
Abstract
Speeded naming and lexical decision data for 1,661 target words following related and unrelated primes were collected from 768 subjects across four different universities. These behavioral measures have been integrated with demographic information for each subject and descriptive characteristics for every item. Subjects also completed portions of the Woodcock–Johnson reading battery, three attentional control tasks, and a circadian rhythm measure. These data are available at a user-friendly Internet-based repository (http://spp.montana.edu). This Web site includes a search engine designed to generate lists of prime–target pairs with specific characteristics (e.g., length, frequency, associative strength, latent semantic similarity, priming effect in standardized and raw reaction times). We illustrate the types of questions that can be addressed via the Semantic Priming Project. These data represent the largest behavioral database on semantic priming and are available to researchers to aid in selecting stimuli, testing theories, and reducing potential confounds in their studies.
Similar content being viewed by others

The semantic priming project
There is an extensive literature concerning the influence of semantic/associative context on word recognition (see McNamara, 2005; Neely, 1991). This work has been critical in developing a better understanding of the nature of semantic representations, lexical retrieval processes, automatic and attentional mechanisms, and differences across various populations. In the semantic priming paradigm, subjects are presented with a target word (e.g., table) for a speeded response (typically, pronunciation or lexical decision) that was immediately preceded by either a related (e.g., chair) or an unrelated (e.g., watch) prime word. The semantic priming effect refers to the consistent finding that people respond faster to target words preceded by related, relative to unrelated, primes.
The vast majority of semantic priming studies have employed factorial experimental designs in which the effect of prime–target relatedness is crossed with another variable or variables to test for interactions in which the size of priming depends upon another variable or combination of variables. These other variables may include (1) target lexical characteristics (Becker, 1979; Cortese, Simpson, & Woolsey, 1997), (2) prime or target visibility (Balota, 1983; Balota, Yap, Cortese, & Watson, 2008; Kiefer & Martens, 2010; Stolz & Neely, 1995; Thomas, Neely, & O’Connor, 2012), (3) response tasks (Hutchison, Balota, Cortese, & Watson, 2008; Kahan, Neely, & Forsythe, 1999; Pecher, Zeelenberg, &Raaijmakers, 1998), (4) prime–target relation type (Chiarello, Burgess, Richards, & Pollock, 1990; Hodgson, 1991; Moss, Ostrin, Tyler, & Marslen-Wilson, 1995), and (5) developmental or individual differences (Balota & Duchek, 1988; Moritz, Woodward, Küppers, Lausen, & Schickel, 2003; Plaut & Booth, 2000; Stanovich & West, 1979). Interactions within such factorial designs have provided the foundation for developing theories of semantic organization of knowledge and memory retrieval. For instance, research has shown that priming is increased when targets are low frequency, especially among subjects with low vocabulary knowledge (Yap, Tse, & Balota, 2009). Findings such as these suggest that semantic context is relied upon more heavily when target words are difficult to recognize (Stanovich & West, 1979; see Hutchison et al., 2008, for additional evidence).
Unfortunately, the sole reliance on factorial designs can also lead to selection artifacts and limited generalizability (see Balota, Yap, Hutchison, & Cortese, 2012, for a review). The confounding variable problem derives from selecting items or subjects that fit various conditions. In most semantic priming experiments, the semantic priming effect itself is an internally valid assessment because researchers counterbalance primes and targets across related and unrelated conditions by re-pairing the related prime–target pairs to create unrelated pairs. However, if a researcher decides to examine differences in priming as a function of another variable, the other variable is often selected (e.g., high- vs. low-frequency targets or associative vs. categorical prime–target relations), rather than being randomly assigned. The critical assumption of such selection is that one can equate the stimuli on all other relevant variables (e.g., prime and target letter length, number of syllables, printed word frequency, bigram frequency, orthographic or phonological neighborhood, imageability, concreteness, meaningfulness, etc.). Because so many variables have been identified that influence word recognition performance (see Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004), some have argued that this may be an impossible task (Cutler, 1981). Indeed, studies examining priming for categorically related (e.g., horse–deer) versus associatively related (e.g., sky–blue) pairs often confound type of relation with target frequency such that associatively related targets are higher in frequency (Bueno & Frenk-Mastre, 2008; Ferrand & New, 2003; Williams, 1996). Because low-frequency words typically show larger priming effects (Becker, 1979), this can artificially inflate the importance of categorical, relative to associative, relations (see Hutchison, 2003).
In developmental, individual-difference studies of semantic priming, groups are also selected, rather than assigned. As with item effects, subject differences in visual acuity, working memory capacity, vocabulary, reading comprehension, circadian rhythm, perceptual ability, and general processing speed could influence semantic priming effects. It is virtually impossible to control for all these factors when testing group-level interactions with priming. One confound that often occurs with group studies is overall differences in processing speed. If reaction times (RTs) are not first standardized within subjects, priming effects from slower groups will be artificially inflated, and an artifactual group × priming interaction will be found (Faust, Balota, Spieler, & Ferraro, 1999), which researchers may then misinterpret as hyper-priming (see Morgan, Rothwell, Atkinson, Mason, & Curran, 2010, and Moritz et al., 2003, for claims of hyper-priming among certain groups).
In addition to problems with matching, there are potential list context effects. Specifically, in factorial designs in which a small number of extreme items (e.g., high- vs. low-frequency targets) are selected, subjects may alter their strategies on the basis of the list context and, therefore, limit the generalizability of the results. For instance, McKoon and Ratcliff (1995) showed that priming of a particular type of semantic relation (e.g., synonyms or antonyms) is modulated by the proportion of similar types of relations within a list, even when the overall proportion of related items in the list (i.e., the relatedness proportion) is held constant (also see Becker, 1980). Therefore, including an unusually large proportion of such items within a list likely inflates priming for that particular type of relation (e.g., category members, script-relations, antonyms, etc.) by making certain characteristics salient to subjects. For example, priming from perceptually similar items (e.g., coin–pizza) occurs only when such items constitute a majority of the list (see Hutchison, 2003; Pecher et al., 1998). Selecting extreme values should also increase the salience of prime and target item characteristics (e.g., word frequency, regularity, imageability, etc.) as well. Finally, using extreme values can reduce the power to detect true relationships between variables, eliminate the ability to detect nonlinear effects, and produce spurious effects that do not exist when the entire sample is considered (Cohen, Cohen, West, & Aiken, 2003). Thus, such extreme manipulations fail to capture the importance of the variable across its full range.
Given the limitations of factorial designs in the investigation of psycholinguistic variables, there has been increasing interest in developing large-scale databases to explore the influence of target variables on word recognition and pronunciation and the interrelations among them (Balota et al., 2007; Ferrand et al., 2010; Keuleers, Lacey, Rastle, & Brysbaert, 2012; Yap, Rickard Liow, Jalil, & Faizal, 2010). The emphasis in this approach is to test many subjects on a large number of stimuli and allow both item and subject characteristics to remain continuous, thus minimizing the problems of item selection and categorization discussed previously. For instance, the English Lexicon Project (ELP) tested 816 subjects across six universities on 40,481 words (roughly equivalent to the average high school graduate’s vocabulary) in both lexical decision and pronunciation tasks. In addition, an Internet Web site and search engine were created allowing researchers to access the behavioral measures and lexical characteristics for all stimuli. The resulting database was over 20 times larger than the next largest database and has been an invaluable resource for researchers (over 250 citations on Web of Science) in testing theories of word recognition using multiple regression, more effectively generating or selecting stimuli for factorial studies, and identifying the effects of confounds in previous studies. The ELP has recently inspired similar projects in other languages, such as French (Ferrand et al., 2010), Dutch (Keuleers, Diependaele, & Brysbaert, 2010), and Malay (Yap et al., 2010).
The semantic priming project
For the Semantic Priming Project (SPP), we extended the logic and methodology of the ELP to investigate the effects of semantic priming on word recognition. Similar to its predecessor, the ELP, the SPP is a National Science Foundation funded collaborative effort among four universities (Montana State University; University of Albany, SUNY; University of Nebraska, Omaha; and Washington University in St. Louis) to investigate a wide range of both item and individual differences in semantic priming. The resulting database (see http://spp.montana.edu) will hopefully aid researchers in advancing theories and computational models of the processes that allow humans to use context during lexical and semantic processing.
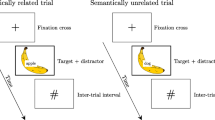
Aside from relatedness itself, arguably the two most important variables manipulated in semantic priming experiments for tapping underlying priming processes are target task and stimulus onset asynchrony (SOA) between the prime and target items. Semantic priming in speeded naming tasks is generally thought to be caused by prospective (forward-acting) priming mechanisms such as an automatic target activation or controlled expectancy generation process, whereas priming in lexical decision is thought to also involve a retrospective (backward-acting) relatedness checking/integration process (for reviews, see McNamara, 2005; Neely, 1991). Similarly, priming at shorter SOAs (e.g., under 300 ms) is thought to reflect automatic priming mechanisms, whereas priming at longer SOAs (e.g., over 300 ms) presumably reflects additional intentional strategies (Hutchison, Neely, & Johnson, 2001). Therefore, in the SPP, we chose to examine priming using both the lexical decision and speeded naming tasks and using SOAs of 200 and 1,200 ms. We anticipated that using these SOAs would allow examination of priming under more automatic and more intentional conditions for both tasks.
Method
Subjects
Subjects were native English speakers recruited from research subject pools in the four testing institutions (see Fig. 1 for a breakdown of the proportion of subjects from each institution and Tables 1 and 2 for descriptive statistics of subject demographics and SPP performance, respectively, for the two tasks). The universities included private and public institutions across the Midwest, Northeast, and Northwest regions of the United States, and at each institution, a word recognition researcher directed data collection. Subjects were paid either $30 or $40 for participation in the two sessions, or they received course credit in one or more of their undergraduate psychology courses. Five hundred twelve subjects participated in the lexical decision task, and 256 participated in the pronunciation task. Subjects took part in two different sessions that were conducted on different days, separated by no more than 1 week. Subjects received nine general demographic questions (e.g., age, gender, etc.) and four health questions (e.g., “compare your health over the past year with your peers on a scale of 1–7”) at the beginning of the first testing session, an attentional control battery (Hutchison, 2007) at the end of the first testing session, and the Morningness–Eveningness Questionnaire (a circadian rhythm questionnaire; Horne & Ostberg, 1976) and Woodcock–Johnson reading battery Woodcock, McGrew, & Mather, 2001) at the end of the second testing session. Each subject responded to 1,661 prime–target pairs during the semantic priming task. This resulted in approximately 208 target responses per subject in each of the prime type × relatedness × SOA conditions in the pronunciation task and 104 target responses in each of the prime type × relatedness × SOA × lexicality conditions in the lexical decision task. Because half of the trials in lexical decision involved nonword targets, twice as many subjects were tested to achieve the same number of responses per item. As a result, each item received responses from approximately 32 subjects in each condition for both the pronunciation and lexical decision tasks. This number of responses is comparable to that achieved in the ELP.

Proportion of subjects from each institution
Stimuli
One thousand six hundred and sixty one related prime–target pairs were selected from the Nelson, McEvoy, and Schreiber (1999) association norms, with the constraint that (1) no item occurred more than twice in the study (once as a prime and once as a target, presented on different days) and (2) each target was produced as the first-associate (most common) response to a cue word and also as an other-associate response (2nd – n) to a different word. A Microsoft Excel function was created to randomly select from the list of potential cues that are known to produce each other-associate target (e.g., the target money is given as a response to 302 different cues in Nelson et al., 1999, and one of these cues was randomly selected). Unrelated pairs were created by randomly re-pairing items within the first- and other-associate sets of related pairs, with the constraint that the prime and target were not associated in either the forward or backward direction. The relatedness proportion (RP; i.e., the proportion of word targets preceded by a related prime) was .50. Given the stated constraints concerning each word appearing once as a prime and once as a target and the necessity to re-pair the same targets and primes in related and unrelated contexts, we ran a selection algorithm over 3 days on the Nelson norms on two computers using the stated constraints, and over all iterations, 1,661 was the maximum number of pairings extracted that met all criteria. For each of the 1,661 targets, matched nonwords were generated by changing one or two letters to form a pronounceable nonword (not a pseudo-homophone). For the lexical decision task, half of the targets were switched to nonwords for each subject, so that an equal number of words and nonwords appeared within each session and each SOA. The nonword ratio (NWR; i.e., the proportion of unrelated prime–target pairs containing a nonword target) was .67. A total of 32 lists were required for the lexical decision task to rotate targets across the 2 (SOA) × 2 (session) × 2 (lexicality) × 2 (prime type) × 2 (relatedness) conditions. Because all targets in the pronunciation task were words, only 16 lists were needed.
In addition to the experimental stimuli, 20 practice items and 14 buffer items were constructed using prime and target words or nonwords that were not used in the experiment and using proportions of related, unrelated, and nonword pairs approximately equal to those used in the experiment. Each SOA block was preceded by 10 practice trials, and 2 buffer trials followed each rest break.
Procedure
In order to standardize presentation and data collection at each testing station, four identical Pentium IV, 3.2-GHz computers with 512 MB RAM and 17-in. VGA monitors were purchased, one for each site. Stimuli were presented using E-Prime software (Schneider, Eschman, & Zuccolotto, 2002), and a PST serial response box with an Audio-Technica ATR 20 low-impedance microphone recorded response latency for the pronunciation task. Each individually tested subject was seated approximately 60 cm from the monitor. Experimental stimuli were presented in 14-point Courier New font. Instructions were displayed on the monitor and paraphrased by the experimenter. Experimental trials were separated into two sessions consisting of either 830 or 831 trials, with two blocks of 415 or 416 trials within each session (a 200-ms SOA block and a 1,200-ms SOA block, counterbalanced for order). Each experimental trial began with a fixation cross presented in the center of the screen for 500 ms, followed by a prime word in uppercase letters for 150 ms. Next, a blank screen appeared for either 50 or 1,050 ms, creating a 200- or 1,200-ms SOA. A lowercase target was then presented until a response was given or 3,000 ms elapsed. Subjects were asked to respond both quickly and accurately. For the lexical decision task, subjects pressed either the “/” key labeled W for word or the “z” key labeled NW for nonword, and a 1,500-ms intertrial interval followed their response. For the pronunciation task, after the computer detected an auditory response, subjects scored their response, via a keypress, as (1) correct pronunciation, (2) unsure of pronunciation, (3) mispronunciation, or (4) extraneous voice key triggering (i.e., if the microphone fails to detect the voice or if it detects some extraneous sound). This coding scheme was used in the ELP and has been demonstrated to be successful in large-scale naming studies by Spieler and Balota (1997) and Balota et al. (2004). As with lexical decision, a 1,500-ms intertrial interval then preceded the start of the next trial. Subjects received 10 practice trials prior to each blocked SOA and received a rest break following every 100 experimental trials. Two buffer trials were also included after each rest break. These trials were not analyzed.
Description of lexical and behavioral measures
In this section, we describe the information that is available at the Web site at http://spp.montana.edu/. Descriptive statistics for target words (see Table 3) and prime words (Table 4), as well as measures of prime–target relatedness (Table 5), are included here. Interested users are encouraged to access the Web site to explore the range of variables available.
For correct RTs, a mean and standard deviation were calculated for each subject within each SOA and session, and any RT greater than 3 SDs above or below the mean for that subject during that SOA and session was identified as an outlier. This eliminated 1.7 % of both the lexical decision and naming RTs. The mean item latencies for pronunciation and lexical decision, along with z-score estimates, described below, are based on the remaining correct observations across the subjects who received that particular item in that particular condition.
Characteristics available for generating lists of items
Similar to the ELP, a main purpose of the SPP is to allow researchers to generate lists of items with specific constraints. From the homepage (http://spp.montana.edu/), one can choose to search either the lexical decision or the naming database and choose whether to search by subject or by item (see Fig. 2). When one searches the lexical decision or the naming data, the following five tabs are immediately visible.

Searching databases on the Semantic Priming Project homepage
Targets
The Targets tab (see Fig. 3) displays lexical characteristics for the targets used in the SPP study, as well as the previous estimates from the ELP and Nelson et al. (1999) studies.

Searching targets items within the lexical decision database
Target lexical characteristics
Length is the number of letters in the word.
SubFreq refers to the subtitle frequency of a word per 1 million words from the SUBTLEXUS corpus described in Brysbaert and New (2009).
LogSubFreq is the log10 transformed SubFreq.
LogHal refers to the log10 transformation of the Hyperspace Analogue to Language (HAL) frequency norms (Lund & Burgess, 1996), which consists of approximately 131 million words gathered across 3,000 Usenet newsgroups during February 1995.
OrthoN is the number of words that can be obtained by changing one letter while preserving the identity and positions of the other letters (i.e., Coltheart’s N; Coltheart, Davelaar, Jonasson, & Besner, 1977).
Freq_Greater is the number of orthographic neighbors of an item that are more frequent than that item, based on the HAL frequencies.
BGSum is the summed bigram frequency of a particular word, where bigram is defined as the sequence of two letters. The summed bigram frequency of a letter string (e.g., DOG) is the sum of the frequencies of its successive bigrams (i.e., DO and OG) across the entire English language.
BGMean refers to average bigram frequency, which is the summed bigram frequency divided by the number of successive bigrams.
POS refers to part of speech (i.e., how a word is used) and includes verbs, nouns, adjectives, and prepositions.
Target ELP behavioral measures and Nelson et al. (1999) fan-in
ELP RT refers to the average trimmed RT for a particular word by subjects in the ELP database. Note that ELP values that are shown when searching the lexical decision and naming databases are from the searched task.
ELP Z refers to the standardized mean ELP latency for a particular word using a z-score transformation that controls for individual differences in baseline RT and variability.
ELP Acc refers to the proportion of accurate responses for a particular word among ELP subjects, excluding outliers.
TargetFanin refers to the number of Nelson et al. (1999) word association norm cues that produce the particular target word as a response.
Assoc related
The Assoc Related tab (see Figs. 4 and 5) describes lexical characteristics of the first-associate primes, past ELP reaction times and errors on these primes, Nelson et al. (1999) fan-out for these primes, and descriptions of prime–target relatedness for these first-associate primes.

Searching first-associate prime characteristics within the lexical decision database

Searching first-associate prime–target relation characteristics and priming effects within the lexical decision database
First-associate lexical characteristics
The first two columns in the Assoc Related tab display each target and its respective first associate prime. The next nine columns display the lexical characteristics of each first-associate prime (e.g., length, Sub Freq, etc.). These are the same lexical characteristics used to describe targets in the Targets tab.
ELP reaction time and accuracy
The next three columns reflect ELP RT, z-score standardized RT, and accuracy rate for each first-associate related prime. As for the targets, these values come from the task being currently searched (lexical decision or naming).
Prime–target relatedness measures
The next six columns reflect the degree and type of relatedness between the first-associate prime and its related target. These columns are shown in Fig. 5. The Relation 1 and Relation 2 columns refer to the type of semantic relation according to the Hutchison (2003) relation categories. These include synonyms (e.g., frigid–cold), antonyms (hot–cold), category coordinates (e.g., table–chair), category superordinate relations (e.g., dog–animal), forward phrasal associates (fpa; e.g., help–wanted), backward phrasal associates (bpa; e.g., wanted–help), perceptual properties (e.g., canary–yellow) defined as a property of an object that can be perceived by one of the five senses, functional properties (e.g., broom–sweep) defined as a functional property of an object, script relations (e.g., restaurant–wine) defined as two objects commonly found in the same scene or event, instrument relations (e.g., broom–floor) in which the function of one is to perform an action on the other, actions (e.g., scrub–dishes) that simply describe an action, associated properties (e.g., deep–dark) defined as properties that tend to co-occur, and unclassified relations (e.g., mouse–cheese) that do not fit easily into any of the other categories. The reason there are two columns is that many pairs belong to more than one category. For instance, the pair taxi–cab is both a synonym and forward phrasal associate. The FAS and BAS columns refer to the forward and backward associative strength, respectively, between primes and targets according to the Nelson et al. (1999) norms. FAS refers to the proportion of subjects in the Nelson et al. word association norms who wrote down the target as the first word to come to mind after reading the prime. BAS refers to the proportion of subjects in the Nelson et al. word association norms who wrote down the prime word as the first word to come to mind after reading the target. CueFanOut refers to the number of targets given as a response to the prime word when it was used as a cue in the Nelson et al. norms. The next column corresponds to global co-occurrence between prime and target according to the Latent Semantic Analysis (LSA; Landauer & Dumais, 1997). Global co-occurrence models extract similarity in meaning between words based upon similar patterns of appearance across large bodies of text. We used the paired comparison similarity between prime and target as reported on the LSA Web site (http://lsa.colorado.edu/). This measure used the default number of factors (300) thought to reflect the model trained on general reading ability (up to first year of college).
Assoc unrel
As was mentioned in the Method section, the first-associate related items were randomly re-paired with targets to form unrelated pairs. Therefore, all of the lexical information for unrelated primes can be derived from the Assoc Related tab. There are no columns for associative strength, because these pairs were not associated and, therefore, have association strengths of 0. However, the LSA similarity for unrelated pairs was available and is reported below.
Prime–target relatedness measures
As with the Assoc Related pairs, the first two columns in the AssocUnrel tab display each of the targets and their respective first-associate unrelated primes. The next column refers to the LSA similarity index described above.
Other assoc related
As was mentioned previously, the other-associate related items consisted of prime words for which the target was given as a 2nd – N response in the Nelson et al. (1999) norms. The Other Assoc Related tab presents the targets and their other-associate primes in the first two columns. The next columns present each prime’s lexical characteristics, past ELP and Nelson et al. performance, and descriptions of prime–target relatedness. These measures are derived from the same sources as the first-associate related primes. In addition, the Other Assoc Related tab contains a column labeled rank, which refers to the rank order in which the target is given as a response to the prime in the Nelson et al. norms. For example, the most frequent associates to the cue maroon, in descending order, are color, red, island, stranded, alone, and abandon. Therefore, the rank for the pair maroon–abandon is 6. Anaki and Henik (2003) argued that associative rank order is a more important determinant of priming than associative strength. Indeed, Anaki and Henik (Experiment 1) found no difference in LDT priming between weak associates (FAS = .10) and strong associates (FAS = .42) as long as the item was the primary associate to the cue in word association norms. This variable may, therefore, be an important predictor of priming for other associates.
Other assoc unrel
The Other AssocUnrel column presents each of the targets and its respective other-associate unrelated prime, followed by the same LSA measure displayed for the first-associate unrelated pairs.
Behavioral measures
In addition to the prime lexical characteristics, past prime ELP performance, and prime–target relational measures, tabs 2–4 (Assoc Related, AssocUnrel, Other Assoc Related, Other Assoc, Unrel) also present current SPP task performance.
SPP task performance
The six columns following the relatedness measures in each of the four tabs reflect the RT, z-score, and accuracy measures in the current SPP for targets preceded by first-associate related primes, first-associate unrelated primes, other-associate related primes, and other-associate unrelated primes, respectively (see Fig. 5). The prefix LDT refers to the lexical decision task, and the prefix NT refers to the naming task. The 200 ms RT column is the mean response latency for a target following the first-associate prime in the 200-ms SOA condition across subjects. The 200 ms Z column is the standardized mean response latency for the target in the 200-ms SOA condition. Each subject’s raw response latency within each SOA and session was standardized using a z-score transformation, and the mean z-score for all subjects presented with the target in the particular condition was then computed. Because there is considerable variability across subjects in overall response latency and each subject receives the target only in a single priming condition, the standardized item score is the most accurate measure, minimizing the influence of a subject’s processing speed and variability (see Faust et al., 1999). This measure corrects for error variance associated with individuals’ overall response speed, such as might be created by having an overall slow subject respond to a target in a related condition and a fast subject responding to the same target in an unrelated condition. The 200 ms Acc column is the proportion of accurate responses for the target in the first-associate 200-ms SOA condition. The next three columns (1200 ms RT, 1200 ms Z, 1200 ms Acc) refer to the same measures taken within the 1,200-ms SOA condition.
SPP priming performance
The SPP priming effects for first associates and other associates were computed by subtracting SPP performance in the related condition from performance in the corresponding unrelated condition. For instance, first-associate RT priming for the target abandon at the 200-ms SOA is 46.25 ms, which reflects the RT to abandon following the unrelated first-associate prime provision (880.72) minus the RT to abandon following the related first-associate prime disown (834.47). Other-associate RT priming for the target abandon at the 200-ms SOA is −60.78 ms, which reflects the RT to abandon following the unrelated other-associate prime cure (742.90) minus the RT to abandon following the related other-associate prime maroon (803.69).
Individual subject data
Similar to the ELP, the construction of the SPP Web site allows investigators to search data either by items or by subjects. The following describes the list of parameters used for selection of lexical decision or naming data.
Subject characteristics
When searching either the lexical decision or the naming database by subject, the first tab contains subject demographics, survey responses, reading battery performance, and circadian rhythm responses (see Fig. 6).

Searching subject data from subjects within the lexical decision database
Subject demographics
The first five columns provide each subject’s responses to initial demographic questions regarding his or her age, gender, education level, and vision. Subjects were asked to report their education level in number of years. For vision, each subject rated his or her current vision on a scale of 1–7, with 1 representing excellent (20/20 or better) and 7 representing poor (20/50). This rating was based on corrective lenses if they were being worn.
Woodcock–Johnson III battery
The next four columns refer to performance on the vocabulary and passage comprehension subtests within the Woodcock–Johnson III diagnostic reading battery (Woodcock et al., 2001). The vocabulary measures included a synonym test, an antonym test, and an analogy test. The reading comprehension measure required subjects to read a short passage and identify a missing key word that made sense in the context of that passage.
Attentional control and circadian rhythm
The last two columns refer to a subject’s attentional control and circadian rhythm score. We measured attentional control using the Hutchison (2007) battery (described below) and circadian rhythm using the MEQ circadian rhythm questionnaire (Horne & Ostberg, 1976). The MEQ includes 19 questions, such as at what time of day do you think that you reach your “feeling best” peak, and is scored from 16 to 86, with higher scores reflecting “morning” types and low scores reflecting “evening” types.
Subjects’ task performance
The second tab presents each subject’s performance on word targets in the lexical decision or pronunciation task. Subjects’ mean accuracy, trimmed RT, and standard deviation are presented separately for each of the 16 session × SOA × prime type × relatedness conditions. The first four columns describe the subject number, the session number, the SOA, and the prime condition. The final three columns present each subject’s mean accuracy, trimmed RT, and standard deviation within that condition. For researchers interested in examining the preaggregated individual trials for all subjects, these data can be found at http://www.montana.edu/wwwpy/Hutchison/attmem_spp.htm.
Subjects’ nonword performance
The third tab presents each subject’s performance on nonword targets within the lexical decision task. For this tab, each subject’s mean accuracy, trimmed RT, and standard deviation are presented separately for each of the 4 session × SOA conditions. Once again, researchers interested in examining the preaggregated individual trials for all subjects should visit http://www.montana.edu/wwwpy/Hutchison/attmem_spp.htm.
Attentional control performance
The final tab provides each subject’s performance on the attentional control battery (Hutchison, 2007). This battery consists of three attention-demanding tasks (operation span, Stroop, antisaccade) designed to measure one’s ability to coordinate attention and memory in service of one’s current task goals by suppressing task-irrelevant information while maintaining or enhancing task-relevant information. The Stroop task consisted of 10 practice trials and 120 experimental trials that were divided into 36 congruent trials, 36 incongruent trials, and 48 neutral trials, randomly intermixed. The same outlier removal criterion used in the priming task was also applied to the Stroop task. The Stroop RT and error effects shown in columns 2 and 3, respectively, refer to each subject’s mean RT or error rate in the incongruent condition minus the mean RT or error rate in the congruent condition. In the automated version of the operation span task (Unsworth, Heitz, Schrolk, & Engle, 2005), participants used their mouse to answer true or false to math problems (e.g., 2 * 4 + 1 = 9) as quickly as possible. After each response, they were presented with a letter for 800 ms to hold in memory. After 3 to 7 sets of problems, participants were presented with a 3 × 4 matrix of letters and asked to click on the presented letters in the order in which they were shown. An individual’s OSPAN score (column 4) is the sum of all letters from sets in which all letters were recalled in the correct order. Scores range from 0 to 75. The Math Err column refers to subjects’ total number of math errors (out of 75). Using an 85 % accuracy criterion (Turner & Engle, 1989), a subject’s OSPAN score should be considered valid only if he or she made fewer than 12 total math errors. The antisaccade column refers to proportion accuracy in the antisaccade task. In the antisaccade task, subjects were informed that their task was to look away from a flashed star (*) in order to identify a target (O or Q) briefly flashed on the opposite side of the screen from the star and quickly covered by a pattern mask (#). Subjects completed a total of 56 trials: 48 experimental trials and 8 practice trials. Following the Hutchison (2007) procedure, we performed a principal components analysis (PCA) to extract the common variance among the tasks. This common variance should more accurately reflect a person’s degree of AC than should performance in any one task alone (see Conway, Kane, & Engle, 2003, for a discussion). In the SPP, average z-score performance across the two Stroop measures (RT and error) were combined, allowing the three tasks to each provide a single score to the PCA. Consistent with Hutchison (2007), there was only a single significant component to emerge from the PCA that explained 48 % and 46 % of the overall variance across attention tasks among those subjects in the lexical decision and naming studies, respectively. This component contained positive loadings for antisaccade and ospan and a negative loading for Stroop (for which high scores represent less AC). Each subject’s PCA score is provided in the Atten Ctrl column under the Subjects tab.
Constraining your search through SPP
In addition to the ability to immediately view subjects’ and targets’ characteristics and performance (described above), researchers can constrain their searches by typing in particular items, characteristics, or ranges of performance. In this section, we will describe how to use the search engine available at the SPP Web site. There are literally millions of possible requests. Thus, in modeling the ELP user’s guide, we will provide a few specific examples of available queries. However, direct exploration of the Web site and search engine is encouraged. Although there is already a range of searchable variables available, we plan to add many more in the future.
Item-based searches
When searching the database by items, one can limit the search on the basis of target characteristics, prime characteristics, or SPP performance. The search variables that are currently available for each of these types of searches are presented below.
Target searches
Currently searchable target variables within the Targets tab include the targets themselves, length, orthographic neighborhood, LogHal frequency, part of speech, and ELP performance. For instance, one could generate only high-frequency noun targets that received relatively fast lexical decisions in the ELP. The instructions for doing so are provided below, and this example provides 96 targets.
-
a.
Go to the SPP homepage and click on “Search”; then click “Lexical Decision Data” and “By item” (see Fig. 2).
-
b.
Within the “LogHal” minimum and maximum boxes in the top panel, type in relatively high values such as “12” to “16” (note, the highest frequency target, in, has a 15.9 LogHal).
-
c.
Within the “POS” box in the top right panel, type in “NN” for noun.
-
d.
Within the “ELP RT” box in the top right panel, relatively fast RT values such as “400” to “650.”
-
e.
Click the “search” button.
Prime–target relational searches
The database was created specifically for prime–target relational searches. The SPP Web site will display the first 100 rows of any search and allow researchers to download a comma-delineated Excel spreadsheet containing the entire output. Specifically, researchers can select prime–target pairs on the basis of prime characteristics (similar to the target search example above), type of semantic relation, forward or backward associative strength, forward associative rank, LSA similarity, or the size of SPP priming itself. For instance, one could generate only first-associate antonym pairs that have a forward associative strength of at least .40. The instructions for doing so are provided below, and this example provides 95 pairs.
-
a.
Go to the SPP homepage and click on “Search”; then click “Lexical Decision Data” and “By item.”
-
b.
Click the Assoc Related search tab and the Assoc Related display tab (see Fig. 4).
-
c.
Within the “FAS” minimum and maximum boxes in the top panel, type in the values “.4” for the minimum and leave the maximum box blank.
-
d.
Within the “Relation 1” box in the bottom right panel, type in “antonym.”
-
e.
Click the “search” button.
-
f.
Click the “download 95 rows” box at the bottom to receive an Excel spreadsheet of the data.
As another example, one could generate first-associate synonyms that produce at least 40 ms of priming at the short SOA. The instructions for doing so are provided below, and this example provides 211 pairs.
-
a.
Go to the SPP homepage and click on “Search”; then click “Lexical Decision Data” and “By item.”
-
b.
Click the Assoc Related search tab and the Assoc Related display tab (see Fig. 4).
-
c.
Within the “Relation 1” box in the bottom right panel, type in “synonym.”
-
d.
Under “Priming Effects” on the right, type “40” to “300” for minimum and maximum on the “200 ms RT” boxes.
-
e.
Click the “search” button.
In the case of synonym priming at the 200-ms SOA, 300 ms was selected as the maximum priming effect because the largest priming effect was 262.29 ms for the pair shove–push. Note also that the 200-ms box on the right is highlighted. If researchers instead wanted to search priming effects at the 1,200-ms SOA, they would simply click the highlighted box to change the 200-ms option to 1,200 ms.
Discussion
The Semantic Priming Project (SPP) is a Web-based repository encompassing descriptive and behavioral measures for 1,661 target words that each followed four different types of prime words: first-associate related, first-associate unrelated, other-associate related, and other-associate unrelated. Descriptions of these prime words, as well as descriptions of the associative and semantic similarity between the prime and target words, are also provided. In the present article, we have presented the methods used to collect the data, defined the variables in the database, and illustrated how researchers can use the search engine.
One potential concern researchers may have concerning this database is that testing priming for 831 items per session is considerably longer than most priming studies, which typically test from 100 to 200 items. This length could perhaps disrupt subjects’ priming effects due to boredom or fatigue. However, an analysis of priming effects across subjects revealed that priming effects were not affected by block (first 400 trials vs. last 400 trials) in either the lexical decision task (priming = 19 and 18 ms for first vs. last block, respectively, F < 1) or the pronunciation task (priming = 6 and 6 ms for first vs. last block, respectively, F < 1).
Another potential concern is that the present priming effects are smaller than one might expect from previous studies. For instance, in the Hutchison et al. (2008) regression analysis, our lexical decision priming effects from young adults on 300 first associates were 42 ms at a 200-ms SOA and 60 ms at the 1,200-ms SOA. However, in the present study, first-associate priming effects were 26 and 20 ms at the 200- and 1,200-ms SOAs, respectively. Note, in addition, that these differences remain even when examining only the 283 first-associate pairs that are common between the two studies (43- and 61-ms priming for Hutchison et al. (2008) and 25- and 23-ms priming in SPP for short and long SOAs, respectively) and when z-score priming effects are examined (.37 and .44 z-score priming for Hutchison et al. and .18 and .16 z-score priming in SPP for short and long SOAs, respectively). We are unsure why this difference exists. However, one possibility is that the items in the present database represent a range of different types of associations and semantic relations and only half of the word target trials contained a first associate, whereas all the related trials in Hutchison et al. (2008) contained strong associates. Indeed, one might argue that the size of the present priming effects better reflects the natural range of associations across words with the lexical and semantic systems.
Additional measures
Because the SPP is intended to be a constantly evolving interactive tool for researchers, we anticipate that many additional variables will be included in the future. Here, we review a set of measures that are available for inclusion in the database. For example, additional lexical characteristics for these items are already contained in the ELP database, such as Levenshtein distance measures for Ortho N (Yarkoni, Balota, & Yap, 2008) and phonological neighborhood estimates (Yates, 2005), as well as age of acquisition (Kuperman, Stadthagen-Gonzalez, & Brysbaert, in press). In addition, semantic variables such as imageability, concreteness, contextual diversity, and semantic neighborhood density (Shaoul & Westbury, 2010) will also be included.
For prime–target relatedness measures, we have completed norming all of our related and unrelated prime–target pairs for semantic feature overlap (Buchanan, Holmes, Teasley, & Hutchison, in press). These norms used the McRae, De Sa, and Seidenberg (1997) feature production and cosine computation procedures to norm 1,808 words, a majority of which were targets and primes used in the current SPP. In their database, Buchanan et al. calculated a cosine value for each combination of word pairings. Cosine was calculated by summing the multiplication of matching feature frequencies divided by the products of the vector length of each word (see Buchanan et al., in press, for more details). In addition to feature overlap, we have obtained prime–target contextual similarity estimates [random permutations (RPs), pointwise mutual information (PMI), simple PMI, cosines of similarity, and number of intervening neighbors] from the BEAGLE model (Jones, Kintsch, & Mewhort, 2006).
Three other measures available for prime–target relatedness are Google hits, WordNet similarity, and the Wu and Barsalou (2009) relation taxonomies. Google hits provide a measure of the local co-occurrence of word pairs and are easy to obtain by entering the prime–target pair in quotes in the search box (e.g., “beaver dam”). Putting the pair in quotes takes word order into account such that “beaver dam” has many more Google hits than “dam beaver.” WordNet (Fellbaum, 1998) is an electronic dictionary with the definitions of 155,327 words organized in a hierarchical network structure. Measures of semantic similarity from WordNet are derived from either the overlap in two words’ definitions or the co-occurrence of the words in natural language. Finally, Wu and Barsalou published relational taxonomies for categorizing various relation types (e.g., synonymy, antonymy, taxonomy, entity, etc.). These relational taxonomies have been used successfully in recent studies (Brainard, Yang, Reyna, Howe, & Mills, 2008; Jones, & Golonka, 2012) and would provide an alternative to the present Hutchison (2003) categories.
Finally, additional measures will be available in the future that may be of great benefit to psycholinguistic researchers. For example, De Deyne and colleagues are currently expanding upon their Dutch word association project (De Deyne, Navarro, & Storms, 2012) by collecting new word associates in English using Internet crowd-sourced data collected on their Web site http://www.smallworldofwords.com/. This project has each subject list three associates per cue word (as compared with only one per cue by Nelson et al., 1999). To date, they have collected nearly 2 million responses to 7,000 target words. Thus, these norms are likely to greatly exceed those of Nelson et al.
Potential uses for the Web site
We anticipate that this database will be a valuable tool for researchers developing theories of semantic priming and models of semantic memory. Of primary importance is identifying variables crucial for predicting priming across the database. For instance, in which ways do primary word association, number of overlapping features, relation type, or similarity in global co-occurrence predict priming? Of course a more interesting question concerns possible interactions between predictor variables. For instance, perhaps co-occurrence or word order information has a larger influence on priming for certain types of relations? Similarly, perhaps feature overlap and/or global co-occurrence produce larger influences on priming when normative association strength (or associative rank order) is low, or vice versa. Perhaps such effects are further modulated by SOA, attentional control, vocabulary, or some combination of these.
Jones and Golonka (2012) recently performed such a test using the SPP database. They examined priming for three relation types: integrative pairs (e.g., cherry–pit), thematic pairs (e.g., rooster–farm), and taxonomic pairs (e.g., cougar–lion). These pairs were derived from the SPP phrasal associate, script, and category relation pairs, respectively. Jones and Golonka chose “other-associate” pairs, rather than first-associate pairs, to reduce forward association from primes to targets. They first (Experiment 1) investigated these pairs in their degree of local co-occurrence (i.e., typically part of same phrase and assessed by Google hits) or global co-occurrence (i.e., similarity in overall linguistic contexts and assessed by LSA) and then (Experiment 2) examined SPP target RT and priming effects from these relation types across our 200- and 1,200-ms conditions. As was predicted, integrative (phrasal associate) items had the highest local co-occurrence but the lowest global co-occurrence. Despite these differences in level of co-occurrence, they found no differences between relation types in their priming effects across SOAs. Both of these findings were then replicated in their lab using a different set of items in which the same target items were paired with different primes to create the three different relation types.
An additional use for the SPP is to create better controlled studies. For instance, when priming is predicted on the basis of relational variables, it may be critical to first use the SPP database to estimate and extract out predicted variance in priming on the basis of the prime and target lexical (and sublexical) characteristics, since these characteristics have been shown to predict priming (Hutchison et al., 2008) and share variance with relational variables. For instance, forward versus backward association strength is correlated with prime and target frequency such that pairs with high frequency targets (e.g., water) tend to have higher FAS (e.g., bay–water) and a larger cue fan-in (i.e., water is produced as a response to many cues in word association norms), whereas pairs with high-frequency primes tend to have higher BAS (e.g., money–cash), fan-out, and number of intervening neighbors. Thus, priming variance predicted by BAS or FAS may simply reflect one of these other variables if these variables are not first controlled, through either item selection or statistically through ANCOVA. The Jones and Golonka (2012) study again serves as an excellent example. They used the SPP to identify prime and target differences in lexical characteristics previously found to predict priming (Hutchison et al., 2008). In fact, the item sets differed in both target frequency and baseline ELP RT. They then used these two variables as covariates in their analyses.
This project should also serve as a tool for researchers interested in generating hypotheses for future factorial experiments of semantic priming and actually conducting virtual experiments by accessing the database. Explorations within the database should provide ample opportunity to discover important relations between predictor variables and priming both at the subject level (e.g., reading comprehension and priming) and at the item level (e.g., differential predictability of feature overlap for category members vs. phrasal associates). Alternatively, one may be interested in relationships between the predictors themselves at either the subject level (e.g., reading comprehension and attentional control; see McVay & Kane, 2012, for a recent examination of this relation) or the item level (e.g., LSA vs. association strength or BEAGLE estimates).
Researchers from other areas within cognitive psychology and cognitive neuroscience (memory, perception, neuroimaging, neuropsychology) will be able to use this database to select items that produce large, medium, or small priming effects and are equated along a number of relevant dimensions. Finally, researchers interested in examining populations such as children, older adults, or individuals with aphasia, schizophrenia, or Alzheimer’s disease could use patterns of priming across variables in this database as a control to test predicted deviations in their population.
References
Anaki, D., & Henik, A. (2003). Is there a “strength effect” in automatic semantic priming? Memory & Cognition, 31, 262–272. doi:10.3758/BF03194385
Balota, D. A. (1983). Automatic semantic activation and episodic memory encoding. Journal of Verbal Learning and Verbal Behavior, 2, 88–104. doi:10.1016/S0022-5371(83)80008-5
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H., & Yap, M. J. (2004). Visual word recognition of single-syllable words. Journal of Experimental Psychology. General, 133(2), 283–316. doi:10.1037/0096-3445.133.2.283
Balota, D. A., & Duchek, J. M. (1988). Age-related differences in lexical access, spreading activation, and simple pronunciation. Psychology and Aging, 3, 84–93. doi:10.1037/0882-7974.3.1.84
Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftus, B., Neely, J. H., Nelson, D. L., Simpson, G. B., & Treiman, R. (2007). The English lexicon project: A user’s guide. Behavior Research Methods, 39(3), 445–459. doi:10.3758/BF03193014
Balota, D. A., Yap, M. J., Cortese, M. J., & Watson, J. M. (2008). Beyond mean response latency: Response time distributional analyses of semantic priming. Journal of Memory and Language, 59, 495–523. doi:10.1016/j.jml.2007.10.004
Balota, D. A., Yap, M. J., Hutchison, K. A., & Cortese, M. J. (2012). Megastudies: Large scale analysis of lexical processes. In J. S. Adelman (Ed.), Visual Word Recognition Vol. 1: Models and Methods, Orthography and Phonology. Hove, England: Psychology Press.
Becker, C. A. (1979). Semantic context and word frequency effects in visual word recognition. Journal of Experimental Psychology. Human Perception and Performance, 5, 252–259. doi:10.1037/0096-1523.5.2.252
Becker, C. A. (1980). Semantic context effects in visual word recognition: An analysis of semantic strategies. Memory and Cognition, 8, 493–512. doi:10.3758/BF03213769
Brainerd, C. J., Yang, Y., Reyna, V. F., Howe, M. L., & Mills, B. A. (2008). Semantic processing in “associative” false memory. Psychonomic Bulletin & Review, 15, 1035–1053. doi:10.3758/PBR.15.6.1035
Brysbaert, M., & New, B. (2009). Moving beyond Kŭcera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, Instruments, & Computers, 41, 977–990. doi:10.3758/BRM.41.4.977
Buchanan, E. M., Holmes, J. L., Teasley, M. L., & Hutchison, K. A. (in press). English semantic word-pair norms and a searchable Web portal for experimental stimulus creation. Behavior Research Methods. doi:10.3758/s13428-012-0284-z
Bueno, S., & Frenk-Mastre, C. (2008). The activation of semantic memory: Effects of prime exposure, prime-target relationship, and task demands. Memory & Cognition, 36, 882–898. doi:10.3758/MC.36.4.882
Chiarello, C., Burgess, C., Richards, L., & Pollock, A. (1990). Semantic and associative priming in the cerebral hemispheres: Some words do, some words don’t… sometimes, some places. Brain and Language, 38, 75–104. doi:10.1016/0093-934X(90)90103-N
Cohen, J., Cohen, P., West, S. G., & Aiken, L. S. (2003). Applied multiple regression/correlation analysis for the behavioral sciences (3rd ed.). Mahwah, NJ: Lawrence Erlbaum Associates.
Coltheart, M., Davelaar, E., Jonasson, J., & Besner, D. (1977). Access to the internal lexicon. In S. Dornic (Ed.), Attention and performance VI (pp. 535–555). Hillsdale, NJ: Erlbaum.
Conway, A. R. A., Kane, M. J., & Engle, R. W. (2003). Working memory capacity and its relation to general intelligence. Trends in Cognitive Sciences, 7(12), 547–552. doi:10.1016/j.tics.2003.10.005
Cortese, M. J., Simpson, G. B., & Woolsey, S. (1997). Effects of association and imageability on phonological mapping. Psychonomic Bulletin & Review, 4, 226–231. doi:10.3758/BF03209397
Cutler, A. (1981). Making up materials is a confounded nuisance, or: Will we be able to run any psycholinguistic studies at all in 1990? Cognition, 10, 65–70. doi:10.1016/0010-0277(81)90026-3
De Deyne, S., Navarro, D., & Storms, G. (2012). Better explanations of lexical and semantic cognition using networks derived from continued rather than single word associations. Behavior Research Methods. doi:10.3758/s13428-012-0260-7
Faust, M. E., Balota, D. A., Spieler, D. H., & Ferraro, F. R. (1999). Individual differences in information-processing rate and amount: Implications for group differences in response latency. Psychological Bulletin, 125, 777–799. doi:10.1037/0033-2909.125.6.777
Fellbaum, C. (1998). WordNet: An electronic lexical database. Cambridge, MA: MIT Press.
Ferrand, L., & New, B. (2003). Semantic and associative priming in the mental lexicon. In P. Bonin (Ed.), Mental lexicon: Some words to talk about words (pp. 25–43). Hauppage, NY: Nova Science Publishers.
Ferrand, L., New, B., Brysbaert, M., Keuleers, E., Bonin, P., Méot, A., Augustinova, M., & Pallier, C. (2010). The French Lexicon Project: Lexical decision data for 38,840 French words and 38,840 pseudowords. Behavior Research Methods, 42, 488–496. doi:10.3758/BRM.42.2.488
Hodgson, J. M. (1991). Informational constraints on pre-lexical priming. Language & Cognitive Processes, 6, 169–205. doi:10.1080/01690969108406942
Horne, J. A., & Ostberg. (1976). A self-assessment questionnaire to determine morningness-eveningness in human circadian rhythms. International Journal of Chronobiology, 4, 97–110.
Hutchison, K. A. (2003). Is semantic priming due to association strength or feature overlap? A micro-analytic review. Psychonomic Bulletin and Review, 10(4), 785–813. doi:10.3758/BF03196544
Hutchison, K. A. (2007). Attentional control and the relatedness proportion effect in semantic priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33(4), 645–662. doi:10.1037/0278-7393.33.4.645
Hutchison, K. A., Balota, D. A., Cortese, M., & Watson, J. M. (2008). Predicting semantic priming at the item-level. Quarterly Journal of Experimental Psychology, 61(7), 1036–1066. doi:10.1080/17470210701438111
Hutchison, K. A., Neely, J. H., & Johnson, J. D. (2001). With great expectations, can two “wrongs” prime a “right”? Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 1451–1463. doi:10.1037/0278-7393.27.6.1451
Jones, L. L., & Golonka, S. (2012). Different influences on lexical priming for integrative, thematic, and taxonomic relations. Frontiers in Human Neuroscience, 6, 1–17. doi:10.3389/fnhum.2012.00205
Jones, M. N., Kintsch, W., & Mewhort, D. J. K. (2006). High-dimensional semantic space accounts of priming. Journal of Memory and Language, 55, 534–552. doi:10.1016/j.jml.2006.07.003
Kahan, T. A., Neely, J. H., & Forsythe, W. J. (1999). Dissociated backward priming effects in lexical decision and pronunciation tasks. Psychonomic Bulletin and Review, 6, 105–110. doi:10.3758/BF03210816
Keuleers, E., Diependaele, K., & Brysbaert, M. (2010). Practice effects in large-scale visual word recognition studies. A lexical decision study on 14000 Dutch mono- and disyllabic words and nonwords. Frontiers in Language Sciences, Psychology, 1, 174. doi:10.3389/fpsyg.2010.00174
Keuleers, E., Lacey, P., Rastle, K., & Brysbaert, M. (2012). The British Lexicon Project: Lexical decision data for 28,730 monosyllabic and disyllabic English words. Behavior Research Methods, 44, 287–304. doi:10.3758/s13428-011-0118-4
Kiefer, M., & Martens, U. (2010). Attentional sensitization of unconscious cognition: Task sets modulate subsequent masked semantic priming. Journal of Experimental Psychology. General, 139, 464–489. doi:10.1037/a0019561
Kuperman, V., Stadthagen-Gonzalez, & Brysbaert, M. (in press). Age-of-acquisition ratings for 30,000 English words. Behavior Research Methods.
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104, 211–240. doi:10.1037/0033-295X.104.2.211
Lund, K., & Burgess, C. (1996). Producing high-dimensional semantic spaces from lexical co-occurrences. Behavior Research Methods, Instruments, & Computers, 28, 203–208. doi:10.3758/BF03204766
McNamara, T. P. (2005). Semantic Priming: Perspectives from memory and word recognition. New York, NY: Psychology Press.
McKoon, G., & Ratcliff, R. (1995). Conceptual combinations and relational contexts in free association and in priming in lexical decision and naming. Psychonomic Bulletin & Review, 2, 527–533. doi:10.3758/BF03210988
McRae, K., De Sa, V. R., & Seidenberg, M. S. (1997). On the nature and scope of featural representations of word meaning. Journal of Experimental Psychology. General, 126, 99–130. doi:10.1037/0096-3445.126.2.99
McVay, J. C., & Kane, M. J. (2012). Why does working memory capacity predict variation in reading comprehension? On the influence of mind wandering and executive attention. Journal of Experimental Psychology. General, 141, 302–320. doi:10.1037/a0025250
Morgan, C. J. A., Rothwell, E., Atkinson, H., Mason, O., & Curran, H. V. (2010). Hyper-priming in cannabis users: A naturalistic study of the effects of cannabis on semantic memory function. Psychiatry Research, 176, 213–218. doi:10.1016/j.psychres.2008.09.002
Moritz, S., Woodward, T. S., Küppers, D., Lausen, A., & Schickel, M. (2003). Increased automatic spread of activation in thought-disordered schizophrenic patients. Schizophrenia Research, 59, 2–3. doi:10.1016/S0920-9964(01)00337-1
Moss, H. E., Ostrin, R. K., Tyler, L. K., & Marslen-Wilson, W. D. (1995). Accessing different types of lexical semantic information: Evidence from priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 863–883. doi:10.1037/0278-7393.21.4.863
Neely, J. H. (1991). Semantic priming effects in visual word recognition: A selective review of current findings and theories. In D. Besner & G. W. Humphreys (Eds.), Basic processes in reading: Visual word recognition (pp. 264–336). Hillsdale, NJ, USA: Lawrence Erlbaum Associates, Inc.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. (1999). The University of South Florida Word association, rhyme and word fragment norms. http://www.usf.edu/FreeAssociation/
Pecher, D., Zeelenberg, R., & Raaijmakers, J. G. (1998). Does pizza prime coin? Perceptual priming in lexical decision and pronunciation. Journal of Memory and Language, 38, 401–418. doi:10.1006/jmla.1997.2557
Plaut, D. C., & Booth, J. R. (2000). Individual and developmental differences in semantic priming: Empirical and computational support for a single-mechanism account of lexical processing. Psychological Review, 107, 786–823. doi:10.1037/0033-295X.107.4.786
Schneider, W., Eschman, A., & Zuccolotto, A. (2002). E-Prime reference guide. Pittsburgh, PA: Psychology Software Tools.
Shaoul, C., & Westbury, C. (2010). Exploring lexical co-occurrence space using HiDEx. Behavior Research Methods, 42, 393–413.
Spieler, D. H., & Balota, D. A. (1997). Bringing computational models of word naming down to the item level. Psychological Science, 8, 411–416. doi:10.1111/j.1467-9280.1997.tb00453.x
Stanovich, K. E., & West, R. F. (1979). Mechanisms of sentence context effects in reading: Automatic activation and conscious attention. Memory & Cognition, 7, 77–85. doi:10.3758/BF03197588
Stolz, J. A., & Neely, J. H. (1995). When target degradation does and does not enhance semantic context effects in word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(3), 596–611. doi:10.1037/0278-7393.21.3.596
Thomas, M. A., Neely, J. H., & O’Connor, P. (2012). When word identification gets tough, retrospective semantic processing comes to the rescue. Journal of Memory and Language, 66, 623–643. doi:10.1016/j.jml.2012.02.002
Turner, M. L., & Engle, R. W. (1989). Is working memory capacity task dependent? Journal of Memory and Language, 28, 127–154. doi:10.1016/0749-596X(89)90040-5
Unsworth, N., Heitz, R. P., Schrock, J. C., & Engle, R. W. (2005). An automated version of the operation span task. Behavior Research Methods, 37, 498–505.
Williams, J. N. (1996). Is automatic priming semantic? European Journal of Cognitive Psychology, 22, 139–151. doi:10.1080/095414496383121
Woodcock, R. W., McGrew, K. S., & Mather, N. (2001). Woodcock Johnson III tests of cognitive abilities. Rolling Meadows, IL: Riverside Publishing.
Wu, L. L., & Barsalou, L. W. (2009). Perceptual simulation in conceptual combination: evidence from property generation. Acta Psychologia, 132, 173–189.
Yap, M. J., Rickard Liow, S. J., Jalil, S. B., & Faizal, S. S. B. (2010). The Malay lexicon project: A database of lexical statistics for 9,592 words. Behavior Research Methods, 42, 992–1003. doi:10.3758/BRM.42.4.992
Yap, M. J., Tse, C.-S., & Balota, D. A. (2009). Individual differences in the joint effects of semantic priming and word frequency: The role of lexical integrity. Journal of Memory and Language, 61, 303–325. doi:10.1016/j.jml.2009.07.001
Yarkoni, T., Balota, D., & Yap, M. (2008). Moving beyond Coltheart’s N: A new measure of orthographic similarity. Psychonomic Bulletin & Review, 15, 971–979.
Yates, M. (2005). Phonological neighbors speed visual word processing: Evidence from multiple tasks. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 1385–1397.
Author Notes
This work was supported by the National Science Foundation PAC Grant 0517942. We are grateful to Frank Bosco for his help in selecting stimuli for the experiments, to Michael Jones for providing the BEAGLE estimates, and to Amber Ferris, Terry Seader, Margaret Freuen, Shelly Winward, Patrick O’Connor, and Matthew Thomas for their assistance with data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Hutchison, K.A., Balota, D.A., Neely, J.H. et al. The semantic priming project. Behav Res 45, 1099–1114 (2013). https://doi.org/10.3758/s13428-012-0304-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-012-0304-z