
In recent years, business English teaching theories and practitioners in China have been thinking about how to enable students to master business English as a tool of information and communication while learning their major subjects [1]. University business English teachers and researchers have been searching for the best teaching methods and approaches [2]. The traditional teaching model is no longer fully adapted to the modern teaching requirements, and “a national reform of college business English translation is imminent” [3]. The focus has been on the learner-centered model of teaching, which is popular in Europe and US. The traditional teacher-centered teaching model has increasingly shown its limitations, inappropriateness, and lag. Both in China and abroad, the teacher-centered teaching model basically adopts a teaching-oriented teaching method [4, 5, 6, 7, 8, 9]. The theoretical sources of the student-centered teaching model can be summarized as humanistic psychology [10, 11, 12].
In the contemporary landscape of higher education, the fusion of artificial intelligence (AI) and adaptive methodologies represents a pivotal paradigm shift in pedagogical practices, particularly in the realm of business English translation. As globalization continues to shape the interconnectedness of economies and cultures, proficiency in business English translation has emerged as a critical skill for students pursuing careers in international business and commerce. The integration of AI and trend-adaptive approaches into the teaching of business English translation holds the promise of revolutionizing traditional pedagogies, enhancing the effectiveness of instruction, and elevating the overall quality of education.
The impetus for this exploration stems from the recognition that the demands placed on business professionals extend beyond linguistic competence. In an era characterized by rapid technological advancements and dynamic global trends, students need not only linguistic proficiency but also the ability to navigate diverse cultural contexts and industry-specific terminologies. This necessitates a reevaluation and enhancement of the teaching methodologies employed in university business English translation classrooms.
If different students have different communicative purposes, then these communicative purposes should be reflected in the content (what to teach) and the learning process (how to teach) of the course [13, 14, 15]. In addition, the fact that different students have different communicative purposes also promotes a shift in the concept of teaching and learning from the concentration of teachers and textbooks to students, which to some extent reflects the concept of student-centered teaching [16, 17, 18, 19, 20]. As Cook says: “The communicative approach focuses on the interaction of two people in a situation, what Halliday (1975) calls the ’interpersonal’ function of language. Instead of the college business English translation ruling the classroom, controlling and directing the students at all times, the students are given free rein to talk in pairs or small groups, learning by doing; the students are no longer expected to produce completely error-free discourse; instead, they can use whatever forms and strategies they think will solve the problem, and the teacher can provide some feedback and correction. correction, which are also important responsibilities of the teacher in the classroom [21, 22, 23, 24, 25].
This paper endeavors to explore and evaluate the impact of the amalgamation of artificial intelligence and trend-adaptive methodologies on the quality of business English translation classroom teaching in university settings. The overarching goal is to assess how this innovative approach enhances linguistic proficiency, cultural awareness, and industry-specific competence among students. Through a comprehensive literature review, empirical analysis, and case studies, we aim to provide insights into the efficacy of this pedagogical model and its potential implications for the future of language education.
Domestically, in terms of voice pronunciation quality evaluation, the Institute of Automation of the Chinese Academy of Sciences, the Chinese Academy of Social Sciences Institute of Linguistics, University of Science and Technology of China, Tsinghua University, Microsoft Asia Research Institute, and Anhui Sci-Tech Co. Ltd. have been conducting related researches and have achieved corresponding results. Qingfeng et al. [9] added rhyme factors to the original monophonic and trisyllabic models to construct a rhyme modeling approach, thus improving the performance of pronunciation quality evaluation. The researchers in [10, 11, 12] solved the confusion degree problem between the probability space and the target pronunciation acoustic model by studying the phoneme-related frame-regularized logarithmic posterior probability and its transformation, which led to a significant improvement of pronunciation quality evaluation performance. Chen et al. [13] proposed a new algorithm introducing GMM-UBM model in phoneme articulation quality evaluation, constructing phoneme-independent feature distribution model, and scoring better than other algorithms, which are close to the scoring correlation of experts.
Uraikul et al. [14] proposed a new computational strategy to apply linguistic rules in the log posterior probability algorithm, and its correlation between machine scoring and human scoring reached 0.795, which is 9% better than the original algorithm. Wang et al. [15] proposed a comprehensive pronunciation quality evaluation algorithm based on MFCC and LSP parameters and an objective scoring algorithm. Kessler [16] proposed a new pronunciation quality evaluation algorithm-PASS (phone-based automatic score for l2 speech quality), and successfully applied it to the call system for English learning people- -the interactive language learning system of Tsinghua University. Devedz̧ić [17] conducted a comprehensive evaluation study of pronunciation quality by comparing the pitch, rate, stress, rhythm, and intonation of the utterances to be evaluated with the standard utterances of the corpus, and achieved better results. In contrast, because the theoretical analysis of ANN is more difficult and cannot explain the temporal dynamic characteristics of speech signal well; it is easier to overfit when training the learning network model, more difficult to adjust the model parameters, and requires a lot of experience and skills, and the speed is slower, and the effect is not better than other methods when there are fewer levels (less than or equal to 3) [18, 19, 20], so the shallow artificial neural network did not make a big breakthrough in this period and development [21].
One major challenge in current research lies in achieving scalability and efficiency in the evaluation process. Manual grading methods, while providing detailed feedback, are resource-intensive and struggle to handle large volumes of translation assignments. Existing approaches often fall short in providing a holistic representation of linguistic and contextual features. The complexity of business English translation necessitates a more nuanced feature extraction process to capture the intricacies of translation tasks.
The proposed research seeks to address these identified gaps by introducing the Intelligent College Business English Translation Evaluation Framework. By leveraging AI and trend-adaptive strategies, the framework aims to enhance scalability, provide comprehensive feature representation, enable real-time and dynamic evaluation, and facilitate personalized learning experiences. The review underscores the significance of such an approach in advancing the quality of business English translation education in university classrooms.
The contributions can be outlined as follows:
The introduction of the Intelligent College Business English Translation Evaluation Framework represents a pioneering approach to assessing the quality of business English translation in a university setting. By combining artificial intelligence techniques and adaptive methodologies, this framework offers a novel perspective on evaluating student performance in business English translation.
The proposed framework employs a comprehensive set of feature extraction techniques, including word2vec, paragraph2vec, pos2vec, and LDA. This multifaceted approach ensures that various linguistic and contextual aspects are considered, enhancing the depth and richness of the evaluation process. The integration of these features into a unified vector space enables a holistic representation of the complexity inherent in business English translation.
The utilization of a normalized scoring model, implemented through the XGBoost regression algorithm, contributes to the accuracy and reliability of the evaluation process. By training the model on integrated feature vectors and normalized scores, the framework accounts for variations in scoring patterns, providing a more robust assessment mechanism.
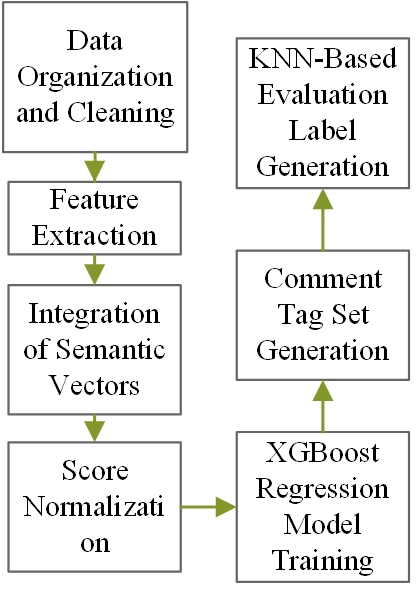
The evaluation framework begins by organizing N documents, employing a data cleaning module to ensure training corpus completeness and coding consistency. For each college business English translation, feature vectors (word2vec, paragraph2vec, pos2vec, LDA) are extracted. These semantic vectors are then integrated into 1\(\mathrm{\times}\)M-dimensional vectors, forming an N\(\mathrm{\times}\)M-dimensional space. Scores are normalized, and XGBoost regression is applied for model training. Subsequently, TF-IDF and text rank algorithms generate comprehensive comment tag sets. Using the KNN algorithm, similar translations are identified, facilitating the generation of final evaluation labels for the target translation based on the comprehensive evaluation labels from the training set, as shown in Figure 1.
The core computation principle of Paragraph2vec is the same as that of word2vec, which is based on the MLP model, and the vector of modeling objects is obtained in the process of finding the objective function 1, but the difference lies in the selection of modeling objects. In order to consider more the influence of word order on semantics, paragraph2vec introduces paragraph id, so that each sentence has a unique id, as shown in Figure 2. Given the paragraph id, the probability of four words occurring in the context is counted, i.e., the position of the sentence is also taken as an important feature to record the implied semantics between paragraphs.
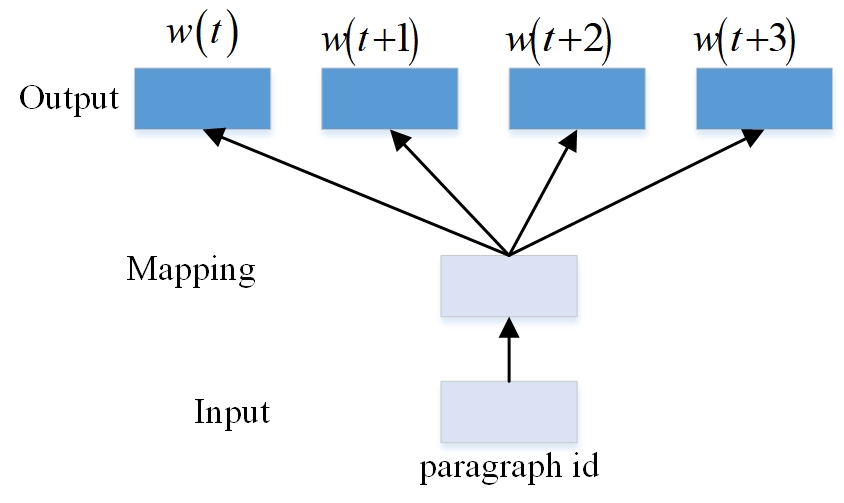
In the training step, only the feature of id, i.e., paragraph id, \(w_{1} ,w_{2} ,…,w_{T}\), is added in front of the word sequence of Eq. 1, and the subsequent parameter solving steps remain unchanged.
The LDA model is a generative topic model, which is a three-layer Bayesian probabilistic model consisting of words, topics, and documents, and is centered on how to calculate the distribution of topic variables (i.e., hidden variables) for a given document [18]. The estimation process of the parameters is shown in Figure 3.
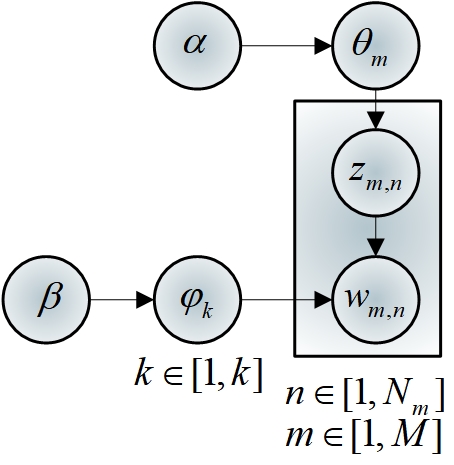
In Figure 3, the parameters satisfy each other: \[\begin{aligned} \label{GrindEQ__1_} p(w\alpha ,\beta )&=\int p (\theta \alpha )\left(\prod _{n=1}^{N}p \left(w_{n} \theta ,\beta \right)\right){\rm d}\theta \end{aligned}\] \[\begin{aligned} =\int p (\theta \alpha )\left(\prod _{n=1}^{N}\sum _{z_{n} }p \left(z_{n} \theta \right)p\left(w_{n} z_{n} ,\beta \right)\right){\rm d}\theta \end{aligned}\tag{1}\] \[\begin{aligned} =\frac{\Gamma \left(\sum _{i}\alpha _{i} \right)}{\prod _{i}\Gamma \left(\alpha _{i} \right)} \int \left(\prod _{i=1}^{k}\theta _{i}^{\alpha _{i} -1} \right) \left(\prod _{n=1}^{N}\sum _{i=1}^{k}\prod _{j=1}^{V}\left(\theta _{i} \beta _{ij} \right)^{w_{n}^{j} } \right){\rm d}\theta , \end{aligned}\] where, \[\label{GrindEQ__2_}\tag{2} p(\theta \alpha )=\frac{\Gamma \left(\sum _{i}\alpha _{i} \right)}{\prod \Gamma \left(\alpha _{i} \right)} \theta _{1}^{\alpha _{1} -1} \cdots \theta _{k}^{\alpha _{k} -1}.\]
Compared with the traditional GBDT (gradient-based decision tree) method, XGBoost has improved both error approximation and numerical optimization, and has become one of the most popular methods in various machine learning-based applications and competitions in recent years. Assume that there are k trees composing the model: \[\label{GrindEQ__3_}\tag{3} \hat{y}_{i} =\sum _{k=1}^{K}f_{k} \left(x_{i} \right),f_{k} \in F.\]
Solve for the objective function of each parameter in the tree: \[\label{e4}\tag{4} {Loss=\sum _{i}l \left(\hat{y}_{i} ,y_{i} \right)+\sum _{k}\Omega \left(f_{k} \right)=} {\sum _{i}\left(y_{i} -\hat{y}_{i} \right)^{2} +\sum _{k}\left(\gamma T+\frac{1}{2} \lambda w^{2} \right) } .\]
Where, \(\Omega \left(f_{k} \right)\) includes two parts: parameters \(\gamma\) Reflect the influence of the number of leaf nodes t on the error; Parameters \(\lambda\) Reflecting the influence of leaf node weight W on the error, L2 regularization is adopted here to prevent over fitting phenomenon due to too many leaf nodes. For the detailed solution process of objective function (5), see [20].
The general idea of the KNN based rubric generation method for college business English translation is as follows: firstly, several typical rubric labels for each college business English translation in the training set are filtered by TF-IDF method and Text Rank method; then, the college business English translation to be evaluated and all college business English translation in the training set are represented by the comprehensive feature vector and the cosine similarity between the college business English translation to be evaluated and each college business English translation in the training set is compared. Finally, the kNN algorithm is selected and the typical rubric labels of the first k college business English translation in the training set with higher similarity to the college business English translation to be evaluated are de-weighted to form the rubric labels of the college business English translation to be evaluated. The steps are as follows:
In order to ensure the accuracy and fairness of the original labels, two teachers were asked to rate each piece of college business English teaching, and the average score of the college business English teaching was obtained by summing up the comments of the two teachers. The comments of the 2 teachers were summed up to obtain a comprehensive comment. The final number of essays in each score range was obtained, as shown in Table 2, with an average of 7.2 comment phrases per college business English teaching essay.
| Theme | Number of compositions |
|---|---|
| online shopping | 191 |
| online learning | 166 |
| Importance of invention | 192 |
| part-time job in college | 178 |
| choice of career | 173 |
| Score range / point | Number of compositions |
|---|---|
| [0,60] | 54 |
| [60,70] | 219 |
| [70,80] | 296 |
| [80,90] | 273 |
| [90,100] | 63 |
According to the technical route in Figure 1, the 900 colleges business English translation items were divided into 5 equal parts (i.e., 180 items each), 4 of which (i.e., 80%) were randomly selected as the training sample and the remaining 1 as the test sample. The evaluation index was obtained each time, and the average of the five times was used as the score. The comparison between the scoring effect of this method and several previous scoring methods is shown in Table 3:
| Scoring method | Mean square error | Pearson correlation coefficient |
|---|---|---|
| Paper method | 10.40 | 0.955 |
| This paper synthesizes eigenvector + SVM | 18.91 | 0.924 |
| This paper synthesizes eigenvector + gbdt | 12.81 | 0.945 |
| Word2vec, LDA+XGBoost | 15.12 | 0.937 |
| Word2vec +XGBoost | 16.18 | 0.933 |
| LDA+XGBoost | 21.91 | 0.909 |
| LDA+SVM | 27.72 | 0.888 |
| One-hot+GBDT | 24.48 | 0.901 |
The comprehensive feature vector of the i-th college business English translation is \(v_{i}^{{\rm all\; }} =\left[v_{{\rm w}2{\rm v}} ,v_{{\rm p}2{\rm v}} ,v_{{\rm pos}2v} ,v_{{\rm LDA}} \right]\), i.e., 1\(\mathrm{\times}\) 270-dimensional vector, for word2vec, paragraph2vec, pos2vec and LDA with 50, 100, 20 and 100 dimensions, respectively. Compared with other methods, this method has the smallest mean square error and the largest Pearson correlation coefficient, which means that this method has the smallest error and the highest correlation with teachers’ ratings.
In the process of rubric generation, the top 5 comprehensive rubric phrases of TF-IDF weight and Text Rank weight are intersected and used as a sequence of comprehensive rubric phrases with k=3 using the KNN algorithm to give the college business English translation rubric to be evaluated. The average accuracy, recall and F-score of the college business English translation rubrics and teacher comments generated by the new method were compared with those of the TF-IDF and Text Rank methods alone, and the results are shown in Figure 4.
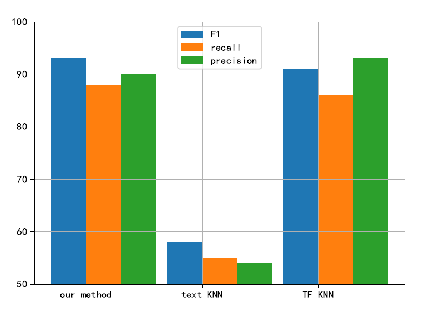
As can be seen from Figure 4, the method in this paper effectively selects typical business English college EFL rubrics by combining the TF-IDF method and the Text Rank method, which has a greater advantage than using a single tag extraction algorithm, and achieves a high level of accuracy (F-score over 0.8) in generating business English college EFL rubrics by using the KNN algorithm. The main rubrics (more than 3 occurrences) were clustered according to 5 rating levels, i.e., [0, 60), [60, 70), [70, 80), [80, 90), [90, 100].
The clustering of students’ college business English translation in different score levels is characterized by a high number of minor errors, poor language flow, and problems with vocabulary use or spelling. There is some overlap in the labels of the comments between adjacent score areas, and the comments vary more across score areas [26].
In conclusion, this study presents a theory of teaching and learning rooted in the framework of second language acquisition. The “student-centered” teaching theory and model proposed herein depart from the traditional “teacher-centered” approach, introducing a paradigm shift while still operating within a teacher-led teaching environment. The core innovation lies in the integration of semantic representation vectors with word vectors in the realm of college business English translation. This research has achieved significant strides in updating the conceptual and theoretical understanding of college business English translation. By combining semantic representation vectors and word vectors, the study enhances the depth of linguistic analysis and provides a robust foundation for reform in business English teaching theory and practice. The focus on a “student-centered” approach fosters an environment conducive to improved learning outcomes.
Looking ahead, the integration of semantic representation vectors and word vectors opens avenues for further research and exploration. Future studies could delve into refining and expanding the proposed model, exploring its applicability in diverse educational settings. Additionally, ongoing efforts should focus on disseminating the insights gained from this research, facilitating the broader adoption of student-centered approaches in language education. The prospect of continued collaboration between language educators, researchers, and policymakers holds the potential for sustained advancements in the field of college business English translation, ultimately benefiting both educators and learners alike.
No funding is available for this research.
The authors declare no conflict of interests.