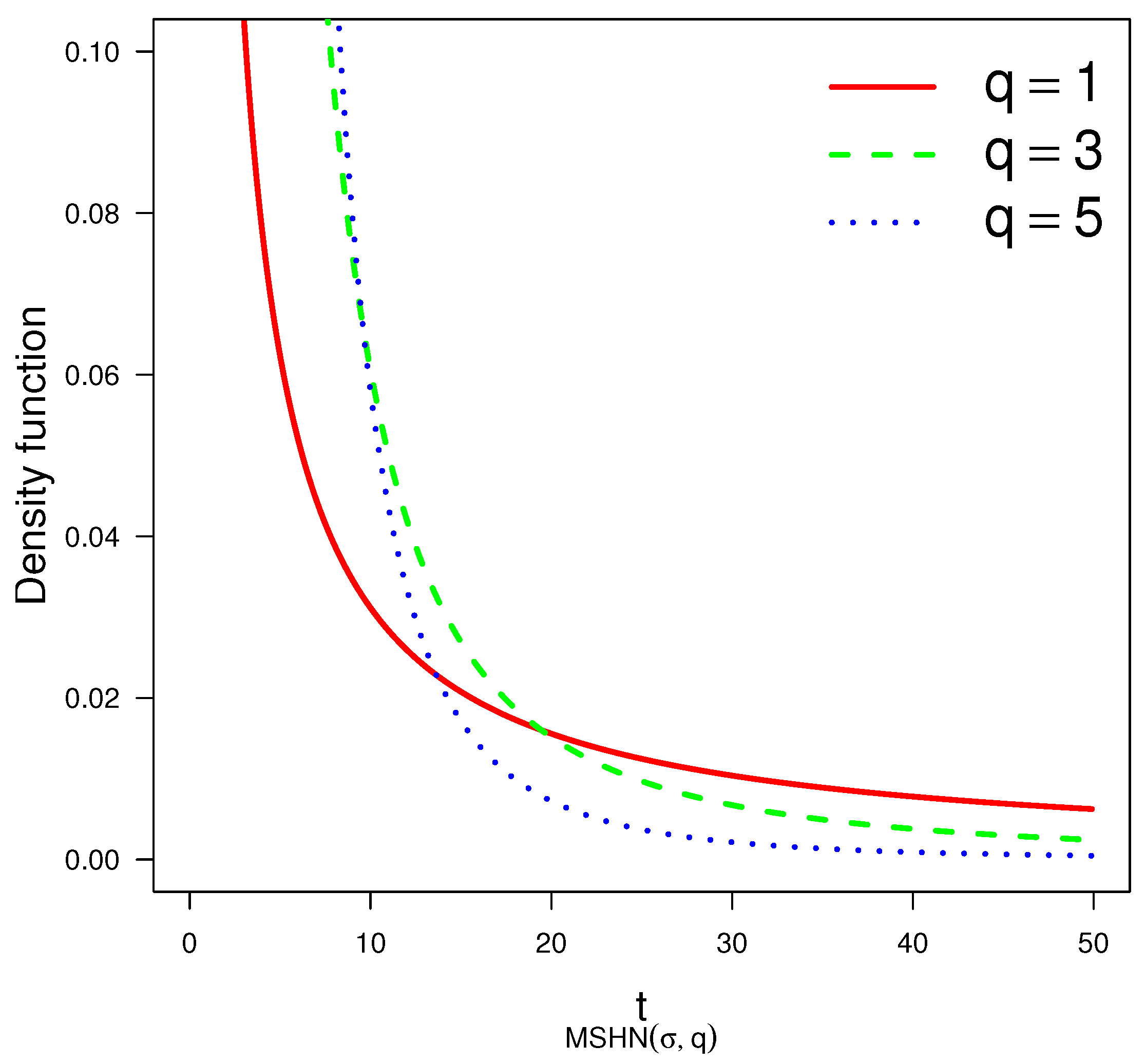
Figure 1 depicts plots of the density of the MSHN distribution for different values of parameter q.
We perform a brief comparison illustrating that the tails of the MSHN distribution are heavier than those of the SHN distribution.
Table 1 shows the tail probability for different values in the SHN and MSHN models. It is immediately apparent that the MSHN tails are heavier than those of the SHN distribution.
2.3. Properties
In this sub-section we study some properties of the MSHN distribution.
Proposition 2.
Let , then when the density is
where is the cdf of the standard normal.
Proof.
Using Proposition 1 for , we have,
Changing the variable we obtain the result. □
Proposition 3.
If and then .
Proof.
Since the marginal pdf of T is given by
and using the Lemma 1 in the Appendix A, the result is obtained. □
Proposition 4.
Let . If then T converges in law to a random variable .
Proof.
Let and , where and .
We study the convergence in law of T, since then , we have that . If then , i.e., we have 1 (see Lehmann [9]).
Since , by applying Slutsky’s Lemma (see Lehmann [9]) to , we have
that is, for increasing values of q, T converges in law to a distribution. □
Remark 1.
Proposition 2 shows us that the distribution has a closed-form expression. Proposition 3 shows that an distribution can also be obtained as a scale mixture of an HN and a Wei distribution. This property is very important since it makes it possible to generate random numbers and implement the EM algorithm. Proposition 4 implies that, if then the cdf of an model approaches to the cdf of a distribution.
2.4. Moments
In this sub-section, the following proposition shows the computation of the moments of a random variable . Hence, it also displays the coefficients of asymmetry and kurtosis.
Proposition 5.
Let . Then the r-th moment of T is given by
where denotes the gamma function.
Proof.
Let and using Proposition 3, we have
where , is the r-th moment of the inverse Weibull distribution. □
Corollary 1.
Let . Then the expectation and variance of T are given respectively by
Corollary 2.
Let . Then the coefficients of asymmetry () and kurtosis () are given by
Remark 2.
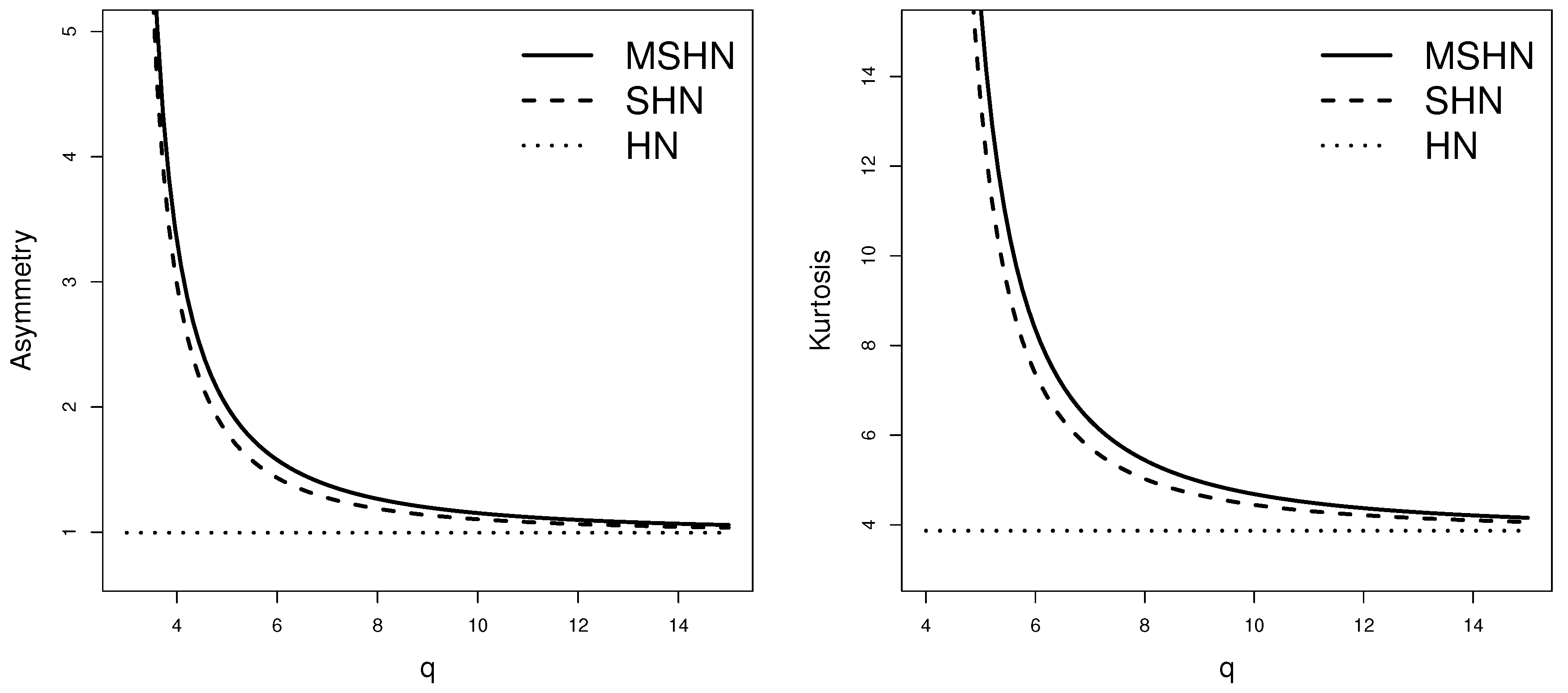
Figure 2 shows graphs of the coefficients of the MSHN distribution compared with those of the SHN distribution. Note that the MSHN distribution presents higher asymmetry and kurtosis values than the SHN distribution. Furthermore, in both distributions when the coefficients of asymmetry and kurtosis converge to and , respectively; they coincide with the coefficients of the HN distribution.
3. Inference
Proposition 6.
Let be a random sample of size n of the distribution. Then for , the moment estimators of σ and q are given by
where is the mean of the sample and is the mean of the sample for the square of the observations.
Proof.
From Proposition 5, and considering the first two equations in the moments method, we have
Solving the first equation above for we obtain given in (9). Substituting in the second equation above, we obtain the result given in (10). □
4. Em Algorithm
The EM algorithm (Dempster et al. [10]) is a useful method for ML estimation in the presence of latent variables.
To facilitate the estimation process, we introduce latent variables through the following hierarchical representation of the MSHN model:
In this setting, we have that
Therefore, the complete log-likelihood function can be expressed as
where .
Letting , it follows that the conditional expectation of the complete log-likelihood function has the form
where , with and .
As both quantities and have no explicit forms in the context of the MSHN model, they have to be computed numerically. Thus to compute we use an approach similar to that of Lee and Xu ([11], Section 3.1), i.e., considering to be a random sample from the conditional distribution , then can be approximated as
Therefore, the EM algorithm for the MSHN model is given by
- E-step: Given , calculate , for
- CM-step I: Update
- CM-step II: Fix , update by optimizing , where
The E, CM-I and CM-II steps are repeated until a convergence rule is satisfied, say is sufficiently small. Finally, standard errors (SE) can be estimated using the inverse of the observed information matrix.
Remark 3.
- i.
- For , in M-step reduces to those obtained when the HN distribution is used;
- ii.
- An alternative to the CM-Steps II is obtained considering the idea in Lin et al. ([12], Section 3), by using the following estimation:CML-step: Update by maximizing the constrained actual log-likelihood function, i.e.,
5. Simulation
We present a simulation study to assess the performance of the EM algorithm for the parameters and q in the MSHN model. We consider 1000 samples of three sample sizes generated from the MSHN model: , 50 and 100. To generate the following algorithm was used:
- Simulate and .
- Compute .
For each sample generated, the ML estimates were computed using the EM algorithm. Table 2 shows the mean of the bias estimated for each parameter (bias), its SE and the estimated root of the mean squared error (RMSE). From Table 2, we conclude that the ML estimates are quite stable. The bias is reasonable and diminishes as the sample size is increased. As expected, the terms SE and RMSE are closer when the sample size is increased, suggesting that the SE of the estimators is well estimated.
6. Aplications
In this section we provide three applications to real datasets that illustrate the flexibility of the proposed model.
6.1. Application 1
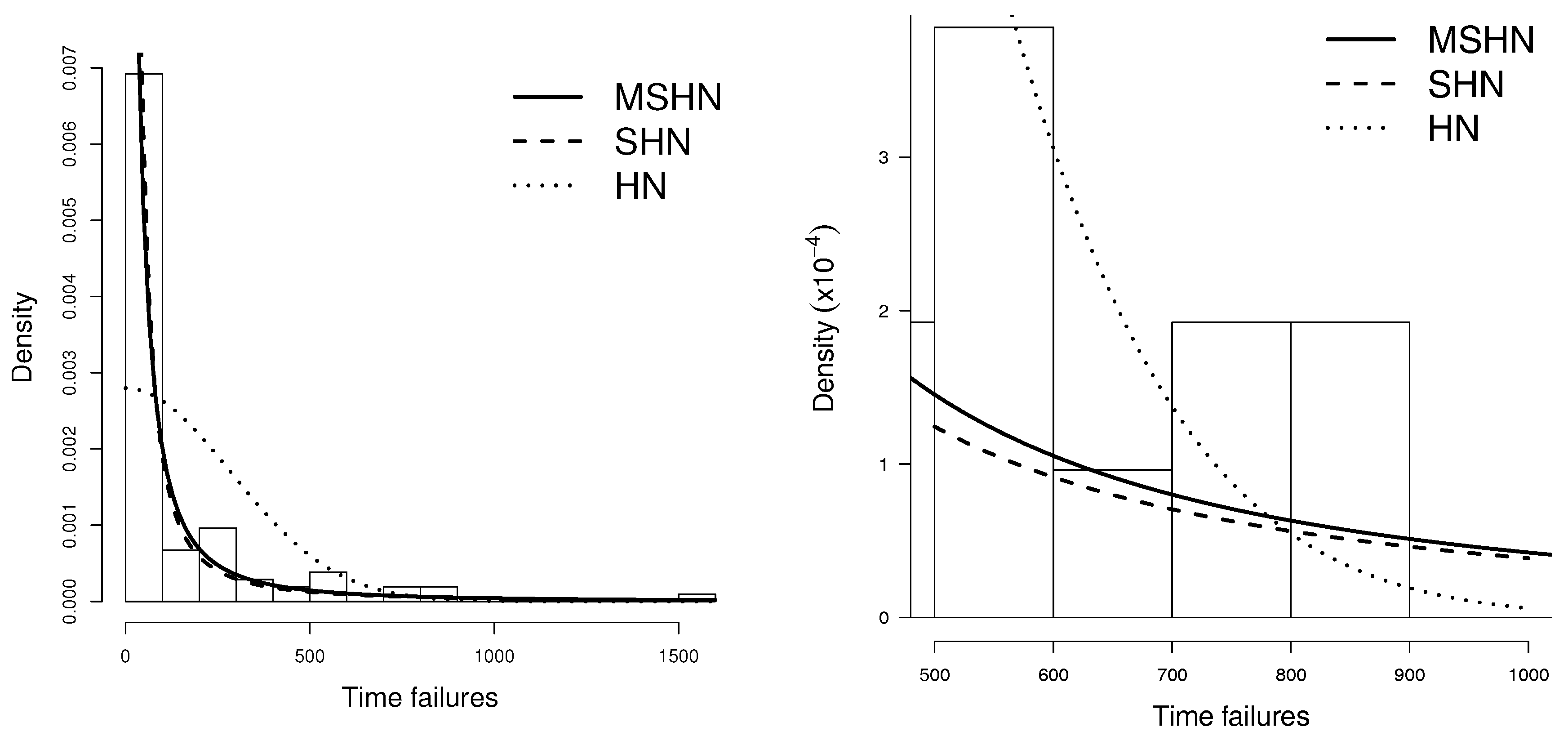
Lyu [13] presents a data set related 104 times with programming in the Centre for Software Reliability (CSR). Some descriptive statistics are: mean = 147.8, variance = 60,071.7, skewness = 3, and kurtosis = 14.6. The moment estimators for the MSHN model were and , which were used as initial values to compute the estimator in Table 3.
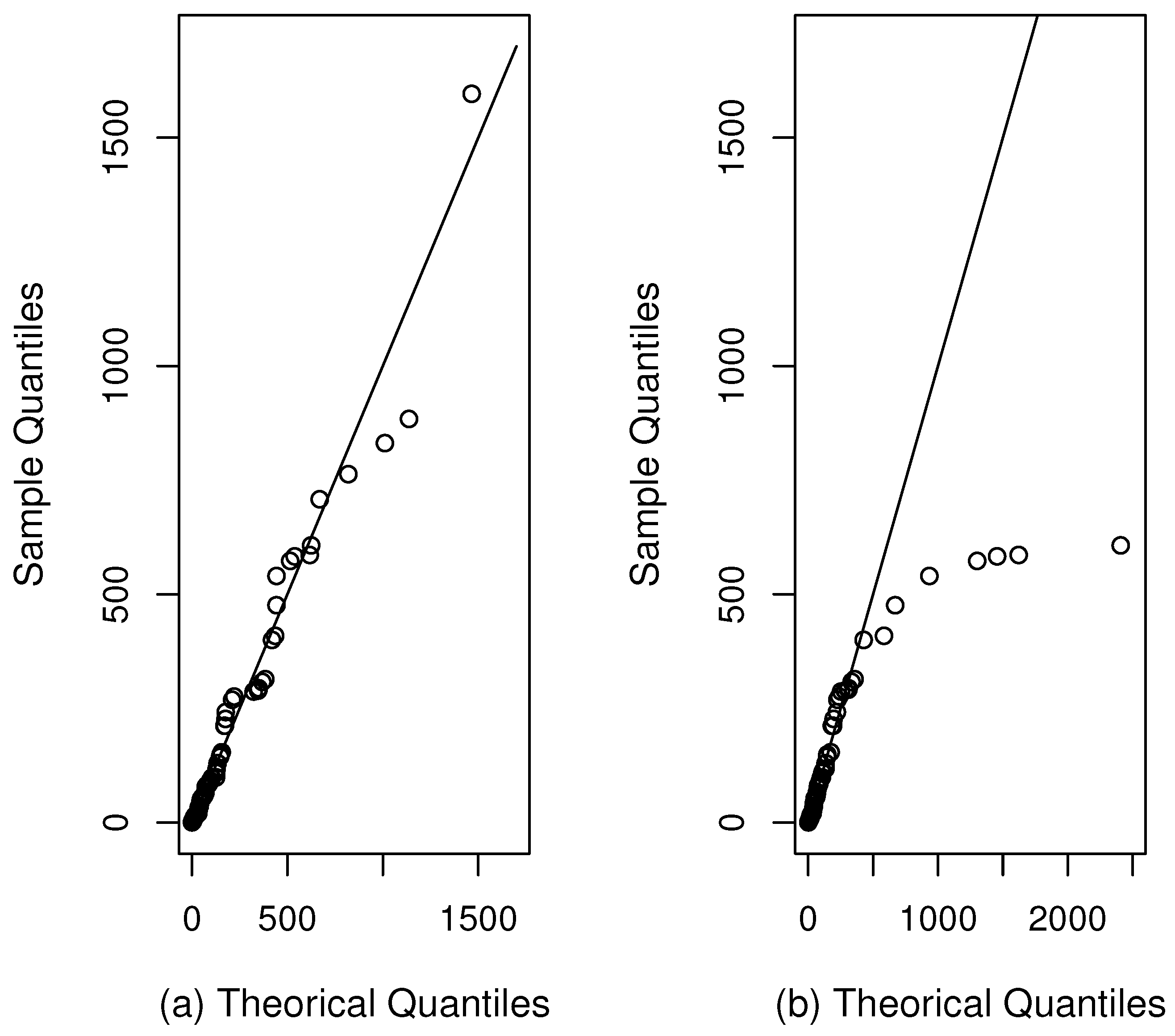
For each distribution we report the estimated log-likelihood. To compare the competing models, we consider the Akaike information criterion (AIC) (Akaike [14]) and the Bayesian information criterion (BIC) (Schwarz [15]), which are defined as and , respectively, where k is the number of parameters in the model, n is the sample size and is the maximum value for the log-likelihood function. Table 4 displays the AIC and BIC for each model fitted. Figure 3 presents the histogram of the data fitted with the HN, SHN and MSHN distributions, provided with the ML estimations. The QQ-plot for the MSHN and SHN distributions are presented in Figure 4.
6.2. Application 2
The second dataset is taken from Von Alven [16], and represents 46 instances of active repairs (in hours) for an airborne communication transceiver. Some descriptive statistics are: mean = 3.607, variance = 24.445, skewness = 2.888, and kurtosis = 11.802.
Initially we computed the moment estimators for the MSHN distribution, obtaining the following estimations: and . We used these estimations as initial values in computing the ML estimators presented in Table 5. For each distribution we report the estimated log-likelihood.
6.3. Application 3
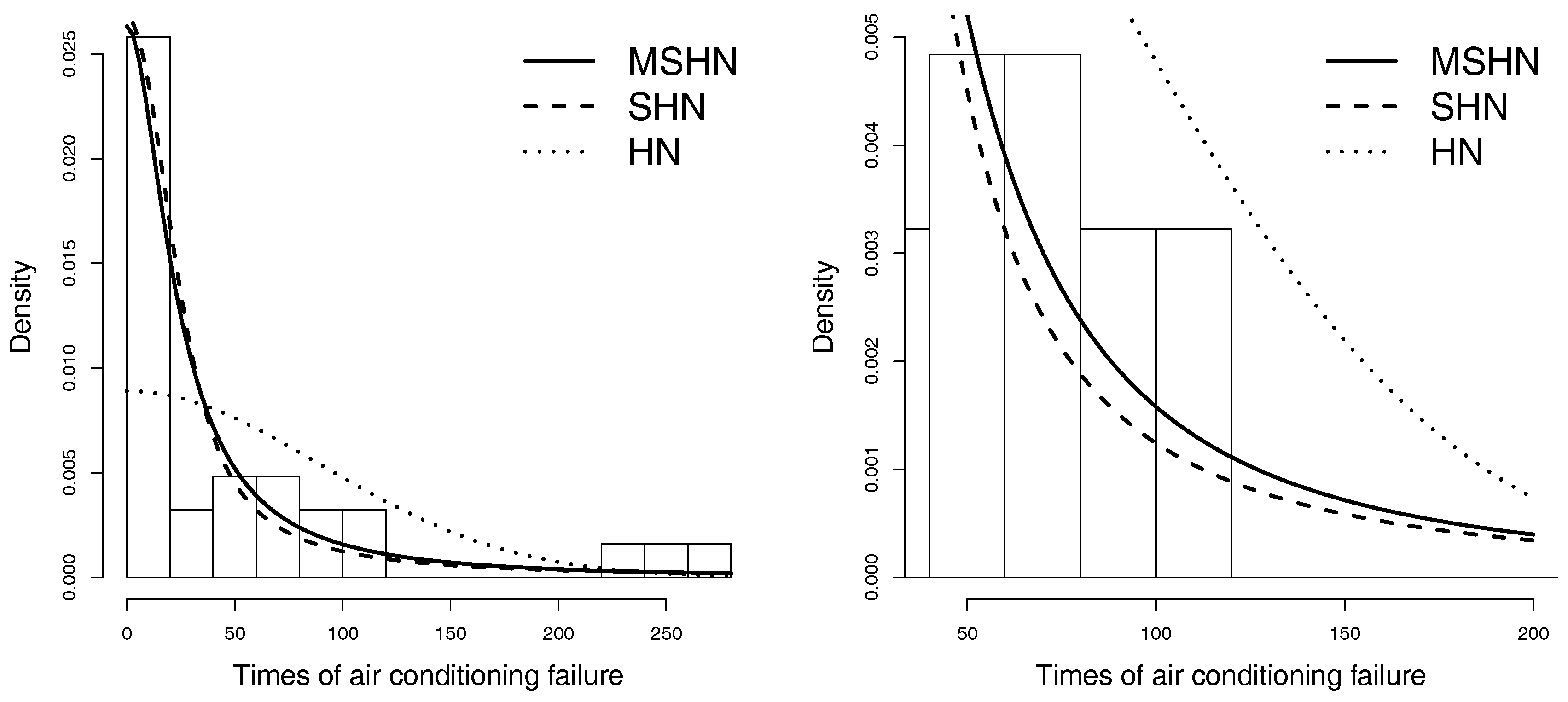
The third data set (Linhart and Zucchini [17]) represents 31 times of air conditioning system failure of an aeroplane. Some descriptive statistics are: mean = 55.35, variance = 5132.503, skewness = 1.805, and kurtosis = 5.293.
Initially we computed the moment estimators for the MSHN distribution, and obtained the following estimations: and . We used these estimations as initial values in computing the ML estimators presented in Table 7. For each distribution we report the estimated log-likelihood.
7. Conclusions
In this paper, we have introduced a new and more flexible model, as it increases kurtosis and contains, as a particular case, the HN distribution. The EM algorithm is implemented, obtaining acceptable results for the maximum likelihood estimators. In applications using real data it performs very well, better than competing models. Some further characteristics of the MSHN distribution are:
- The MSHN distribution has a greater kurtosis than the SHN distribution, as is clearly reflected in Table 1.
- The proposed model has a closed-form expression and presents more flexible asymmetry and kurtosis coefficients than that of the HN model.
- Two stochastic representations for the MSHN model are presented. One is defined as the quotient between two independent random variables: An HN in the numerator and Exp(2) in the denominator. The other shows that the MSHN distribution is a scale mixture of an HN and a Wei distribution.
- Using the mixed scale representation, the EM algorithm was implemented to calculate the ML estimators.
- Results from a simulation study indicate that with a reasonable sample size, an acceptable bias is obtained.
- Three illustrations using real data show that the MSHN model achieves a better fit in terms of the AIC and BIC criteria.
Author Contributions
N.M.O., O.V., Y.M.G. and Y.A.I. contributed significantly to this research article.
Funding
The research of Neveka M. Olmos and Yuri A. Iriarte was supported by SEMILLERO UA-2019. The research of Yolanda M. Gómez was supported by proyecto DIUDA programa de inserción No. 22367 of the Universidad de Atacama.
Acknowledgments
The authors would like to thank the editor and the anonymous referees for their comments and suggestions, which significantly improved our manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Density function of the gamma, exponential and Weibull distributions, respectively, are given by
- Gamma distribution:with, , and .
- Exponential distribution:with, and .
- Weibull distribution:with, , and .
In the following, Lemma presents an important result used in the derivation of the pdf for the MSHN distribution.
Lemma A1.
Considering , and are coprime integers, where , and is the generalized hypergeometric function defined by
where .
References
- Cooray, K.; Ananda, M.M.A. A Generalization of the Half-Normal Distribution with Applications to Lifetime Data. Commun. Stat. Theory Methods 2008, 37, 1323–1337. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Pescim, R.R.; Ortega, E.M.M. The Kumaraswamy Generalized Half-Normal Distribution for Skewed Positive Data. J. Data Sci. 2012, 10, 195–224. [Google Scholar]
- Gómez, Y.M.; Bolfarine, H. Likelihood-based inference for power half-normal distribution. J. Stat. Theory Appl. 2015, 14, 383–398. [Google Scholar] [CrossRef]
- Gómez, Y.M.; Vidal, I. A generalization of the half-normal distribution. Appl. Math. J. Chin. Univ. 2016, 31, 409–424. [Google Scholar] [CrossRef]
- Olmos, N.M.; Varela, H.; Gómez, H.W.; Bolfarine, H. An extension of the half-normal distribution. Stat. Pap. 2012, 53, 875–886. [Google Scholar] [CrossRef]
- Rogers, W.H.; Tukey, J.W. Understanding some long-tailed symmetrical distributions. Stat. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Mosteller, F.; Tukey, J.W. Data Analysis And Regression; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Reyes, J.; Gómez, H.W.; Bolfarine, H. Modified slash distribution. Statistics 2013, 47, 929–941. [Google Scholar] [CrossRef]
- Lehmann, E.L. Elements of Large-Sample Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Statist. Soc. Ser. B 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Lee, S.Y.; Xu, L. Influence analyses of nonlinear mixed-effects models. Comput. Stat. Data Anal. 2004, 45, 321–341. [Google Scholar] [CrossRef]
- Lin, T.I.; Lee, J.C.; Yen, S.Y. Finite mixture modeling using the skew-normal distribution. Stat. Sin. 2007, 17, 909–927. [Google Scholar]
- Lyu, M. Handbook of Software Reliability Engineering; IEEE Computer Society Press: Washington, DC, USA, 1996. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Auto. Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Von Alven, W.H. Reliability Engineering by ARINC; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1964. [Google Scholar]
- Linhart, H.; Zucchini, W. Model Selection; Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 1986. [Google Scholar]
- Prudnikov, A.P.; Brychkov, Y.A.; Marichev, O.I. Integrals and Series; Gordon & Breach Science Publishers: Amsterdam, The Netherlands, 1986. [Google Scholar]
Figure 1.
The density function for different values of parameter q and in the MSHN distribution.

Figure 2.
Graph of the coefficients of asymmetry and kurtosis for the MSHN and SHN distributions.

Figure 3.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.
Figure 3.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.

Figure 4.
QQ plots: (a) MSHN distribution and (b) SHN distribution.

Figure 5.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.
Figure 5.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.

Figure 6.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.
Figure 6.
Histogram fitted with the HN, SHN and MSHN distributions provided with the ML estimations.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Tails comparison for different slashed half-normal (SHN) and modified slashed half-normal (MSHN) distributions.
Table 1.
Tails comparison for different slashed half-normal (SHN) and modified slashed half-normal (MSHN) distributions.
| Distribution | |||||
|---|---|---|---|---|---|
| SHN(1, 0.5) | 0.3781 | 0.3497 | 0.3239 | 0.3009 | 0.2805 |
| MSHN(1, 0.5) | 0.5304 | 0.48289 | 0.4466 | 0.4176 | 0.3936 |
| SHN(1, 1) | 0.1777 | 0.1570 | 0.1385 | 0.1224 | 0.1086 |
| MSHN(1, 1) | 0.3678 | 0.2992 | 0.2519 | 0.2173 | 0.19102 |
| SHN(1, 3) | 0.0350 | 0.0205 | 0.0120 | 0.0044 | 0.0034 |
| MSHN(1, 3) | 0.0901 | 0.0438 | 0.0238 | 0.0142 | 0.0091 |
Table 2.
Maximum likelihood (ML) estimations for parameters and q of the MSHN distribution. Standard error (SE), root of the mean squared error (RMSE).
Table 2.
Maximum likelihood (ML) estimations for parameters and q of the MSHN distribution. Standard error (SE), root of the mean squared error (RMSE).
| True Value | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| q | Estimator | Bias | SE | RMSE | Bias | SE | RMSE | Bias | SE | RMSE | |
| 1 | 1 | 0.178 | 0.430 | 0.528 | 0.122 | 0.320 | 0.378 | 0.089 | 0.206 | 0.279 | |
| q | 0.199 | 0.422 | 0.668 | 0.097 | 0.219 | 0.263 | 0.059 | 0.138 | 0.163 | ||
| 2 | 0.111 | 0.355 | 0.407 | 0.078 | 0.258 | 0.295 | 0.042 | 0.172 | 0.186 | ||
| q | 1.006 | 2.500 | 2.603 | 0.480 | 1.105 | 1.519 | 0.182 | 0.458 | 0.562 | ||
| 5 | 0.026 | 0.277 | 0.239 | 0.033 | 0.222 | 0.189 | 0.023 | 0.159 | 0.149 | ||
| q | 2.227 | 8.833 | 3.871 | 2.012 | 6.743 | 3.550 | 1.333 | 4.092 | 2.905 | ||
| 2 | 1 | 0.284 | 0.835 | 0.973 | 0.192 | 0.617 | 0.665 | 0.104 | 0.414 | 0.481 | |
| q | 0.168 | 0.356 | 0.571 | 0.094 | 0.215 | 0.263 | 0.058 | 0.141 | 0.166 | ||
| 2 | 0.294 | 0.727 | 0.815 | 0.122 | 0.507 | 0.572 | 0.074 | 0.343 | 0.383 | ||
| q | 1.210 | 2.821 | 2.835 | 0.465 | 1.067 | 1.534 | 0.174 | 0.454 | 0.623 | ||
| 5 | 0.057 | 0.544 | 0.454 | 0.066 | 0.441 | 0.371 | 0.044 | 0.305 | 0.290 | ||
| q | 2.456 | 8.991 | 3.934 | 2.089 | 6.712 | 3.615 | 1.545 | 4.150 | 3.075 | ||
| 5 | 1 | 0.834 | 2.111 | 2.548 | 0.494 | 1.527 | 1.826 | 0.386 | 1.038 | 1.233 | |
| q | 0.217 | 0.414 | 0.740 | 0.119 | 0.225 | 0.287 | 0.083 | 0.144 | 0.174 | ||
| 2 | 0.658 | 1.782 | 2.065 | 0.293 | 1.285 | 1.475 | 0.209 | 0.872 | 0.966 | ||
| q | 1.218 | 2.872 | 2.836 | 0.413 | 1.018 | 1.414 | 0.188 | 0.489 | 0.694 | ||
| 5 | 0.094 | 1.379 | 1.160 | 0.146 | 1.096 | 0.950 | 0.123 | 0.779 | 0.731 | ||
| q | 2.266 | 8.894 | 3.880 | 1.952 | 6.526 | 3.557 | 1.370 | 4.118 | 2.948 | ||
Table 3.
ML estimations with the corresponding SE for the models fitted. Half-normal (HN).
| Parameters | HN (SE) | SHN (SE) | MSHN (SE) |
|---|---|---|---|
| 285.191 (19.774) | 20.977 (5.674) | 19.874 (4.867) | |
| - | 0.687 (0.118) | 0.872 (0.115) | |
| Log-likelihood | −663.411 | −605.102 | −600.876 |
Table 4.
The Akaike information criterion (AIC) and the Bayesian information criterion (BIC) for each model fitted.
Table 4.
The Akaike information criterion (AIC) and the Bayesian information criterion (BIC) for each model fitted.
| Criterion | HN | SHN | MSHN |
|---|---|---|---|
| AIC | 1328.822 | 1214.204 | 1205.752 |
| BIC | 1331.466 | 1219.493 | 1211.041 |
Table 5.
ML estimations with the corresponding SE for the models fitted.
| Parameters | HN (SE) | SHN (SE) | MSHN (SE) |
|---|---|---|---|
| 6.07 (0.6335) | 1.6251 (0.4777) | 1.5108 (0.3179) | |
| - | 1.3539 (0.4347) | 1.6365 (0.3425) | |
| Log-likelihood | −116.3881 | −103.1834 | −102.65 |
Table 6.
AIC and BIC for each model fitted.
| Criterion | HN | SHN | MSHN |
|---|---|---|---|
| AIC | 234.7762 | 210.3668 | 209.302 |
| BIC | 236.6048 | 214.0241 | 212.9573 |
Table 7.
ML estimations with the corresponding SE for the models fitted.
| Parameters | HN (SE) | SHN (SE) | MSHN (SE) |
|---|---|---|---|
| 89.616 (11.381) | 13.785 (6.047) | 16.148(5.128) | |
| - | 0.859 (0.285) | 1.233 (0.251) | |
| Log-likelihood | −161.861 | −154.857 | −153.954 |
Table 8.
AIC and BIC for each model fitted.
| Criterion | HN | SHN | MSHN |
|---|---|---|---|
| AIC | 325.7224 | 313.715 | 311.908 |
| BIC | 327.1564 | 316.583 | 314.776 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Olmos, N.M.; Venegas, O.; Gómez, Y.M.; Iriarte, Y.A. An Asymmetric Distribution with Heavy Tails and Its Expectation–Maximization (EM) Algorithm Implementation. Symmetry 2019, 11, 1150. https://doi.org/10.3390/sym11091150
AMA Style
Olmos NM, Venegas O, Gómez YM, Iriarte YA. An Asymmetric Distribution with Heavy Tails and Its Expectation–Maximization (EM) Algorithm Implementation. Symmetry. 2019; 11(9):1150. https://doi.org/10.3390/sym11091150
Chicago/Turabian StyleOlmos, Neveka M., Osvaldo Venegas, Yolanda M. Gómez, and Yuri A. Iriarte. 2019. "An Asymmetric Distribution with Heavy Tails and Its Expectation–Maximization (EM) Algorithm Implementation" Symmetry 11, no. 9: 1150. https://doi.org/10.3390/sym11091150
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.