
Streamflow Predictions in Ungauged Basins Using Recurrent Neural Network and Decision Tree-Based Algorithm: Application to the Southern Region of the Korean Peninsula
 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Watersheds and Data
2.2. Methods
3. Results
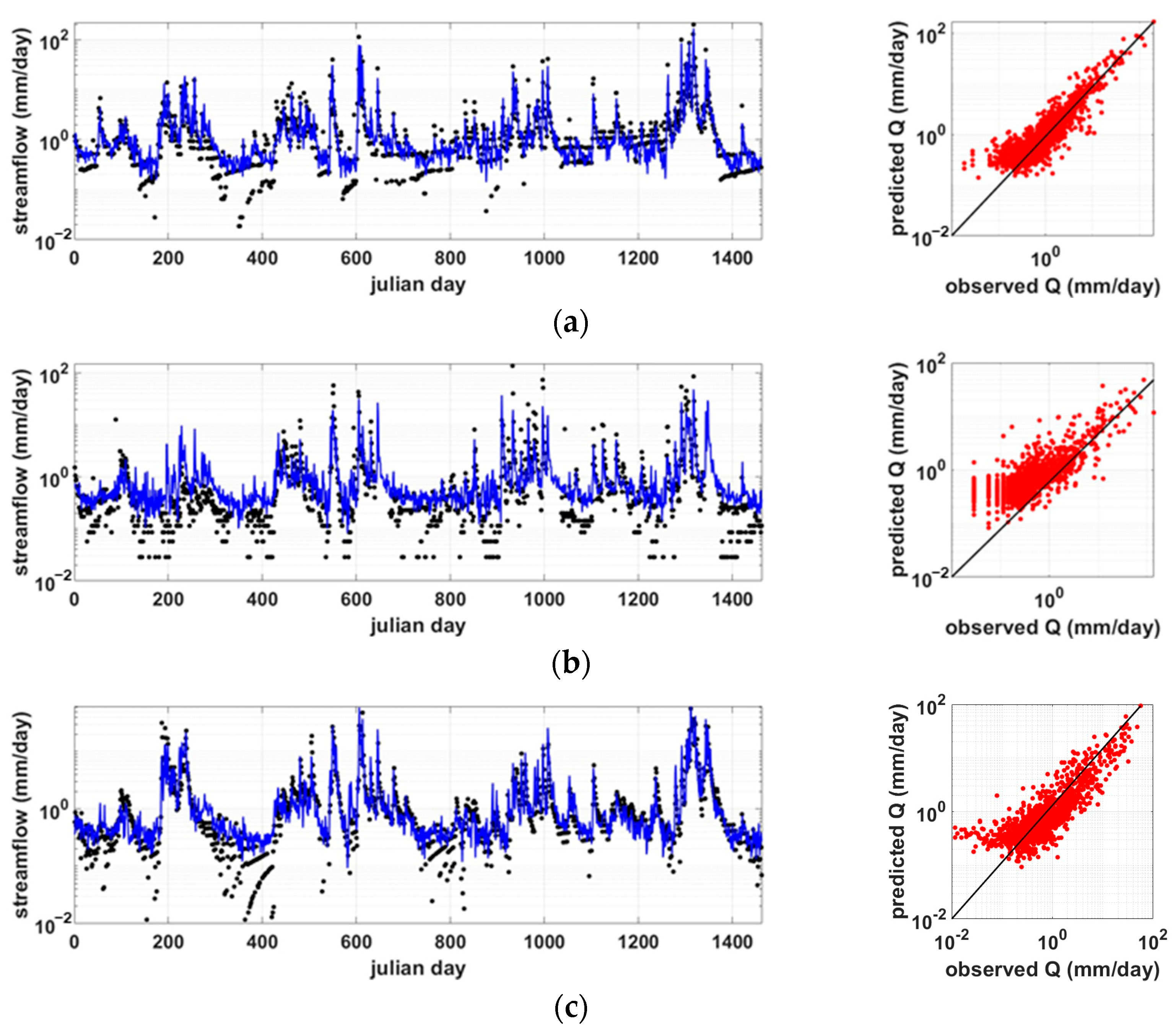
3.1. Predictions in Ungagued Basins Using Meteorological Data and LSTM+RF Combination
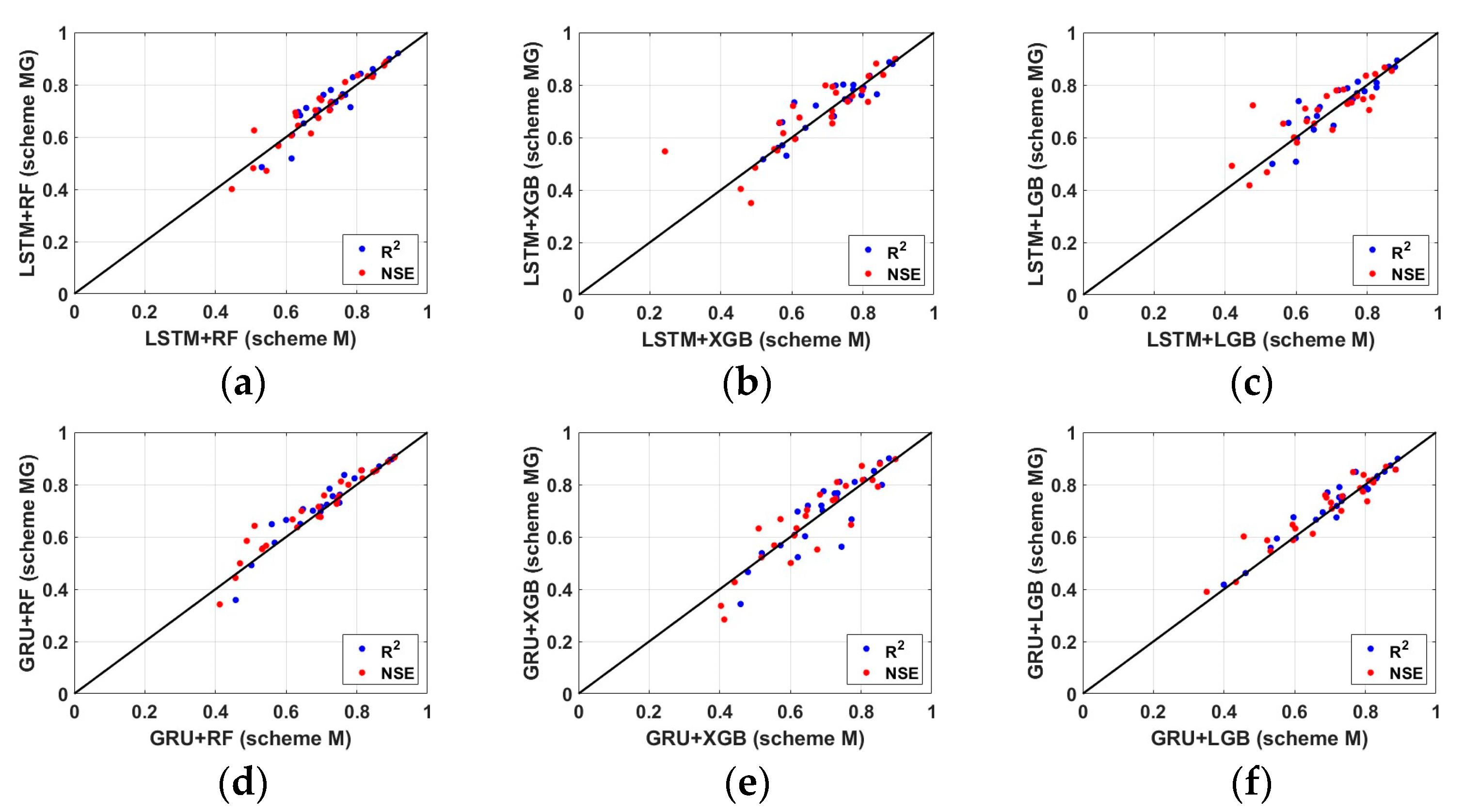
3.2. Comparison of Scheme M and MG
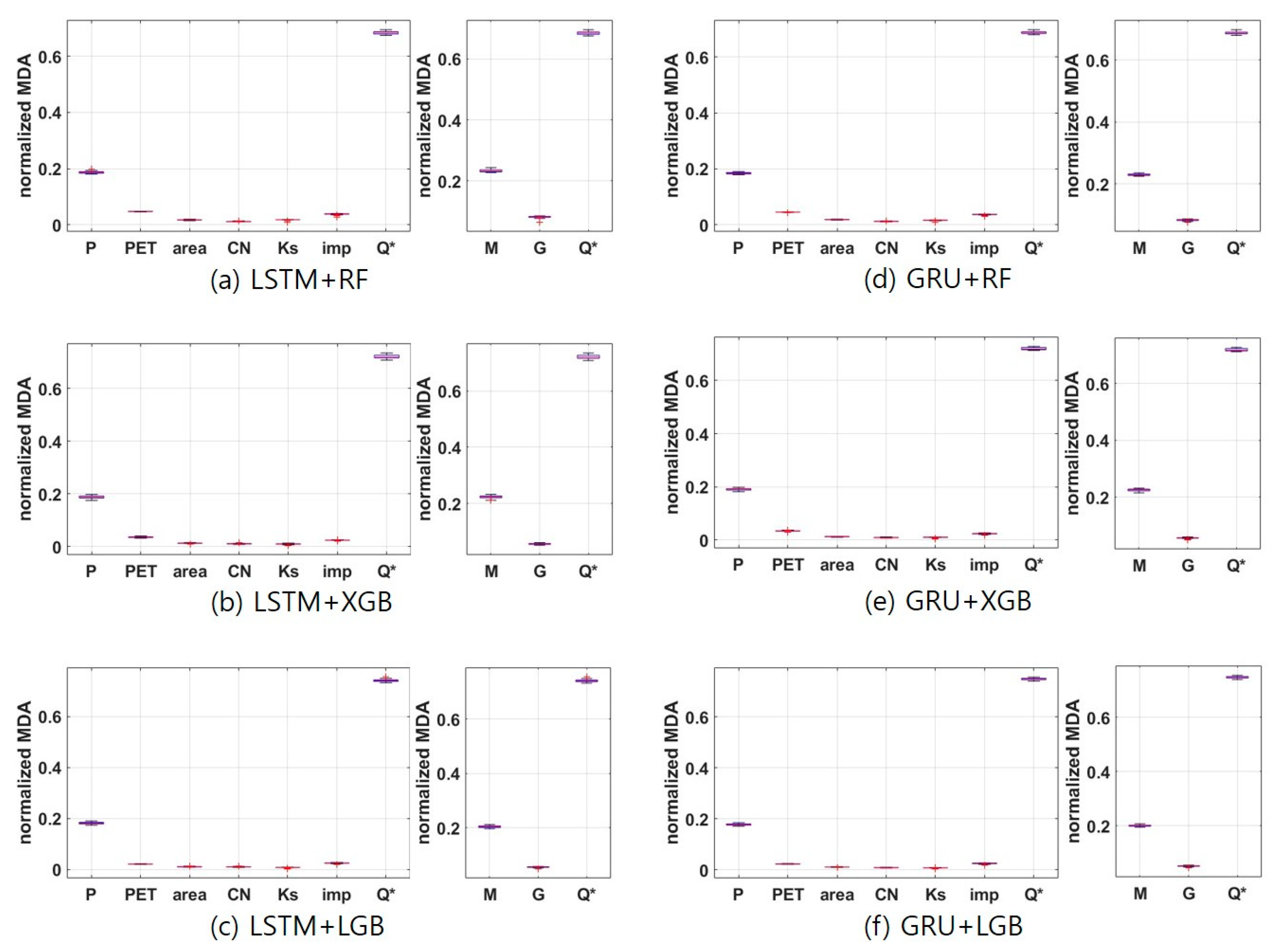
3.3. Comparison between Algorithms of Scheme MG
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schulla, J. LModel Description WaSiM (Water Balance Simulation Model), Completely Revised Version 2012. Last Change: 19 June 2012. 2012. Available online: http://www.wasim.ch/downloads/doku/wasim/wasim_2012_ed2_en.pdf (accessed on 1 March 2022).
- Hengl, T.; Mendes de Jesus, J.; Heuvelink, G.; Ruiperez Gonzalez, M.; Kilibarda, M.; Blagotic, A.; Shangguan, W.; Wright, M.; Geng, X.; Bauer-Marschallinger, B.; et al. SoilGrids250m: Global gridded soil information based on machine learning. PLoS ONE 2017, 12, e0169748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wood, E.; Roundy, J.; Troy, T.; van Beek, L.; Bierkens, M.; Blyth, E.; de Roo, A.; Döll, P.; Ek, M.; Famiglietti, J.; et al. Hyper resolution global land surface modeling: Meeting a grand challenge for monitoring Earth’s terrestrial water. Water Resour. Res. 2011, 47, W05301. [Google Scholar] [CrossRef]
- Worldbank. Assessment of the State of Hydrological Services in Developing Countries. 2018. Available online: https://www.gfdrr.org/sites/default/files/publication/state-of-hydrological-services_web.pdf (accessed on 1 March 2022).
- USGS. Streamgage History. 2018. Available online: https://water.usgs.gov/nsip/history.html (accessed on 1 March 2022).
- Fekete, B.; Robarts, R.; Kumagai, M.; Nachtnebel, H.; Odada, E.; Zhulidov, A. Time for in situ renaissance. Science 2015, 349, 685–686. [Google Scholar] [CrossRef] [PubMed]
- Hrachowitz, M.; Savenije, H.; Blöschl, G.; McDonnell, J.; Sivapalan, M.; Pomeroy, J.; Arheimer, B.; Blume, T.; Clark, M.; Ehret, U. A decade of predictions in ungauged basins (pub)—A review. Hydrol. Sci. J. 2013, 58, 1198–1255. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Y.; Zhang, L.; Wang, Z. Regionalization of hydrological modeling for predicting streamflow in ungauged catchments: A comprehensive review. WIREs Water 2021, 8, e1487. [Google Scholar] [CrossRef]
- Young, P.; Beven, K. Data-based mechanistic modelling and the rainfall-flow non-linearity. Environmetrics 1994, 5, 335–363. [Google Scholar] [CrossRef]
- Remesan, R.; Mathew, J. Hydrological Data Driven Modelling: A Case Study Approach; Springer International Publishing: New York, NY, USA, 2014; Volume 1. [Google Scholar]
- Halff, A.; Halff, H.; Azmoodeh, M. Predicting Runoff from Rainfall Using Neural Networks. In Engineering Hydrology; ASCE: Reston, VA, USA, 1993; pp. 760–765. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning Internal Representations by Error Propagation (No. ICS-8506); California University of San Diego, La Jolla Institute for Cognitive Science: San Diego, CA, USA, 1986. [Google Scholar]
- Carriere, P.; Mohaghegh, S.; Gaskar, R. Performance of a Virtual Runoff Hydrographic System. Water Resour. Plan. Manag. 1996, 122, 120–125. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 2017, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28, pp. 802–810. [Google Scholar]
- Tao, Y.; Gao, X.; Hsu, K.; Sorooshian, S.; Ihler, A. A Deep Neural Network Modeling Framework to Reduce Bias in Satellite Precipitation Products. J. Hydrometeoroly 2016, 17, 931–945. [Google Scholar] [CrossRef]
- Fang, K.; Shen, C.; Kifer, D.; Yang, X. Prolongation of SMAP to Spatiotemporally Seamless Coverage of Continental U.S. Using a Deep Learning Neural Network. Geophys. Res. Lett. 2017, 44, 11030–11039. [Google Scholar] [CrossRef] [Green Version]
- Assem, H.; Ghariba, S.; Makrai, G.; Johnston, P.; Gill, L.; Pilla, F. Urban Water Flow and Water Level Prediction Based on Deep Learning. In ECML PKDD 2017: Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2017; pp. 317–329. [Google Scholar]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F.; de Marinis, G. Stacked machine learning algorithms and bidirectional long short-term memory networks for multi-step ahead streamfow forecasting: A comparative study. J. Hydrol. 2022, 613, 128431. [Google Scholar] [CrossRef]
- Di Nunno, F.; de Marinis, G.; Granata, F. Short-term forecasts of streamflow in the UK based on a novel hybrid artificial intelligence algorithm. Sci. Rep. 2023, 13, 7036. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Arsenault, R.; Martel, J.; Brunet, F.; Brissette, F.; Mai, J. Continuous streamflow prediction in ungauged basins: Long short-term memory neural networks clearly outperform traditional hydrological models. Hydrol. Earth Syst. Sci. 2023, 27, 139–157. [Google Scholar] [CrossRef]
- Choi, J.; Won, J.; Jang, S.; Kim, S. Learning enhancement method of Long short-term memory network and its applicability in hydrological time series prediction. Water 2022, 14, 2910. [Google Scholar] [CrossRef]
- Ayzel, G.; Kurochkina, L.; Abramov, D.; Zhuravlev, S. Development of a Regional Gridded Runoff Dataset Using Long Short-Term Memory (LSTM) Networks. Hydrology 2021, 8, 6. [Google Scholar] [CrossRef]
- Kratzert, F.; Gauch, M.; Nearing, G.; Klotz, D. Neural Hydrology–A Python library for Deep Learning. J. Open Source Softw. 2022, 7, 4050. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.; Hochreiter, S.; Nearing, G. Toward improved predictions in ungauged basins: Exploiting the power of machine learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Khandelwal, A.; Jia, X.; Cutler, K.; Ghosh, R.; Renganathan, A.; Xu, S.; Tayal, K.; Nieber, J.; Duffy, C.; et al. Regionalization in a global hydrologic deep learning model: From physical descriptors to random vectors. Water Resour. Res. 2022, 58, e2021WR031794. [Google Scholar] [CrossRef]
- Choi, J.; Lee, J.; Kim, S. Utilization of the Long Short-Term Memory network for predicting streamflow in ungauged basins in Korea. Ecol. Eng. 2022, 182, 106699. [Google Scholar] [CrossRef]
- Allen, R.; Pereira, L.; Raes, D.; Smith, M. Crop Evapotranspiration-Guidelines for Computing Crop Water Requirements-FAO Irrigation and Drainage Paper 56; FAO: Rome, Italy, 1998; Volume 300, p. D05109. [Google Scholar]
- Won, J.; Kim, S. Future drought analysis using SPI and EDDI to consider climate change in South Korea. Water Supply 2020, 20, 3266–3280. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Srivastave, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Turkyilmazoglu, M. Accelerating the convergence of Adomian decomposition method (ADM). J. Comput. Sci. 2019, 31, 54–59. [Google Scholar] [CrossRef]
- Nash, J.; Sutcliffe, J. River flow forecasting through conceptual models. part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Ritter, A.; Munoz-Carpena, R. Performance evaluation of hydrological models: Statistical significance for reducing subjectivity in goodness-of-fit assessments. J. Hydrol. 2013, 480, 33–45. [Google Scholar] [CrossRef]
- Kim, R.; Won, J.; Choi, J.; Lee, O.; Kim, S. Application of Bayesian approach to parameter estimation of TANK model: Comparison of MCMC and GLUE methods. J. Korean Soc. Water Environ. 2020, 36, 300–313. [Google Scholar]
- Ruiz-Perez, G.; Gonzalez-Sanchis, M.; Del Campo, A.; Frances, F. Can a parsimonious model implemented with satellite data be used for modelling the vegetation dynamics and water cycle in water-controlled environments? Ecol. Model. 2016, 324, 45–53. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Won, J.; Lee, O.; Kim, S. Usefulness of global root zone soil moisture product for streamflow prediction of ungauged basins. Remote Sens. 2021, 13, 756. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Name | Area (km2) | CN | Ks (mm/d) | IMP | P (mm/yr) | PET (mm/yr) | PET/P |
|---|---|---|---|---|---|---|---|---|
| 1 | SJG | 763 | 67.10 | 133.8 | 0.0750 | 1354 | 1006 | 0.7428 |
| 2 | NGD | 2282 | 63.03 | 156.4 | 0.0582 | 1487 | 1077 | 0.7240 |
| 3 | ADD | 1591 | 59.08 | 177.5 | 0.0579 | 1104 | 1020 | 0.9244 |
| 4 | GSD | 677 | 67.19 | 132.5 | 0.0464 | 1315 | 1043 | 0.7934 |
| 5 | HCD | 929 | 56.73 | 191.8 | 0.0629 | 1259 | 1054 | 0.8369 |
| 6 | GDD | 121 | 68.95 | 127.7 | 0.0362 | 1250 | 934 | 0.7472 |
| 7 | UMD | 302 | 66.84 | 134.4 | 0.0516 | 1155 | 1136 | 0.9842 |
| 8 | YJ | 520 | 61.92 | 179.9 | 0.0807 | 1188 | 1048 | 0.8825 |
| 9 | DJ | 609 | 60.39 | 176.9 | 0.1312 | 1295 | 1023 | 0.7901 |
| 10 | OC | 491 | 63.12 | 168.1 | 0.0564 | 1362 | 1023 | 0.7513 |
| 11 | HS | 411 | 62.09 | 153.1 | 0.0646 | 1403 | 1032 | 0.7359 |
| 12 | NYJ | 202 | 60.41 | 178.3 | 0.0878 | 1219 | 1045 | 0.8572 |
| 13 | YS | 221 | 70.02 | 129.1 | 0.0919 | 1235 | 1088 | 0.8808 |
| 14 | BR | 162 | 55.90 | 187.1 | 0.0729 | 1065 | 952 | 0.8933 |
| 15 | HP | 115 | 71.65 | 115.8 | 0.0879 | 1034 | 895 | 0.8659 |
| 16 | YW | 1616 | 59.71 | 171.4 | 0.0417 | 1151 | 1024 | 0.8900 |
| 17 | MG | 612 | 61.85 | 162.7 | 0.0473 | 1328 | 1129 | 0.8504 |
| 18 | BY | 209 | 61.72 | 161.7 | 0.0571 | 1228 | 992 | 0.8074 |
| 19 | CJ | 168 | 65.50 | 158.9 | 0.1220 | 1186 | 1079 | 0.9103 |
| 20 | JH | 152 | 64.68 | 153.6 | 0.0707 | 1399 | 1026 | 0.7331 |
| 21 | YD | 930 | 61.29 | 174.6 | 0.0784 | 1449 | 1010 | 0.6969 |
| 22 | HS | 208 | 51.85 | 216.7 | 0.0458 | 1159 | 1025 | 0.8845 |
| 23 | BY | 156 | 67.60 | 122.4 | 0.0768 | 1247 | 1000 | 0.8020 |
| 24 | SYG | 2694 | 50.87 | 208.0 | 0.0586 | 1231 | 1038 | 0.8426 |
| 25 | CJD | 6661 | 62.37 | 156.5 | 0.0491 | 1205 | 1040 | 0.8638 |
| Segment | Hydrological Condition Class | Flow Exceedance Probability Range |
|---|---|---|
| Segment H | High flow condition | [0, 0.33] |
| Segment N | Normal flow condition | [0.33, 0.67] |
| Segment L | Low flow condition | [0.67, 1] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Won, J.; Seo, J.; Lee, J.; Choi, J.; Park, Y.; Lee, O.; Kim, S. Streamflow Predictions in Ungauged Basins Using Recurrent Neural Network and Decision Tree-Based Algorithm: Application to the Southern Region of the Korean Peninsula. Water 2023, 15, 2485. https://doi.org/10.3390/w15132485
Won J, Seo J, Lee J, Choi J, Park Y, Lee O, Kim S. Streamflow Predictions in Ungauged Basins Using Recurrent Neural Network and Decision Tree-Based Algorithm: Application to the Southern Region of the Korean Peninsula. Water. 2023; 15(13):2485. https://doi.org/10.3390/w15132485
Chicago/Turabian StyleWon, Jeongeun, Jiyu Seo, Jeonghoon Lee, Jeonghyeon Choi, Yoonkyung Park, Okjeong Lee, and Sangdan Kim. 2023. "Streamflow Predictions in Ungauged Basins Using Recurrent Neural Network and Decision Tree-Based Algorithm: Application to the Southern Region of the Korean Peninsula" Water 15, no. 13: 2485. https://doi.org/10.3390/w15132485