
Abstract
This study used rapid serial visual presentation (RSVP) to determine whether, in an item-method directed forgetting task, study word processing ends earlier for forget words than for remember words. The critical manipulation required participants to monitor an RSVP stream of black nonsense strings in which a single blue word was embedded. The next item to follow the word was a string of red fs that instructed the participant to forget the word or green rs that instructed the participant to remember the word. After the memory instruction, a probe string of black xs or os appeared at postinstruction positions 1–8. Accuracy in reporting the identity of the probe string revealed an attenuated attentional blink following instructions to forget. A yes–no recognition task that followed the study trials confirmed a directed forgetting effect, with better recognition of remember words than forget words. Considered in the context of control conditions that required participants to commit either all or none of the study words to memory, the pattern of probe identification accuracy following the directed forgetting task argues that an intention to forget releases limited-capacity attentional resources sooner than an instruction to remember—despite participants needing to maintain an ongoing rehearsal set in both cases.
Similar content being viewed by others
Rapid serial visual presentation (RSVP) presents a stream of items one after another in the same spatial location at a rate of six to 20 items/sec. When participants must identify two successive targets in this stream, identification of the first target (T1) tends to be highly accurate; identification of the second target (T2), however, is generally impaired the more closely it follows the first (Broadbent & Broadbent, 1987; for reviews see Dux & Marois, 2009; Martens & Wyble, 2010; Snir & Yeshurun, 2017). The only exception is when T1 and T2 are presented in immediate succession such that T2 lags T1 by only one position in the RSVP stream (e.g., Chun & Potter, 1995; Raymond, Shapiro, & Arnell, 1992). In this case, T1 and T2 are integrated into the same temporal episode and T2 is identified with relatively high accuracy (Hommel & Akyürek, 2005)—a phenomenon known as “lag-1 sparing” (Potter, Chun, Banks, & Muckenhoupt, 1998; see Visser, Bischof, & Di Lollo, 1999). The impaired T2 identification that otherwise occurs within a temporal window extending up to approximately 500 ms is referred to as an attentional blink and occurs only when T1 must be identified; if T1 can be ignored, T2 identification is relatively unaffected by T1-T2 lag (e.g., Raymond et al., 1992).
Although there are differing theoretical accounts of the attentional blink, most attribute impaired T2 identification accuracy to a relative unavailability of attentional resources (for reviews, see Dux & Marois, 2009; Snir & Yushurun, 2017). The notion is that T1 identification draws on limited-capacity attentional resources that are also needed for T2 identification. T2 identification accuracy suffers so long as these resources remain engaged on the T1 task and improves once they become available again. In this way, the attentional blink indexes the temporal engagement of attention on T1 processing. The goal of the current study was to take advantage of this property of the attentional blink to elucidate the temporal dynamics of attentional engagement during intentional forgetting.
Intentional forgetting
Intentional forgetting is the purposeful forgetting of information that is deemed outdated or irrelevant (e.g., Bjork, 1970, 1972, 1989; Bjork, Bjork, & Anderson, 1998; see Anderson & Hanslmayr, 2014, for a review). The current study is concerned exclusively with intentional forgetting that occurs at encoding, which is studied using an item-method directed forgetting paradigm (see MacLeod, 1998, for a review). Participants are presented with study items one at a time, each followed by an instruction to remember or forget. After all items have been presented, memory is tested for all studied items, regardless of the memory instruction. A directed forgetting effect occurs when memory is better for remember items than for forget items. This effect cannot be explained by demand characteristics (MacLeod, 1999) and is instead interpreted as evidence of top-down control exerted at encoding to regulate the contents of long-term memory.
The directed forgetting effect in an item-method task is attributed to selective rehearsal of remember over forget items (e.g., Basden & Basden, 1998; Basden, Basden, & Gargano, 1993; MacLeod, 1998; Taylor, Cutmore, & Pries, 2018; although see Rummel, Marevic, & Kuhlmann, 2016). The notion is that participants attend to each word as it is presented and use maintenance rehearsal to refresh its representation within working memory while they await the memory instruction (Gardiner, Gawlik, & Richardson-Klavehn, 1994; Hsieh, Hung, Tzeng, Lee, & Cheng, 2009; Paz-Caballero, Menor, & Jiménez, 2004). If the instruction is to remember, participants then engage in elaborative rehearsal to commit the item to long-term memory. If the instruction is to forget, this initiates active cognitive control (e.g., Fawcett & Taylor, 2008; Cheng, Liu, Lee, Hung, & Tzeng, 2012) to limit further rehearsal of the forget item (cf. Hourihan & Taylor, 2006). This control is accomplished by engaging frontal mechanisms (Bastin et al., 2012; Hauswald, Schulz, Iordanov, & Kissler, 2010; van Hooff & Ford, 2011; Wylie, Fox, & Taylor, 2008; Yang et al., 2012) that are implicated in—even if not identical to (Fawcett & Taylor, 2010)—those involved in executive control over attention and motor responding (e.g., Aron, Fletcher, Bullmore, Sahakian, & Robbins, 2003; Aron & Poldrack, 2006; Aron, Robbins, & Poldrack, 2004). Either coincident with this control, or more likely as a consequence of this control, attention is thought to withdraw from the forget item representation (Fawcett & Taylor, 2010, 2012; Taylor, 2005; Taylor & Fawcett, 2011; Thompson, Hamm, & Taylor, 2014; see also Rizio & Dennis, 2013), limiting its rehearsal.
Whereas differential withdrawal of overt attention has been revealed using eye-movement monitoring (Lee, 2018), differential withdrawal of covert attention from forget and remember items has only been inferred from effects on inhibition of return (IOR). IOR is defined as slower responding to targets that appear in the same location as a previous peripheral onset rather than in a different location (e.g., Posner & Cohen, 1984; see Berlucchi, 2006; Klein, 2000; and, Taylor & Klein, 1998, for reviews). Taylor (2005) measured IOR in the context of an item-method directed forgetting task in which study words were presented in the left or right visual periphery. Each study word was followed by an instruction to remember or forget, and then by a visual target that appeared in the same or in a different location relative to the study word. Reaction times to respond to the visual target revealed a larger IOR effect following instructions to forget than following instructions to remember. On the grounds that IOR can coexist with attentional facilitation at the peripheral location (Berlucchi, Chelazzi, & Tassinari, 2000; Chica, Lupiáñez, & Bartolomeo, 2006; Lupiáñez et al., 2004) and is not fully revealed until the opposing effects of attention (facilitation) are removed (Danziger & Kingstone, 1999), Taylor (2005) interpreted this pattern of results as evidence for a greater withdrawal of attention from the spatial representation of peripherally presented forget words than remember words. Control experiments ruled out the alternative possibility that the pattern of larger IOR effects on forget trials compared to remember trials was due primarily to attentional dwell on remember trials rather than attentional withdrawal on forget trials (see also Taylor & Fawcett, 2011).
A larger IOR effect following forget instructions than following remember instructions has proven to be robust (e.g., Fawcett & Taylor, 2010; Taylor & Fawcett, 2011; Thompson et al., 2014; Thompson & Taylor, 2015) but does not constitute direct evidence that attention is withdrawn from forget item processing: IOR is conceived as an aftereffect of attentional withdrawal rather than as a measure of that withdrawal. Moreover, the inherently spatial nature of IOR raises the specter that a differential withdrawal of attention from forget and remember items is specific to situations in which study words are presented in peripheral spatial locations and does not represent a more general mechanism of intentional forgetting at encoding. Finally, IOR is necessarily revealed on a relatively long time course—this is because attention must first be removed and/or time allowed for its facilitatory effects to dissipate before IOR can be measured. As a result, IOR cannot reveal the duration of study item processing or provide information about how soon limited-capacity resources come back online after unwanted processing is halted.
Using the attentional blink to measure the temporal availability of attention
To address these issues, the current study combined an item-method directed forgetting task with an RSVP procedure designed to elicit an attentional blink. The goal was to reveal the temporal availability of processing resources following instructions to remember and forget. Participants monitored a stream of black nonsense strings presented at a rate of 10 items/sec. Embedded in this stream was a blue study word—the only word and the only blue item in the stream. Taking advantage of lag-1 sparing, this word was followed immediately by a string of green rs or red fs. In the critical manipulation (Experiment 2), these served as instructions to remember and forget, respectively.
There were always another eight items after the memory instruction. These occupied postword positions 2–9 but—in keeping with an emphasis on the effects of memory instruction on the attentional blink—will hereafter be described as postinstruction positions 1–8. On every trial, one of these eight postinstruction items was a string of black xs or os. Whereas the remember or forget word served the usual function of T1 in an attentional blink task, this string of xs or os served the usual function of T2. Unlike a typical attentional blink task however, no explicit report of T1 identity was required. Thus, to avoid confusion, the string of xs or os will not be described as a second target (i.e., T2) but as a probe that was used to measure the attentional blink generated by study word processing.
Participants were required to report the identity of this probe string at the end of each RSVP stream that comprised a study trial. The accuracy of probe identification was used to assess the attentional blink as a function of whether the preceding instruction was to remember or forget the study word. After all study trials were presented, participants completed a yes–no recognition task to confirm a directed forgetting effect (i.e., better recognition of remember words than forget words). Whereas a concentration of attention on the study word in the RSVP stream should make limited-capacity resources relatively unavailable for subsequent probe string processing, the removal of these resources from study word processing should free them for allocation to the probe task.
Preliminary investigation
In the current study, it was not possible to have participants report both the study word and the probe string on every RSVP trial. In the context of the directed forgetting task, participants needed to attend to and attempt to identify every word because they could not know in advance whether they would be required to remember or forget that word. Yet the fact of instructing participants to forget a random half of study words advised against asking them to explicitly report the identity of each word prior to indicating the probe identity; doing so would risk further rehearsal of forget words and potentially interfere with the efficacy of the forget instruction. While this was a necessary feature of the current design, the fact that study word identity could not be reported on a trial-by-trial basis posed two potential challenges—one of which needed to be addressed empirically in a preliminary investigation (Experiment 1).
The first challenge of the current design is that probe identification accuracy could not be conditionalized on correct study word identification. Consider that in a typical attentional blink task, T2 accuracy is often conditionalized on correct T1 identification (e.g., Broadbent & Broadbent, 1987; Raymond et al., 1992). Arguably, applying this so-called within-trial contingency principle (e.g., see Dell’Acqua, Jolicœur, Luria, & Pluchino, 2009) to the analysis of T2 accuracy is not strictly necessary: The inherent difficulty of a two-target RSVP task means that attention is probably engaged on T1 processing even when its deployment does not lead to an accurate identification. Indeed, there is empirical evidence that T2 accuracy is unaffected by whether the analysis includes all trials or is contingent on a correct report of T1 identity (e.g., Dell’Acqua, Jolicœur, Pascali, & Pluchino, 2007). Admittedly, however, this could be because T1 identification tends to be high, such that relatively few trials are excluded from the contingent analysis. Nevertheless, it is notable that similar T2 accuracies are reported under contingent and noncontingent analyses, whether T1 accuracies are closer to 90% or 70% (e.g., see Dell’Acqua et al., 2007, Experiment 5). This seems to argue against uniformly high T1 accuracy being critical for measurement of T2 performance in a noncontingent analysis. It further points to the robustness of the T2 measurement, whether this is calculated on a contingent or noncontingent basis. On these grounds, the need to perform a noncontingent analysis of probe identification accuracy in the current study did not seem particularly worrying.
The second challenge also derives from the fact of having participants report probe string identity without first making an explicit report of study word identity. Consider that in a typical attentional blink task, an explicit report is usually required for both targets—T1 and T2. Indeed, unlike when both targets must be reported, when T1 can be ignored and only a report of T2 is required, T2 accuracy is relatively unaffected by temporal distance from T1 (e.g., Raymond et al., 1992). While this is usually explained with reference to the demands made by T1 processing in the dual-task condition but not in the single-task condition, this comparison confounds dual-task versus single-task processing with two-target and single-target output. To wit: If the attentional blink for T2 depends only on T1 processing, then it should be possible in the current study to observe an effect on the attentional blink due to processing differences elicited by instructions to remember or forget the study word. However, if the attentional blink depends crucially on T1 output, the fact of having participants report only probe identity and not study word identity makes the manipulation of memory instruction moot.
Because the current study could not reasonably ask participants to output each study word identity before outputting the probe identity, it seemed critical to ensure that an attentional blink could nevertheless be obtained using the intended method. To this end, Experiment 1 employed the general method already described, except that the colored memory instruction embedded in the RSVP stream was not ascribed meaning. Instead, one group of participants was instructed to commit all study words to memory (remember all) and another was instructed to commit none of the study words to memory (remember none). In both groups, the only report required at the end of each RSVP stream was the identity of the probe string. Despite this single-target output, the instructions were meant to mirror dual-task (remember all) and single-task (remember none) processing requirements. The goal was to establish that an explicit report of study word identity is not necessary to produce an attentional blink (or, by extension, to observe differences in the attentional blink when a trial-by-trial manipulation of memory instruction is introduced in Experiment 2).
Experiment 1
The goal of Experiment 1 was to ascertain whether an attentional blink could be obtained even when an explicit identification of the study word is not required prior to probe identification. Probe identification accuracy was measured in remember-all and remember-none groups. In both groups, probe identification was the only explicit report required following each RSVP stream. To the extent that an attentional blink occurs in the remember-all group (dual task) and not in the remember-none group (single task), processing of the study word—even in the absence of an explicit report of its identity—can be assumed. A yes–no recognition test followed the study trials for participants in both groups.
Method
Participants
A total of 64 Dalhousie University students participated in exchange for psychology course credit: 32 participated in the remember-all group; 32 participated in the remember-none group. Participants were tested individually in a session that lasted approximately 60 minutes. All participants reported normal or corrected-to-normal vision and a good understanding of the English language.
Stimuli and apparatus
SuperLab 5.05 (Cedrus, San Pedro California) was used to present stimuli on 27-in iMac computers and to collect responses from the standard universal serial bus keyboard. Stimuli were presented on a white background in 32-point Geneva font. RSVP letter strings were presented in black; study words were presented in blue. Although they were not needed for Experiment 1, both remember and forget strings were presented in the RSVP trials. Remember instructions consisted of a string of three to seven lowercase rs presented in green; forget instructions consisted of a string of three to seven lowercase fs presented in red.
A list of 320 nouns was created using the online version of the MRC Psycholinguistic Database (http://websites.psychology.uwa.edu.au/school/MRCDatabase/uwa_mrc.htm; Coltheart, 1981; Wilson, 1988). The words on this list had a mean Kučera–Francis (Kučera & Francis, 1967) word frequency of 52.26 (R = 1–787); concreteness rating of 578 (R = 500–670); familiarity rating of 552.35 (R = 501–646); and were 1.31 (R = 1–3) syllables long. There were 39 three-letter words, 113 four-letter words, 88 five-letter words, 54 six-letter words, and 26 seven-letter words, for an average word length of 4.73 letters. This word list was randomized and divided into two sublists of 160 words each, all in lowercase letters. One of these 160-item lists served as study words; the other served as unstudied foil words that were presented at recognition only. The designation of lists as study words and foil words was counterbalanced across participants. Each list of 160 study words was further divided into two sublists of 80 items each. The words on one of these 80-item lists were assigned a remember instruction at study; words on the other 80-item list were assigned a forget instruction; this assignment was also counterbalanced across participants. Each 80-item half-list had the same average word length. Although this consideration was not important for Experiment 1, it ensured that any differences in the attentional blink on remember and forget trials in Experiment 2 could not be attributed to word length effects (e.g., Olson, Chun, & Anderson, 2001).
An online tool was used to generate random nonsense letter strings that were used as the RSVP stream (http://www.dave-reed.com/Nifty/randSeq.html). Parameters were set to draw from all lowercase letters of the alphabet other than vowels (including y) and x (which was used as a probe item): bcdfghjklmnpqrstvwz. A total of 2,200 nonsense strings were created. To match as closely as possible the word list letter-length distributions, these strings were created such that there were 268 three-letter strings, 777 four-letter strings, 605 five-letter strings, 371 six-letter strings, and 179 seven-letter strings; the average nonsense string length was 4.73.
The order of the 2,200 letter strings was randomized before assigning strings to preword and postinstruction streams. Preword streams could contain a total of eight to 15 nonsense strings. Accordingly, the first 920 of the 2,200 randomized nonsense strings were used to create 80 preword streams. This was done by assigning strings to 10 streams at each of eight different lengths, between eight and 15 items. There were always eight postinstruction probe positions. Thus, for the remaining 1,280 of the 2,200 randomized nonsense strings, consecutive sequences of eight items were selected to create a total of 160 postinstruction streams.
The 160 postinstruction streams were divided into two sets of 80 streams each. Within each of these 80-stream sets, five of the nonsense letter strings in each of positions 1-8 were replaced with an equal number of xs; another five letter strings in each of positions 1-8 were replaced with an equal number of os. Creating probe strings by replacing nonsense letter strings with an equal number of probe letters ensured that the overall distribution of string lengths within the RSVP stream remained unchanged. Across each of the counterbalancing conditions already described, half of the participants were presented with one 80-item postinstruction stream set; half of the participants were presented with the other 80-item postinstruction stream set. The counterbalanced presentation of two different postinstruction stream sets was not a necessary control but was done to ensure generalizability of the results, given the novelty of the paradigm.
Even though the remember and forget designation had no meaning in Experiment 1, in keeping with the intended methods for Experiment 2, for half of the participants presented with each stream set, the first 40 study items on the remember and forget lists were matched to a postinstruction stream that contained an x probe string (i.e., with five instances at each of postinstruction positions 1–8) and the second 40 study items on these lists were matched to a stream that contained an o probe string. The assignment of probe identities to each remember and forget word half-list was reversed for the other participants. The memory instruction that displayed was drawn equally often from the five possible instruction string lengths of three to seven fs or rs.
To summarize, there were a total of 16 counterbalanced conditions based on: Assignment of words to study/foil lists × assignment of study words to remember/forget instructions × assignment of probe identity to each half-list of remember and forget words (x to the first half and o to the second half or vice versa) × presentation of postinstruction stream set 1 or stream set 2. Data were collected from two participants for each of these counterbalanced stimulus presentations.
Procedure
Following informed consent, participants received verbal instructions that were then reiterated on the computer monitor. These instructions informed participants that they would be required to monitor an RSVP stream of black nonsense strings for a blue item. They were told that items in the stream would be presented very quickly, one at a time in the center of the computer monitor. In fact, the RSVP streams were presented at a rate of 10 items/sec. Study words were colored blue rather than black to help participants discern them from the RSVP stream. Participants in the remember-all group were told that they should endeavor to read and commit all blue words to memory. Participants in the remember-none group were told only that the blue color signaled the point in the stream after which the probe string would occur.
All participants were told that an additional red or green colored item would appear immediately after the blue item but were properly informed that it had no relevance to their task. This colored item was, in fact, the memory instruction that would be used for Experiment 2 but that had no meaning for Experiment 1. This instruction always followed the word immediately (i.e., in postword lag position 1) and consisted of a string of green rs (remember) or red fs (forget). The instructions then explained that at some time after this red/green color, a probe would be presented on every trial and would consist of a variable-length string of xs or os. This string occupied postinstruction positions 1–8 with equal probability. Participants were asked to identify the probe string on every trial and instructed to guess if unable to do so.
Probe practice
Before proceeding to the study trials, the experimenter left the room and participants were given 40 practice trials. These trials were identical to the study trials except that every trial presented the same preword stream, the word word appeared instead of a unique study word on every trial, and no items needed to be committed to memory for either group of participants. These trials were intended to give participants practice finding and identifying the probe strings.
Study trials
Following the practice trials, additional instructions informed participants that they were starting the experiment trials. Participants in the remember-all group were told that a unique study word would be presented on every trial and that they should try to commit these words to memory for a later test.
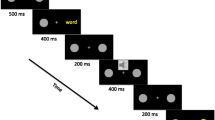
There were a total of 160 RSVP trials in this phase of the experiment. As depicted in Fig. 1, each trial started with the presentation of a preword stream of eight to 15 nonsense strings; each preword stream length was presented equally often. A word was then presented from either the remember or forget list of study items. This study word was followed immediately—in the lag-1 position—by its corresponding memory instruction. Again, this instruction had no meaning in the context of Experiment 1. There were always eight postinstruction items, one of which was a probe string. This probe string appeared equally often in one of the eight postinstruction positions. On a random half of the trials, this probe consisted of three to seven xs, and on the other half of the trials it consisted of three to seven os. Each item in the trial was displayed for 100 ms.

Method. Using rapid serial presentation (RSVP), items were presented at a rate of 10 items/sec. The RSVP stream consisted of black nonsense strings. Every trial started with 8–15 nonsense strings as stream items, followed by a single word colored in blue. This word was always followed immediately by a string of green rs or red fs; in Experiment 1, these had no meaning, but in Experiment 2, these served as remember and forget instructions, respectively. There were always eight items after the instruction. Seven of these postinstruction items were black nonsense strings; one item was a probe string that participants were required to identify as consisting of a string of os or xs. The probe occurred equally often in postinstruction positions 1–8. All stream items including words, memory instructions, and probes were three to seven letters in length. See text for additional details
At the end of each study trial, participants were prompted to input the probe identity by pressing the x or o key on the computer keyboard and were given 4,000 ms in which to register a response. The keyboard input triggered feedback on response accuracy that remained visible for 1,500 ms. If participants correctly identified the probe, an orange check mark appeared in the center of the computer monitor; if they responded incorrectly, an orange exclamation mark appeared; if they failed to respond with an x or o, an orange question mark appeared.
Test trials
Immediately following the last study trial, participants received instructions for the yes–no recognition test. These instructions indicated that participants would be presented with words one at a time. For each word, they were to decide whether it had been presented during the study trials. If participants recognized the word from the study trials, they were instructed to press y on the computer keyboard (for yes); if they did not recognize the word from the study trials, they were instructed to press n (for no). Participants were invited to recall the experimenter back into the room if they did not understand these instructions or had questions. Otherwise, they pressed the space bar to proceed to the test trials. An abbreviated set of instructions remained visible at the top left of the computer monitor throughout the test trials.
There were a total of 320 test trials. On each trial, a fixation stimulus consisting of black crosshairs (+) appeared at the center of the computer monitor for 500 ms before being replaced by a word printed in blue. This word could be one of the 80 remember words from the study trials, one of the 80 forget words, or one of the 160 unstudied foil words. The word remained visible until the participant made a response using the computer keyboard. No accuracy feedback was given.
Data analysis
Trial data were collated using R Studio 1.1.383 running R 3.4.3 (R Core Team, 2017). Various R packages were utilized, including plyr (Wickham, 2011), dplyr (Wickham & Francois, 2016), tidyr (Wickham, 2017b), and stringr (Wickham, 2017a). R package ez 4.4-0 (Lawrence, 2016) was used to calculate descriptive statistics (ezStats) and within-subjects analyses of variance (ezANOVA), including generalized eta squared (ges) as a measure of effect size; this package was also used to create plots (ezPlot) that were subsequently modified using ggplot2 (Wickham, 2009).
Results
Data were first analyzed for the yes–no recognition test and then for the probe identification task. In both groups, the percentage of yes responses on the recognition test represents recognition hits for words presented on the study trials and false alarms to foil words. A preliminary examination of the foil data revealed two participants in each of the two groups whose mean false alarm rate exceeded the mean of all participants by more than two standard deviations. The data contributed by these four participants were removed from all subsequent analyses. The mean foil false alarm rate was 13% across the 30 remaining participants in the remember-all group and a numerically identical 13% across the 30 remaining participants in the remember-none group.
The mean recognition hit rates are shown in Table 1 as a function of group (remember all, remember none) and postinstruction probe position (1–8). These data were analyzed in an analysis of variance (ANOVA), with group as a between-subjects factor and probe position as a within-subjects factor. A significant main effect for group confirmed that recognition hits were overall higher in the remember-all group (M = 50%) than in the remember-none group (M = 23%), F(1, 58) = 50.23, MSe = 2006.87, p < .01, ges = .39. There was no significant main effect of probe position, F < 1, and no significant interaction of group and probe position, F < 1. In short, subsequent recognition of study words was better for participants who were required to remember all study words rather than for those who were required to remember none, with no discernable effect of probe placement on the accuracy of later recognition in either group.
Probe identification accuracy was calculated as the percentage of correct identifications out of 10 presentations at each postinstruction probe position. The mean probe identification accuracy on study trials is shown in Fig. 2, as a function of group (remember all, remember none) and postinstruction probe position (1–8). An analysis of these data revealed a main effect of group, with greater probe identification accuracy in the remember-none group than in the remember-all group, F(1, 58) = 7.13, MSe = 554.10, p < .01, ges = .07. There was also a main effect of probe position, F(7, 406) = 29.37, MSe = 59.54, p < .01, ges = .18, indicative of an overall attentional blink (i.e., worse identification accuracy the sooner the probe occurred in the postinstruction stream). Indeed, the attentional blink was significant in the remember-all group, F(7, 203) = 22.93, MSe = 75.19, p < .01, ges = .36, as well as in the remember-none group, F(7, 203) = 7.89, MSe = 43.89, p < .01, ges = .06. Critically, however, a significant two-way interaction between group and postinstruction probe position indicated that the temporal characteristics of the attentional blink differed in the remember-all and remember-none groups, F(7, 406) = 5.41, MSe = 59.54, p < .01, ges = .04.

Experiment 1. Probe identification accuracy (%) as a function of group (remember all, remember none) and postinstruction probe position (1–8). Error bars depict Fisher’s Least Significant Difference for the plotted effect. Note that the y-axis scale starts at 50%
To better understand this interaction, performance in the remember-all and remember-none groups was compared at each of the postinstruction probe positions. Probe identification accuracy was significantly worse in the remember-all group compared to the remember-none group at the first five postinstruction positions: position 1 F(1, 58) = 10.89, MSe = 209.61, p < .01, ges = .16; position 2, F(1, 58) = 6.78, MSe = 208.90, p < .02, ges = .10; position 3, F(1, 58) = 7.25, MSe = 210.59, p < .01, ges = .11; position 4, F(1, 58) = 5.44, MSe = 88.21, p < .03, ges = .09; position 5, F(1, 58) = 8.30, MSe = 47.86, p < .01, ges = .13. Probe identification accuracy did not differ significantly between the two groups at positions 6–8: position 6, F < 1; position 7, F < 1; position 8, F(1, 58) = 1.82, MSe = 50.54, p > .18.
Discussion
The purpose of Experiment 1 was to determine whether an attentional blink could be obtained when study word identification was required to satisfy task demands, but not explicitly confirmed by a trial-by-trial report. On this, the data were clear. The requirement that participants commit all words to memory resulted in a higher subsequent recognition hit rate than did the expectation that they commit no words to memory; this accords with greater scrutiny of study words in the remember-all condition than in the remember-none condition. Coincident with this effect of group instruction on recognition performance was an effect on the attentional blink: The attentional blink was more pronounced in the remember-all group than in the remember-none group. Of course, one might wonder why there was an attentional blink at all in the latter.
It seems likely that the modest—yet significant—attentional blink in the remember-none group was due to automatic capture of attention by the blue study word. For example, when a colored word distractor precedes a single black target in an otherwise black stream of false fonts, the word generates an attentional blink for the subsequent target (Maki & Mebane, 2006; Stein et al., 2010). This is not due to attentional capture by the color singleton per se: An attentional blink does not occur if the colored distractor is a false font embedded in an otherwise black stream of false fonts (Stein et al., 2010). Instead, attentional capture by the colored word is likely due to automatic and obligatory word processing, such as leads to Stroop interference (Stroop, 1935; see MacLeod, 1991, for a review). In the remember-none group, this was likely the only factor contributing to the occurrence of the small but reliable attentional blink; in the remember-all group, this was likely only one factor contributing to the attentional blink.
The attentional blink was more pronounced when all of the study words had to be committed to memory, rather than none. This result is consistent with the premise that study words received more processing in the remember-all group than in the remember-none group (see also Olivers & Nieuwenhuis, 2005, 2006; Thompson, Ralph, Besner, & Smilek, 2015, for evidence that increased attentional engagement leads to a more pronounced attentional blink). It is irrelevant for present purposes whether this increased processing per se was the critical determinant of the larger attentional blink in the remember-all group compared to the remember-none group, or whether it was the concurrent memory load that resulted from this processing (cf. Akyürek, Hommel, & Jolicœur, 2007; Johnston, Linden, & Shapiro, 2012). The pertinent finding is that the attentional blink is sensitive to the memory demands associated with the study word, even when no explicit report is made of study word identity on each trial.
Experiment 2
In both the remember-all and remember-none groups of Experiment 1, the only response required on an RSVP trial was probe identity. Even so, the accuracy in identifying this probe as a function of its postinstruction position in the RSVP stream depended critically on whether the instructions encouraged participants to scrutinize the preceding study word (remember-all group) or not (remember-none group). With this in mind, Experiment 2 manipulated study instruction within subjects. Participants were instructed to remember all study words that were followed by a string of green rs and to forget all study words that were followed by a string of red fs.
The need to commit a subset of words to memory meant that all participants would complete the study trials under a growing memory load. It seemed likely that participants would engage in cumulative rehearsal throughout the study trials—retrieving and rehearsing remember words from previous trials even as they performed the task of remembering or forgetting the study word on a given trial. However, given the difficulty and rapidity of the RSVP task, it seemed unlikely that cumulative rehearsal of preceding remember words would occur during the RSVP procedure; instead, it seemed more likely that this would occur after participants made their report of the probe identity. Under this assumption, the only task demand expected to differentiate RSVP trials was whether participants were instructed to remember or forget the study word. The need to attend to each study word was expected to generate an attentional blink in both conditions; however, this attentional blink was predicted to resolve sooner following a forget instruction than following a remember instruction due to an earlier removal of limited-capacity resources from forget word processing.
Method
Participants
A total of 36 Dalhousie University students participated in exchange for psychology course credit. Participants were tested individually in a session that lasted approximately 60 minutes. All participants reported normal or corrected-to-normal vision and a good understanding of the English language.
Stimuli and apparatus
The stimuli and apparatus were as described for Experiment 1.
Procedure
The procedure was identical to that described for Experiment 1, except that the red and green memory instructions embedded in the immediate postword position now had meaning with respect to the study word. Emphasis was placed on the fact that the red/green color was a reliable indicator of the memory instruction and could be used even if the letters comprising the instruction string could not be discerned: Green color indicated that the word should be committed to memory for a later memory test and red indicated that the word could be forgotten. No mention was made of the fact that the memory test would also query recognition of forget words. On the yes–no recognition test, the instructions were explicit in requiring a y (yes) response to all words that were recognized from the study trials, regardless of the associated memory instruction.
Results
As was done for Experiment 1, a preliminary analysis first examined the percentage of recognition yes responses. These data represent recognition hits for remember and forget words and false alarms for foil words. Three participants had mean false alarm rates to unstudied foil words that exceeded the mean of all participants by more than two standard deviations. The data contributed by these three participants were removed from all subsequent analyses. The mean foil false alarm rate was 14% across the 29 remaining participants.
The mean hit rates are shown in Table 2, as a function of memory instruction (remember, forget) and postinstruction probe position (1–8). An analysis of these hit rates revealed a significant effect of memory instruction, with overall greater recognition of remember words (M = 47%) than forget words (M = 23%), F(1, 28) = 93.36, MSe = 711.50, p < .01, ges = .29. How soon the probe followed the study word had no significant effect on subsequent recognition hit rates, F(7, 196) = 1.68, MSe = 177.76, p > .11, ges = .01. There was likewise no significant interaction of memory instruction and probe position, F < 1. These data confirm a directed forgetting effect with better subsequent recognition of words that participants were instructed to remember compared to those they were instructed to forget, with no discernable effect of probe placement on the accuracy of later recognition in either instruction condition.
Probe identification accuracy was calculated in the same manner as described for Experiment 1. The mean probe identification accuracies are shown in Fig. 3. These data were analyzed as a function of memory instruction (remember, forget) and postinstruction probe position (1–8). This analysis revealed greater probe identification accuracy following forget instructions (M = 85%) than following remember instructions (M = 81%), F(1, 28) = 7.13, MSe = 254.15, p < .02, ges = .02. Demonstrating an overall attentional blink, there was also a significant effect of probe position, F(7, 196) = 25.45, MSe = 153.87, p < .01, ges = .25, with poorer identification the sooner the probe followed the memory instruction. Indeed, the attentional blink was significant following both remember instructions, F(7, 196) = 15.38, MSe = 137.30, p < .01, ges = .27, and forget instructions, F(7, 196) = 14.72, MSe = 143.95, p < .01, ges = .26. Critically, however, a significant two-way interaction between memory instruction and postinstruction probe position demonstrated that the temporal characteristics of this attentional blink differed on remember and forget trials, F(7, 196) = 2.47, MSe = 127.38, p < .02, ges = .03.

Experiment 2. Probe identification accuracy (%) as a function of memory instruction (remember, forget) and postinstruction probe position (1–8). Error bars depict Fisher’s Least Significant Difference for the plotted effect. Note that the y-axis scale starts at 50%
To better understand this interaction, performance on remember and forget trials was compared at each of the postinstruction probe positions. No significant differences were observed at positions 1–3 or positions 6–8: position 1, F < 1; position 2, F < 1; position 3, F(1, 28) = 2.84, MSe = 155.67, p > .10, ges = .03; position 6, F(1, 28) = 1.933, MSe = 123.69, p > .17, ges = .03; position 7, F(1, 28) = 1.69, MSe = 82.51, p > .20, ges = .03; position 8, F(1, 2 8) = 1.67, MSe = 37.07, p > .20, ges = .02. There were, however, significant differences at midrange positions 4 and 5. At postinstruction position 4, probe identification accuracy was 11% higher on forget trials than on remember trials, F(1, 28) = 11.25, MSe = 166.87, p < .01, ges = .18; at postinstruction position 5, probe identification accuracy was 9% higher on forget trials than on remember trials, F(1, 28) = 8.09, MSe = 144.09, p < .01, ges = .11. In other words, the attentional blink resolved sooner following a forget instruction than following a remember instruction.
Given that more words were committed to memory following a remember instruction than following a forget instruction, an obvious question is whether probe identification accuracy depended primarily on the intention to remember or forget or on the outcome of that intention (i.e., study word remembered or forgotten). To address this question, the overall accuracy of probe identification was analyzed as a function of memory instruction (remember, forget) and post hoc recognition outcome (remembered, forgotten).Footnote 1 This analysis reiterated a significant main effect of memory instruction, F(1, 28) = 5.17, MSe = 90.54, p < .04, ges = .04, with overall greater probe identification accuracy on forget trials than on remember trials. There was, however, no significant effect of recognition outcome on probe identification accuracy, F(1, 28) = 1.08, MSe = 98.77, p > .30, ges < .01, and no significant interaction of memory instruction and recognition outcome, F(1, 28) = 1.48, MSe = 47.47, p > .23, ges < .01. Although caution is always needed in interpreting null effects, the fact that recognition outcome did not produce discernable effects suggests that memory intention may be more important than memory outcome for determining subsequent probe identification accuracy.
The same conclusion was reached when the analysis was restricted to probe identification accuracy at postinstruction positions 4 and 5—those positions at which probe performance differed significantly on remember and forget trials. This analysis required data for each combination of memory instruction (remember, forget), postinstruction probe position (4, 5), and recognition outcome (remembered, forgotten). This condition was satisfied by 20 participants. An analysis of their data revealed a significant effect of memory instruction, F(1, 19) = 9.68, MSe = 326.45, p < .01, ges = .05, with overall greater probe identification accuracy on forget trials (M = 89%) than on remember trials (M = 81%). There was also a significant effect of postinstruction probe position, F(1, 19) = 15.55, MSe = 231.95, p < .01, ges = .06, with greater probe identification accuracy at position 5 (M = 88%) than at position 4 (M = 81%). Given that performance was assessed at two temporally adjacent locations, there was no significant interaction of memory instruction and probe position, F(1, 19) = 1.47, MSe = 338.46, p > .24, ges < .01. Critically, there was also no significant main effect of recognition outcome, F(1, 19) = 1.99, MSe = 472.67, p > .17, ges = .02, and no significant interaction of recognition outcome with memory instruction and/or probe position, all ps > .19. Thus, even when the analysis was limited to those postinstruction probe positions at which remember and forget performance diverged, there continued to be no discernable effect of memory outcome on probe identification accuracy; instead, memory intention (viz. memory instruction) seems to be the more important variable.
Discussion
The recognition results of Experiment 2 revealed a directed forgetting effect, with better subsequent recognition of words participants were instructed to remember than those they were instructed to forget. The similarity of recognition performance across Experiments 1 and 2 is remarkable. Whereas the remember-all group in Experiment 1 recognized 50% of study words, participants in Experiment 2 recognized 47% of remember words; whereas the remember-none group in Experiment 1 recognized 23% of study words, participants in Experiment 2 recognized an identical 23% of forget words. False alarms were also comparable across the two experiments, with a false alarm rate of 13% for both the remember-all and remember-none groups of Experiment 1 and 14% for Experiment 2. Particularly when considered in the context of Experiment 1, the recognition results of Experiment 2 underscore the efficacy with which participants were able to discern and implement the trial-by-trial instructions to remember and forget.
Whether participants were instructed to remember or forget, there was an attentional blink for the subsequent probe string. As in Experiment 1, the act of presenting a colored word in a stream of black nonsense strings should have generated an attentional blink in both the remember and forget conditions of Experiment 2—by virtue of automatic word processing on at least some portion of trials. This automatic word processing would have been compounded in Experiment 2 by the additional processing demands that were not present in Experiment 1. In Experiment 1, participants knew in advance whether they needed to commit each study word to memory. In Experiment 2, participants did not know this. On both remember and forget trials, participants needed to attend to each study word as it was presented and to maintain its representation in working memory until they had the opportunity to detect, interpret, and implement the subsequent memory instruction. The similarity of these early processing demands on remember and forget trials likely explains why probe accuracy did not differ significantly at postinstruction probe positions 1–3. However, by postinstruction probe positions 4–5, performance diverged. This divergence is consistent with earlier improvement in probe identification in the forget condition than in the remember condition. Indeed, it was not until postinstruction probe positions 6–8 that probe identification accuracy in the remember condition improved to the same levels as the forget condition.
General discussion
An attentional blink occurs when the processing of an initial target item in an RSVP stream consumes limited-capacity attentional resources, making them relatively unavailable for subsequent item processing (for reviews, see Dux & Marois, 2009; Snir & Yeshurun, 2017). In the current task, a single word was embedded in a stream of nonsense strings. This was followed immediately by a string of rs or fs that could serve as instructions to remember or forget, respectively. A probe string consisting of xs or os appeared subsequently in postinstruction positions 1–8; an attentional blink was assessed by measuring probe identification accuracy as a function of postinstruction position. In Experiment 1, different groups of participants were required to commit all study words to memory (remember all) or to commit none of those words to memory (remember none)—without reference to the memory instruction embedded in the RSVP stream. A subsequent yes–no recognition test confirmed that the remember-all group remembered more study words than did the remember-none group. This was taken as evidence that the remember-all requirement prompted greater study word processing than the remember-none requirement. Correspondingly, the attentional blink was more pronounced in the remember-all group than in the remember-none group. This result was used to establish that the attentional blink (1) indexes the relative amount of processing given to study words and (2) does so even when an explicit trial-by-trial report of study word identity is not required.
With these two points in mind, Experiment 2 required participants to use the embedded memory instruction to remember or to forget study words on a trial-by-trial basis. A yes–no recognition test confirmed a directed forgetting effect, with better subsequent recognition of remember words than forget words. Indeed, the overall recognition hit rate in the remember condition of Experiment 2 was comparable to that in the remember-all group of Experiment 1, and incidental memory formation in the forget condition of Experiment 2 was numerically identical to that in the remember-none group of Experiment 1. Clearly, participants were able to flexibly allocate processing resources to study words according to whether the instruction embedded in the RSVP stream was to remember or to forget. Given that this was the case, the critical finding was that the attentional blink for the subsequent probe string resolved sooner following a forget instruction than following a remember instruction. The interpretation offered here for this novel finding is that the instruction to forget liberates limited-capacity attentional resources from further unwanted study word processing. Consequently, these resources are available sooner for probe identification that follows a forget instruction rather than a remember instruction.
An alternative interpretation of the current result derives from the knowledge that the effects of memory instruction on the attentional blink is based on a difference between the remember and forget conditions: This difference can be attributed to the earlier availability of processing resources following a forget instruction and/or the later availability of processing resources following a remember instruction. Framing the comparison in terms of earlier resolution of the attentional blink in the forget condition implicates a removal of attentional resources from unwanted forget word processing. In contrast, framing the comparison in terms of later availability of processing resources in the remember condition implicates prolonged engagement of resources during the commitment of the study word to memory. While the latter mechanism cannot be ruled out completely, it seems an unsatisfactory explanation given the time course of the differences between remember and forget trials.
The attentional blink differed on remember and forget trials only during the temporal interval defined by postinstruction probe positions 4 and 5. With a presentation rate of 10 items/sec, or one item every 100 ms, this difference therefore first emerged 400 ms after the embedded memory instruction. The difference did not last for more than 200 ms (i.e., there was no difference by 600 ms postinstruction). The mechanism that distinguishes probe identification performance on forget and remember trials must therefore come online swiftly (within 400 ms) and be active for a relatively short period of time (<200 ms). Attributing the difference primarily to operations engaged by the instruction to remember presumes that committing a study word to long-term memory can be accomplished in this time frame.Footnote 2 This does not accord with imaging results. Using event-related potentials, it is possible to identify neural activity at encoding that predicts later recognition success rather than failure. These subsequent memory effects are defined by enhanced posterior positivity that occurs at a latency of ~400–800 ms poststimulus (see Paller & Wagner, 2002). Given that behavioral effects manifest later than the neural signatures that give rise to those effects, this neural signature of successful encoding occurs too late and extends too long to account for the differences observed at postinstruction positions 4 and 5. In contrast, shifting attention is marked by changes in some of the earliest ERP component waveforms—P1 and N1 (e.g., Natale, Marzi, Girelli, Payone, & Pollmann, 2006). And attention effects are evidenced in behavior within approximately 100 ms when performed automatically and 400 ms when performed top down (e.g., Müller & Rabbitt, 1989; see Egeth & Yantis, 1997, for a review). It therefore seems more likely that faster-acting attentional processes are responsible for rapid resolution of the attentional blink on forget trials, rather than longer-acting memorial processes extending the attentional blink on remember trials.
The directed forgetting effect in an item-method paradigm is attributed to selective rehearsal of remember over forget items (e.g., Basden et al., 1993; MacLeod, 1998; Taylor et al., 2017; although see Rummel et al., 2016). Positing a more rapid withdrawal of attention following forget word processing than following remember word processing is consistent with the view that this differential rehearsal does not arise solely from processes aimed at committing the remember words to long-term memory. Instead, selective rehearsal of remember over forget items is made possible, in part, by the activation of frontal control processes (Bastin et al., 2012; Hauswald et al., 2010; van Hooff & Ford, 2011; Wylie et al., 2008; Yang et al., 2012) that halt further unwanted item rehearsal (cf. Hourihan & Taylor, 2006) by removing forget words from the focus of attention. Although commitment to long-term memory cannot be prevented entirely (e.g., Lee, Lee, & Tsai, 2007; see also Bancroft, Hockey, & Farquhar, 2013), the probability of forming an unwanted memory trace is reduced and so too is the quality of any trace that defies the intention to forget (Fawcett, Lawrence, & Taylor, 2016; see also Thompson, Fawcett, & Taylor, 2011). Interestingly, the intention to forget an unwanted study word also reduces the likelihood of forming an incidental memory for other items that appear during the encoding epoch (Fawcett & Taylor, 2012). This, along with the observation that IOR is larger following a forget instruction than following a remember instruction (Fawcett & Taylor, 2010; Taylor, 2005; Taylor & Fawcett, 2011; Thompson et al., 2014; Thompson & Taylor, 2015) is consistent with the interpretation of current results as implicating a removal of attentional resources from forget word processing. Interestingly, there is no indication that these resources are reallocated to other internal representations of the encoding epoch (Taylor & Fawcett, 2012) or become vulnerable to capture by other potential distractors (Taylor & Hamm, 2016). Instead, it seems likely that the effort needed to forget is expended precisely because attentional resources are taxed and need to be conserved for other ongoing task demands (Lee, 2012; Lee & Lee, 2011), including the commitment of remember items to long-term memory.
The current study cannot address what happens to attentional resources after the end of the study trial, once the probe has been identified and reported. It seems likely that it is during this time that current-trial remember words are elaborated and/or previous-trial remember words are retrieved and rehearsed. The probe identification task was able to index the relative availability of attentional resources in the short term—withdrawing relatively quickly from the unwanted forget word to support subsequent probe string identification. However, in a typical directed forgetting task, there is no secondary target/probe that requires postinstruction processing. Instead, the only task is to commit remember words to long-term memory while excluding forget words. In this case, logic dictates that the attentional resources that are liberated from forget word processing are redirected immediately to cumulative rehearsal of remember words from preceding trials. In this way, the effortful removal of processing resources from forget word processing ultimately aids memory by making limited-capacity resources available for the selective rehearsal of remember words.
Conclusion
This is the first study to use an attentional blink to assess the temporal dynamics of resource allocation during directed forgetting. The key finding is that the attentional blink ends sooner following a forget instruction than following a remember instruction. Although this difference might be explained as prolongation of the attentional blink by ongoing resource allocation to remember words, it seems more likely—and more parsimonious (see footnote 1)—to presume that the attentional blink is resolved earlier by a liberation of limited-capacity resources from further forget word processing. In the short term, these freed resources become available for identifying the probe string; however, in a more typical directed forgetting task, they would presumably become available to support the commitment of remember words to long-term memory. In any case, there are clearly processing differences that occur following instructions to remember and forget. These processing differences point to the need to further understand how memory intentions recruit and depend on mechanisms of attentional control.
Author note
Thanks to Colin McCormick for help collecting the data for this study and to participants for volunteering their time to contribute to this research. Thanks also to Dr. Colin MacLeod and an anonymous reviewer for their feedback on this manuscript. Project funding was provided by a Discovery Grant awarded to T.L.T. by the Natural Sciences and Engineering Research Council of Canada.
Notes
It was not possible to include postinstruction probe positions 1–8 in this analysis. This is because not every participant produced both recognition hits (remembered) and recognition misses (forgotten) at both levels of the memory instruction (remember, forget) and across all eight postinstruction probe positions.
Or, less parsimoniously, that limited-capacity resources remain engaged on remember word processing for a relatively brief interval, shift to the probe identification task in time to generate excellent identification accuracy at the final postinstruction positions, and return to complete remember word processing and commitment of the item to memory.
References
Akyürek, E. G., Hommel, B., & Jolicoeur, P. (2007). Direct evidence for a role of working memory in the attentional blink. Memory & Cognition, 35(4), 621–627.
Anderson, M. C., & Hanslmayr, S. (2014). Neural mechanisms of motivated forgetting. Trends in Cognitive Sciences, 18(6), 279–292.
Aron, A. R., Fletcher, P. C., Bullmore, E. T., Sahakian, B. J., & Robbins, T. W. (2003). Stop-signal inhibition disrupted by damage to right inferior frontal gyrus in humans. Nature Neuroscience, 6, 115–116.
Aron, A. R., & Poldrack, R. A. (2006). Cortical and subcortical contributions to stop signal response inhibition: Role of the subthalamic nucleus. Journal of Neuroscience, 26(9), 2424–2433.
Aron, A. R., Robbins, T. W., & Poldrack, R. A. (2004). Inhibition and the right inferior frontal cortex. Trends in Cognitive Sciences, 8(4), 170–177.
Bancroft, T. D., Hockley, W. E., & Farquhar, R. (2013). The longer we have to forget the more we remember: The ironic effect of postcue duration in item-based directed forgetting. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(3), 691–699.
Basden, B. H., & Basden, D. R. (1998). Directed forgetting: A contrast of methods and interpretations. In J. M. Golding & C. M. MacLeod (Eds.), Intentional forgetting: Interdisciplinary approaches (pp. 139–172). Mahwah: Erlbaum.
Basden, B. H., Basden, D. R., & Gargano, G. J (1993). Directed forgetting in implicit and explicit memory tests: A comparison of methods. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(3), 603–616.
Bastin, C., Feyers, D., Majerus, S., Balteau, E., Degueldre, C., Luxen, A., … Collette, F. (2012). The neural substrates of memory suppression: A FMRI exploration of directed forgetting. PLOS ONE, 7(1), e29905.
Berlucchi, G. (2006). Inhibition of return: A phenomenon in search of a mechanism and a better name. Cognitive Neuropsychology, 23(7), 1065–1074.
Berlucchi, G., Chelazzi, L., & Tassinari, G. (2000). Volitional covert orienting to a peripheral cue does not suppress cue-induced inhibition of return. Journal of Cognitive Neuroscience, 12(4), 648–663.
Bjork, R. A. (1970). Positive forgetting: The noninterference of items intentionally forgotten. Journal of Verbal Learning and Verbal Behavior, 9(3), 255–268.
Bjork, R. A. (1972). Theoretical implications of directed forgetting. In A.W. Melton & E. Martin (Eds.), Coding processes in human memory (pp. 217–235). Washington, DC: Winston.
Bjork, R. A., (1989). Retrieval inhibition as an adaptive mechanism in human memory. In H. L. Roediger, III, & F. I. M. Craik (Eds.), Varieties of memory and consciousness: Essays in honour of Endel Tulving (pp. 309–330). Hillsdale: Erlbaum.
Bjork, R. A., Bjork, E. L., & Anderson, M. C. (1998). Varieties of goal-directed forgetting. In J. M. Golding & C. M. MacLeod (Eds.), Intentional forgetting: Interdisciplinary approaches (pp. 103–137). Mahwah: Erlbaum.
Broadbent, D. E., & Broadbent, M. H. (1987). From detection to identification: Response to multiple targets in rapid serial visual presentation. Perception & Psychophysics, 42(2), 105–113.
Cheng, S., Liu, I., Lee, J. R., Hung D. L., & Tzeng, O. J-L. (2012). Intentional forgetting might be more effortful than remembering: An ERP study of item-method directed forgetting. Biological Psychology, 89(2), 283–292.
Chica, A. B., Lupiáñez, J., & Bartolomeo, P. (2006). Dissociating inhibition of return from endogenous orienting of spatial attention: Evidence from detection and discrimination tasks. Cognitive Neuropsychology, 23(7), 1015–1034.
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21(1), 109–127.
Coltheart, M. (1981). The MRC psycholinguistic database. Quarterly Journal of Experimental Psychology, 33A, 497–505.
R Core Team. (2017). R: A language and environment for statistical computing [Computer language]. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from URL http://www.R-project.org/
Danziger, S., & Kingstone, A. (1999). Unmasking the inhibition of return phenomenon. Perception and Psychophysics, 61(6), 1024–1037.
Dell’Acqua, R., Jolicœur, P., Pascali, A., & Pluchino, P. (2007). Short-term consolidation of individual identities leads to lag-1 sparing. Journal of Experimental Psychology: Human Perception and Performance, 33, 593–609.
Dell’Acqua, R., Jolicœur, P., Luria, R., & Pluchino, P. (2009). Reevaluating encoding-capacity limitations as a cause of the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 35 (2), 338–351.
Dux, P. E., & Marois, R. (2009). The attentional blink: A review of data and theory. Attention, Perception, & Psychophysics, 71(8), 1683–1700.
Egeth, H. E., & Yantis, S. (1997). Visual attention: Control, representation, and time course. Annual Review of Psychology, 48(1), 269–297.
Fawcett, J. M., Lawrence, M. A., & Taylor, T. L. (2016). The representational consequences of intentional forgetting: Impairments to both the probability and fidelity of long-term memory. Journal of Experimental Psychology: General, 145(1), 56–81.
Fawcett, J. M., & Taylor, T. L. (2008). Forgetting is effortful: Evidence from reaction time probes in an item-method directed forgetting task. Memory & Cognition, 36(6), 1168–1181.
Fawcett, J. M., & Taylor, T. L. (2010). Directed forgetting shares mechanisms with attentional withdrawal but not stop-signal inhibition. Memory & Cognition, 38(6), 797–808.
Fawcett, J. M., & Taylor, T. L. (2012). The control of working memory resources in intentional forgetting: Evidence from incidental probe word recognition. Acta Psychologica, 139, 84–90.
Gardiner, J. M., Gawlik, B., & Richardson-Klavehn, A. (1994). Maintenance rehearsal affects knowing, not remembering; elaborative rehearsal affects remembering, not knowing. Psychonomic Bulletin & Review, 1(1), 107–110.
Hauswald, A., Schulz, H., Iordanov, T., & Kissler, J. (2010). ERP dynamics underlying successful directed forgetting of neutral but not negative pictures. Social Cognitive and Affective Neuroscience, 6(4), 450–459.
Hommel, B., & Akyürek, E. G. (2005). Lag-1 sparing in the attentional blink: Benefits and costs of integrating two events into a single episode. The Quarterly Journal of Experimental Psychology Section A, 58(8), 1415–1433.
Hourihan, K. L., & Taylor, T. L. (2006). Cease remembering: Control processes in directed forgetting. Journal of Experimental Psychology: Human Perception and Performance, 32(6), 1354–1365.
Hsieh, L. T., Hung, D. L., Tzeng, O. J. L., Lee, J. R., & Cheng, S. K. (2009). An event-related potential investigation of the processing of Remember/Forget cues and item encoding in item-method directed forgetting. Brain Research, 1250, 190–201.
Johnston, S. J., Linden, D. E., & Shapiro, K. L. (2012). Functional imaging reveals working memory and attention interact to produce the attentional blink. Journal of Cognitive Neuroscience, 24(1), 28–38.
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Science, 4(4), 138–147.
Kučera, H., & Francis, W. N. (1967). Computational analysis of present-day American English. Dartmouth Publishing Group: Sudbury.
Lawrence , M. A. (2016). ez: Easy analysis and visualization of factorial experiments (Package Version 4.4-0) [Computer software]. Retrieved from https://CRAN.R-project.org/package=ez
Lee, Y. S. (2012). Cognitive load hypothesis of item-method directed forgetting. The Quarterly Journal of Experimental Psychology, 65(6), 1110–1122.
Lee, Y. S. (2018). Withdrawal of spatial overt attention following intentional forgetting: Evidence from eye movements. Memory, 26(4), 503–513.
Lee, Y. S., & Lee, H. M. (2011). Divided attention facilitates intentional forgetting: Evidence from item-method directed forgetting. Consciousness & Cognition, 20(3), 618–626.
Lee, Y. S., Lee, H. M., & Tsai, S. H. (2007). Effects of post-cue interval on intentional forgetting. British Journal of Psychology, 98(2), 257–272.
Lupiáñez, J., Decaix, C., Siéroff, E., Chokron, S., Milliken, B., & Bartolomeo, P. (2004). Independent effects of endogenous and exogenous spatial cueing: Inhibition of return at endogenously attended target locations. Experimental Brain Research, 159, 447–457.
MacLeod, C. M. (1991). Half a century of research on the Stroop effect: An integrative review. Psychological Bulletin, 109(2), 163–203.
MacLeod, C. M. (1998). Directed forgetting. In J. M. Golding & C. M. MacLeod (Eds.), Intentional forgetting: Interdisciplinary approaches (pp. 1–57). Mahwah: Erlbaum.
MacLeod, C. M. (1999). The item and list methods of directed forgetting: Test differences and the role of demand characteristics. Psychonomic Bulletin & Review, 6(1), 123–129.
Maki, W. S., & Mebane, M. W. (2006). Attentional capture triggers an attentional blink. Psychonomic Bulletin & Review, 13(1), 125–131.
Martens, S., & Wyble, B. (2010). The attentional blink: Past, present, and future of a blind spot in perceptual awareness. Neuroscience & Biobehavioral Reviews, 34(6), 947–957.
Müller, H. J., & Rabbitt, P. M. (1989). Reflexive and voluntary orienting of visual attention: Time course of activation and resistance to interruption. Journal of Experimental Psychology: Human Perception and Performance, 15(2), 315–330.
Natale, E., Marzi, C. A., Girelli, M., Pavone, E. F., & Pollmann, S. (2006). ERP and fMRI correlates of endogenous and exogenous focusing of visual-spatial attention. European Journal of Neuroscience, 23(9), 2511–2521.
Olivers, C. N., & Nieuwenhuis, S. (2005). The beneficial effect of concurrent task-irrelevant mental activity on temporal attention. Psychological Science, 16(4), 265–269.
Olivers, C. N., & Nieuwenhuis, S. (2006). The beneficial effects of additional task load, positive affect, and instruction on the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 32(2), 364–379.
Olson, I. R., Chun, M. M., & Anderson, A. K. (2001). Effects of phonological length on the attentional blink for words. Journal of Experimental Psychology: Human Perception and Performance, 27(5), 1116–1123.
Paller, K. A., & Wagner, A. D. (2002). Observing the transformation of experience into memory. Trends in Cognitive Sciences, 6(2), 93–102.
Paz-Caballero, M. D., Menor, J., & Jiménez, J. M. (2004). Predictive validity of event-related potentials (ERPs) in relation to the directed forgetting effects. Clinical Neurophysiology, 115(2), 369–377.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. Bouwhuis (Eds.), Attention and Performance X: Control of language processes (pp. 531–556). Hillsdale: Erlbaum.
Potter, M. C., Chun, M. M., Banks, B. S., & Muckenhoupt, M. (1998). Two attentional deficits in serial target search: The visual attentional blink and an amodal task-switch deficit. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(4), 979–992.
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 18(3), 849–860.
Rizio, A. A., & Dennis, N. A. (2013). The neural correlates of cognitive control: Successful remembering and intentional forgetting. Journal of Cognitive Neuroscience, 25(2), 297–312.
Rummel, J., Marevic, I., & Kuhlmann, B. G. (2016). Investigating storage and retrieval processes of directed forgetting: A model-based approach. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(10), 1526.
Snir, G., & Yeshurun, Y. (2017). Perceptual episodes, temporal attention, and the role of cognitive control: Lessons from the attentional blink. In C. J. Howard (Ed.), Progress in Brain Research (Vol. 236, pp. 53–73). Amsterdam: Elsevier.
Stein, T., Zwickel, J., Kitzmantel, M., Ritter, J., & Schneider, W. X. (2010). Irrelevant words trigger an attentional blink. Experimental Psychology, 51, 301–307.
Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18(6), 643–662.
Taylor, T. L. (2005). Inhibition of return following instructions to remember and forget. The Quarterly Journal of Experimental Psychology, 58A(4), 613–629 (Erratum in 58A, 1343).
Taylor, T. L., Cutmore, L., & Pries, L. (2018). Item-method directed forgetting: Effects at retrieval? Acta Psychologica, 183, 116–123. https://doi.org/10.1016/j.actpsy.2017.12.004
Taylor, T. L., & Fawcett, J. M. (2011). Larger IOR effects following forget than following remember instructions depend on exogenous attentional withdrawal and target localization. Attention, Perception, & Psychophysics, 73(6), 1790–1814.
Taylor, T. L., & Fawcett, J. M. (2012). Does an instruction to forget enhance memory for other presented items? Consciousness & Cognition, 21(3), 1186–1197.
Taylor, T. L., & Hamm, J. P. (2016). Selection for encoding: No evidence of greater attentional capture following forget than remember instructions. Attention, Perception, & Psychophysics, 78(1), 168–186.
Taylor, T. L., & Klein, R. M. (1998). On the causes and effects of inhibition of return. Psychonomic Bulletin & Review, 5(4), 625–643.
Thompson, K. M., & Taylor, T. L. (2015). Memory instruction interacts with both visual and motoric inhibition of return. Attention, Perception, & Psychophysics, 77(3), 804–818.
Thompson, K. M., Fawcett, J. M., & Taylor, T. L. (2011). Tag, you’re it: Tagging as an alternative to yes/no recognition in item method directed forgetting. Acta Psychologica, 138(1), 171–175.
Thompson, K. M., Hamm, J. P., & Taylor, T. L. (2014). Effects of memory instruction on attention and information processing: Further investigation of inhibition of return in item-method directed forgetting. Attention, Perception, & Psychophysics, 76(2), 322–334.
Thomson, D. R., Ralph, B. C., Besner, D., & Smilek, D. (2015). The more your mind wanders, the smaller your attentional blink: An individual differences study. The Quarterly Journal of Experimental Psychology, 68(1), 181–191.
van Hooff, J. C., & Ford, R. M. (2011). Remember to forget: ERP evidence for inhibition in an item-method directed forgetting paradigm. Brain Research, 1392, 80–92.
Visser, T. A., Bischof, W. F., & Di Lollo, V. (1999). Attentional switching in spatial and nonspatial domains: Evidence from the attentional blink. Psychological Bulletin, 125(4), 458–469.
Wickham, H. (2009). ggplot2: Elegant graphics for data analysis [Computer software]. New York: Springer. Retrieved from http://had.co.nz/ggplot2/book
Wickham, H. (2011). The split-apply-combine strategy for data analysis. Journal of Statistical Software, 40(1), 1–29. Retrieved from http://www.jstatsoft.org/v40/i01/
Wickham, H. (2017a). stringr: Simple, consistent wrappers for common string operations (Package Version 1.2.0) [Computer software]. Retrieved from https://CRAN.R-project.org/package=stringr
Wickham, H. (2017b). tidyr: Easily tidy data with spread() and gather() functions (R Package Version 0.6.3) [Computer software]. Retrieved from http://CRAN.R-project.org/package=tidyr
Wickham, H., & Francois, R. (2016). dplyr: A grammar of data manipulation (R Package Version 0.5.0) [Computer software]. Retrieved from http://CRAN.R-project.org/package=dplyr
Wilson, M. (1988). MRC psycholinguistic database: Machine-usable dictionary, version 2.00. Behavior Research Methods, Instruments, & Computers, 20(1), 6–10.
Wylie, G. R., Foxe, J. J., & Taylor, T. L. (2008). Forgetting as an active process: An fMRI investigation of item-method directed forgetting. Cerebral Cortex, 18(3), 670–682.
Yang, W., Liu, P., Xiao, X., Li, X., Zeng, C., Qui, J., & Zhang, Q. (2012). Different neural substrates underlying directed forgetting for negative and neutral images: An event-related potential study. Brain Research, 1441, 53–63.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Taylor, T.L. Remember to blink: Reduced attentional blink following instructions to forget. Atten Percept Psychophys 80, 1489–1503 (2018). https://doi.org/10.3758/s13414-018-1528-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1528-5